Ultimo aggiornamento il 17 febbraio 2021
Una previsione dal punto di vista dell’apprendimento automatico è un singolo punto che nasconde l’incertezza di tale previsione.
Gli intervalli di previsione forniscono un modo per quantificare e comunicare l’incertezza in una previsione. Sono diversi dagli intervalli di confidenza che cercano invece di quantificare l’incertezza in un parametro di popolazione come una media o una deviazione standard. Gli intervalli di previsione descrivono l’incertezza per un singolo risultato specifico.
In questo tutorial, scoprirai l’intervallo di previsione e come calcolarlo per un semplice modello di regressione lineare.
Dopo aver completato questo tutorial, saprai:
- Che un intervallo di previsione quantifica l’incertezza di una previsione di un singolo punto.
- Gli intervalli di previsione possono essere stimati analiticamente per modelli semplici, ma sono più impegnativi per i modelli di apprendimento automatico non lineare.
- Come calcolare l’intervallo di previsione per un semplice modello di regressione lineare.
Avvia il tuo progetto con il mio nuovo libro Statistiche per l’apprendimento automatico, inclusi tutorial passo-passo e file di codice sorgente Python per tutti gli esempi.
Iniziamo.
- Aggiornato giugno / 2019: corretto il livello di significatività come frazione delle deviazioni standard.
- Aggiornato Apr / 2020: Errore di battitura fisso nella trama dell’intervallo di previsione.

Intervalli di Previsione per l’Apprendimento automatico
Foto di Jim Bendon, alcuni diritti riservati.
Panoramica del tutorial
Questo tutorial è diviso in 5 parti; sono:
- Cosa c’è di sbagliato in una stima puntuale?
- Che cos’è un intervallo di previsione?
- Come calcolare un intervallo di previsione
- Intervallo di previsione per la regressione lineare
- Esempio di lavoro
Hai bisogno di aiuto con le statistiche per l’apprendimento automatico?
Prendi il mio corso accelerato gratuito di 7 giorni (con codice di esempio).
Fare clic per iscriversi e anche ottenere una versione PDF Ebook gratuito del corso.
Download Your FREE Mini-Course
Why Calculate a Prediction Interval?
In predictive modeling, a prediction or a forecast is a single outcome value given some input variables.
For example:
|
1
|
yhat = model.predict (X)
|
Dove yhat è il risultato stimato o la previsione fatta dal modello addestrato per i dati di input dati X.
Questa è una previsione puntuale.
Per definizione, è una stima o un’approssimazione e contiene qualche incertezza.
L’incertezza deriva dagli errori nel modello stesso e dal rumore nei dati di input. Il modello è un’approssimazione della relazione tra le variabili di input e le variabili di output.
Dato il processo utilizzato per scegliere e sintonizzare il modello, sarà la migliore approssimazione fatta dato informazioni disponibili, ma sarà ancora fare errori. I dati del dominio oscureranno naturalmente la relazione sottostante e sconosciuta tra le variabili di input e output. Questo renderà una sfida per adattarsi al modello, e renderà anche una sfida per un modello di misura per fare previsioni.
Date queste due principali fonti di errore, la loro previsione del punto da un modello predittivo è insufficiente per descrivere la vera incertezza della previsione.
Che cos’è un intervallo di previsione?
Un intervallo di previsione è una quantificazione dell’incertezza su una previsione.
Fornisce un limite superiore e inferiore probabilistico sulla stima di una variabile di risultato.
Un intervallo di previsione per una singola osservazione futura è un intervallo che, con un determinato grado di confidenza, contiene un’osservazione futura selezionata casualmente da una distribuzione.
— Pagina 27, Statistical Intervals: A Guide for Practitioners and Researchers, 2017.
Gli intervalli di previsione sono più comunemente utilizzati quando si effettuano previsioni o previsioni con un modello di regressione, in cui viene prevista una quantità.
Un esempio di presentazione di un intervallo di previsione è il seguente:
Data una previsione di ‘y’ data ‘x’, c’è una probabilità del 95% che l’intervallo da ‘a’ a ‘b’ copra il vero risultato.
L’intervallo di previsione circonda la previsione fatta dal modello e, si spera, copre l’intervallo del risultato reale.
Lo schema seguente aiuta a comprendere visivamente la relazione tra la previsione, l’intervallo di previsione e il risultato effettivo.
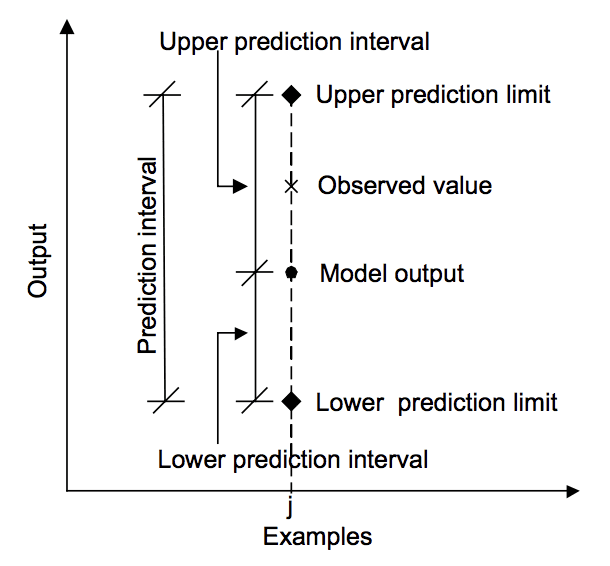
Relazione tra previsione, valore effettivo e intervallo di previsione.
Tratto da “Machine learning approaches for estimation of prediction interval for the model output”, 2006.
Un intervallo di previsione è diverso da un intervallo di confidenza.
Un intervallo di confidenza quantifica l’incertezza su una variabile di popolazione stimata, come la media o la deviazione standard. Mentre un intervallo di previsione quantifica l’incertezza su una singola osservazione stimata dalla popolazione.
Nella modellazione predittiva, un intervallo di confidenza può essere utilizzato per quantificare l’incertezza dell’abilità stimata di un modello, mentre un intervallo di previsione può essere utilizzato per quantificare l’incertezza di una singola previsione.
Un intervallo di previsione è spesso maggiore dell’intervallo di confidenza in quanto deve tenere conto dell’intervallo di confidenza e della varianza nella variabile di output prevista.
Gli intervalli di previsione saranno sempre più ampi degli intervalli di confidenza perché rappresentano l’incertezza associata a e , l’errore irriducibile.
— Pagina 103, Un’introduzione all’apprendimento statistico: con applicazioni in R, 2013.
Come calcolare un intervallo di previsione
Un intervallo di previsione viene calcolato come una combinazione della varianza stimata del modello e della varianza della variabile di risultato.
Gli intervalli di previsione sono facili da descrivere, ma difficili da calcolare nella pratica.
In casi semplici come la regressione lineare, possiamo stimare direttamente l’intervallo di previsione.
Nei casi di algoritmi di regressione non lineare, come le reti neurali artificiali, è molto più impegnativo e richiede la scelta e l’implementazione di tecniche specializzate. Possono essere utilizzate tecniche generali come il metodo di ricampionamento bootstrap, ma sono computazionalmente costose da calcolare.
Il documento “A Comprehensive Review of Neural Network-based Prediction Intervals and New Advances” fornisce uno studio ragionevolmente recente degli intervalli di previsione per modelli non lineari nel contesto delle reti neurali. Il seguente elenco riassume alcuni metodi che possono essere utilizzati per l’incertezza di previsione per modelli di apprendimento automatico non lineari:
- Il metodo Delta, dal campo di regressione non lineare.
- Il metodo bayesiano, dalla modellazione bayesiana e dalla statistica.
- Il metodo di stima della varianza media, utilizzando le statistiche stimate.
- Il metodo Bootstrap, utilizzando il ricampionamento dei dati e lo sviluppo di un insieme di modelli.
Possiamo rendere concreto il calcolo di un intervallo di previsione con un esempio lavorato nella sezione successiva.
Intervallo di previsione per la regressione lineare
Una regressione lineare è un modello che descrive la combinazione lineare di input per calcolare le variabili di output.
For example, an estimated linear regression model may be written as:
|
1
|
yhat = b0 + b1 . x
|
Where yhat is the prediction, b0 and b1 are coefficients of the model estimated from training data and x is the input variable.
Non conosciamo i veri valori dei coefficienti b0 e b1. Inoltre, non conosciamo i veri parametri di popolazione come la media e la deviazione standard per x o y. Tutti questi elementi devono essere stimati, il che introduce incertezza nell’uso del modello per fare previsioni.
Possiamo fare alcune ipotesi, come le distribuzioni di x e y e gli errori di previsione fatti dal modello, chiamati residui, sono gaussiani.
L’intervallo di previsione attorno a yhat può essere calcolato come segue:
|
1
|
yhat +/- z * sigma
|
Where yhat is the predicted value, z is the number of standard deviations from the Gaussian distribution (e.g. 1.96 for a 95% interval) and sigma is the standard deviation of the predicted distribution.
Non sappiamo in pratica. Possiamo calcolare una stima imparziale della deviazione standard prevista come segue (tratto da approcci di apprendimento automatico per la stima dell’intervallo di previsione per l’output del modello):
|
1
|
stdev = sqrt(1 / (N – 2) * e(i)^2 for i to N)
|
Where stdev is an unbiased estimate of the standard deviation for the predicted distribution, n are the total predictions made, and e(i) is the difference between the ith prediction and actual value.
Esempio lavorato
Rendiamo concreto il caso degli intervalli di previsione della regressione lineare con un esempio lavorato.
Per prima cosa, definiamo un semplice set di dati a due variabili in cui la variabile di output (y) dipende dalla variabile di input (x) con qualche rumore gaussiano.
L’esempio seguente definisce il set di dati che useremo per questo esempio.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
# generare variabili correlate
da import numpy media
da import numpy std
from numpy.random import randn
from numpy.random import seed
from matplotlib import pyplot
# seed random number generator
seed(1)
# prepare data
x = 20 * randn(1000) + 100
y = x + (10 * randn(1000) + 50)
# summarize
print(‘x: mean=%.3f stdv=%.3f’ % (mean(x), std(x)))
print(‘y: mean=%.3f stdv=%.3f’ % (mean(y), std(y)))
# plot
pyplot.scatter(x, y)
pyplot.show()
|
Running the example first prints the mean and standard deviations of the two variables.
|
1
2
|
x: mean=100.776 stdv=19.620
y: mean=151.050 stdv=22.358
|
Viene quindi creato un grafico del set di dati.
Possiamo vedere la chiara relazione lineare tra le variabili con la diffusione dei punti evidenziando il rumore o l’errore casuale nella relazione.
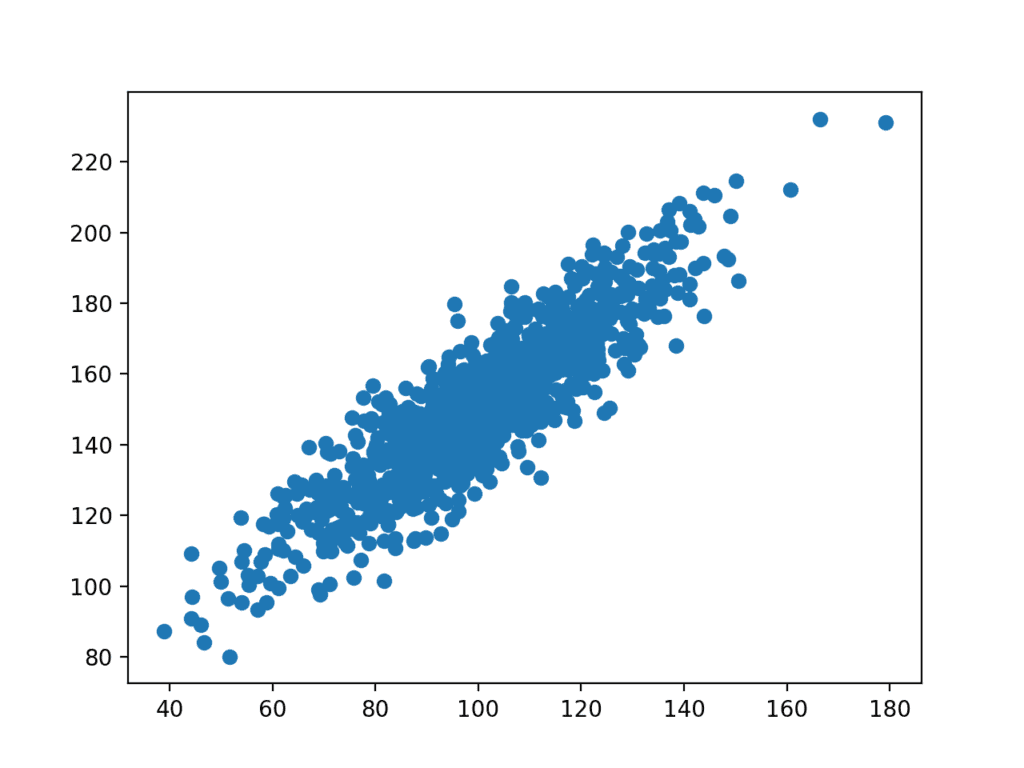
Scatter Plot di variabili correlate
Successivamente, possiamo sviluppare una semplice regressione lineare che data la variabile di input x, predirà la variabile y. Possiamo usare la funzione linregress () SciPy per adattarsi al modello e restituire i coefficienti b0 e b1 per il modello.
|
1
2
|
# fit linear regression model
b1, b0, r_value, p_value, std_err = linregress(x, y)
|
We can use the coefficients to calculate the predicted y values, called yhat, for each of the input variables. The resulting points will form a line that represents the learned relationship.
|
1
2
|
# make prediction
yhat = b0 + b1 * x
|
The complete example is listed below.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
# semplice modello di regressione non lineare
da numpy.random import randn
from numpy.random import seed
from scipy.stats import linregress
from matplotlib import pyplot
# seed random number generator
seed(1)
# prepare data
x = 20 * randn(1000) + 100
y = x + (10 * randn(1000) + 50)
# fit linear regression model
b1, b0, r_value, p_value, std_err = linregress(x, y)
print(‘b0=%.3f, b1=%.3f’ % (b1, b0))
# make prediction
yhat = b0 + b1 * x
# plot data and predictions
pyplot.scatter(x, y)
pyplot.plot(x, yhat, color=’r’)
pyplot.show()
|
Running the example fits the model and prints the coefficients.
|
1
|
b0=1.011, b1=49.117
|
I coefficienti vengono poi utilizzati con ingressi dal set di dati per fare una previsione. Gli input risultanti e i valori y previsti vengono tracciati come una riga sopra il grafico a dispersione per il set di dati.
Possiamo vedere chiaramente che il modello ha appreso la relazione sottostante nel set di dati.
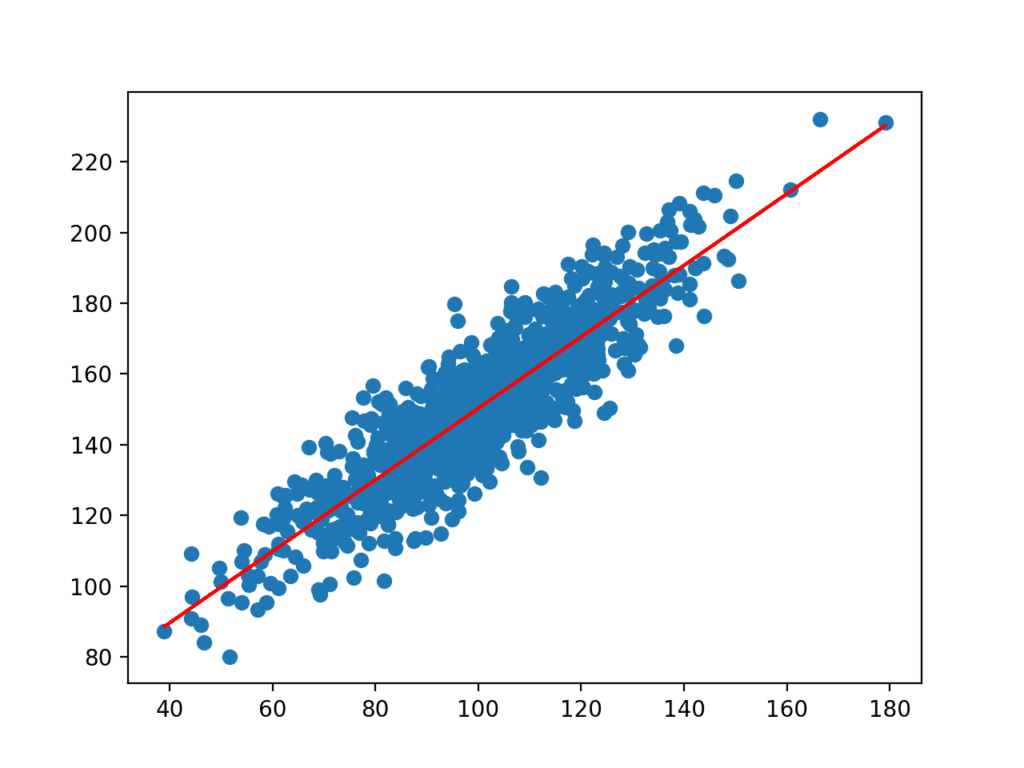
Grafico a dispersione del set di dati con linea per il modello di regressione lineare semplice
Ora siamo pronti a fare una previsione con il nostro modello di regressione lineare semplice e aggiungere un intervallo di previsione.
Ci si adatta il modello come prima. Questa volta prenderemo un campione dal set di dati per dimostrare l’intervallo di previsione. Useremo l’input per effettuare una previsione, calcolare l’intervallo di previsione per la previsione e confrontare la previsione e l’intervallo con il valore atteso noto.
Per prima cosa, definiamo i valori di input, previsione e attesi.
|
1
2
3
|
x_in = x
y_out = y
yhat_out = yhat
|
a quel punto, si può stimare la standard curvatura nella previsione di direzione.
|
1
|
SE = sqrt(1 / (N – 2) * e(i)^2 for i to N)
|
We can calculate this directly using the NumPy arrays as follows:
|
1
2
3
|
# estimate stdev of yhat
sum_errs = arraysum((y – yhat)**2)
stdev = sqrt(1/(len(y)-2) * sum_errs)
|
Next, we can calculate the prediction interval for our chosen input:
|
1
|
interval = z . stdev
|
We will use the significance level of 95%, which is 1.96 standard deviations.
Once the interval is calculated, we can summarize the bounds on the prediction to the user.
|
1
2
3
|
# calculate prediction interval
interval = 1.96 * stdev
lower, upper = yhat_out – interval, yhat_out + interval
|
We can tie all of this together. The complete example is listed below.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
|
# linear regression prediction with prediction interval
from numpy.random import randn
from numpy.random import seed
from numpy import power
from numpy import sqrt
from numpy import mean
from numpy import std
from numpy import sum as arraysum
from scipy.statistiche importazione linregress
da matplotlib importazione pyplot
# seme generatore di numeri casuali
seme(1)
# preparare i dati
x = 20 * randn(1000) + 100
y = x + (10 * randn(1000) + 50)
# fit non lineare, il modello di regressione
b1, b0, r_value, p_value, std_err = linregress(x, y)
# mark previsioni
yhat = b0 + b1 * x
# define nuovi input, valore atteso e la previsione
x_in = x
y_out = y
yhat_out = yhat
# stima stdev di quello
sum_errs = arraysum ((y-yhat) * * 2)
stdev = sqrt(1/(len(y) -2) * sum_errs)
# calcola intervallo di previsione
interval = 1.96 * stdev
print(‘Intervallo di previsione: %.3f ‘ % interval)
lower, upper = yhat_out – interval, yhat_out + interval
print(‘95%% di probabilità che il valore vero sia compreso tra %.3f e %.3f ‘ % (inferiore, superiore))
stampa (‘Valore vero:%.3f ‘ % y_out)
# set di dati di trama e previsione con intervallo
pyplot.scatter (x, y)
pyplot.plot (x, yhat, color=’red’)
pyplot.errorbar (x_in, yhat_out, yerr = intervallo, color = ‘nero’, fmt=’ o’)
pyplot.show()
|
Eseguendo l’esempio stima la deviazione standard yhat e quindi calcola l’intervallo di previsione.
Una volta calcolato, l’intervallo di previsione viene presentato all’utente per la variabile di input specificata. Poiché abbiamo inventato questo esempio, conosciamo il vero risultato, che mostriamo anche. Possiamo vedere che in questo caso, l’intervallo di previsione del 95% copre il vero valore atteso.
|
1
2
3
|
Prediction Interval: 20.204
95% likelihood that the true value is between 160.750 and 201.159
True value: 183.124
|
Viene anche creato un grafico che mostra il set di dati non elaborato come grafico a dispersione, le previsioni per il set di dati come linea rossa e l’intervallo di previsione e previsione rispettivamente come punto e linea neri.
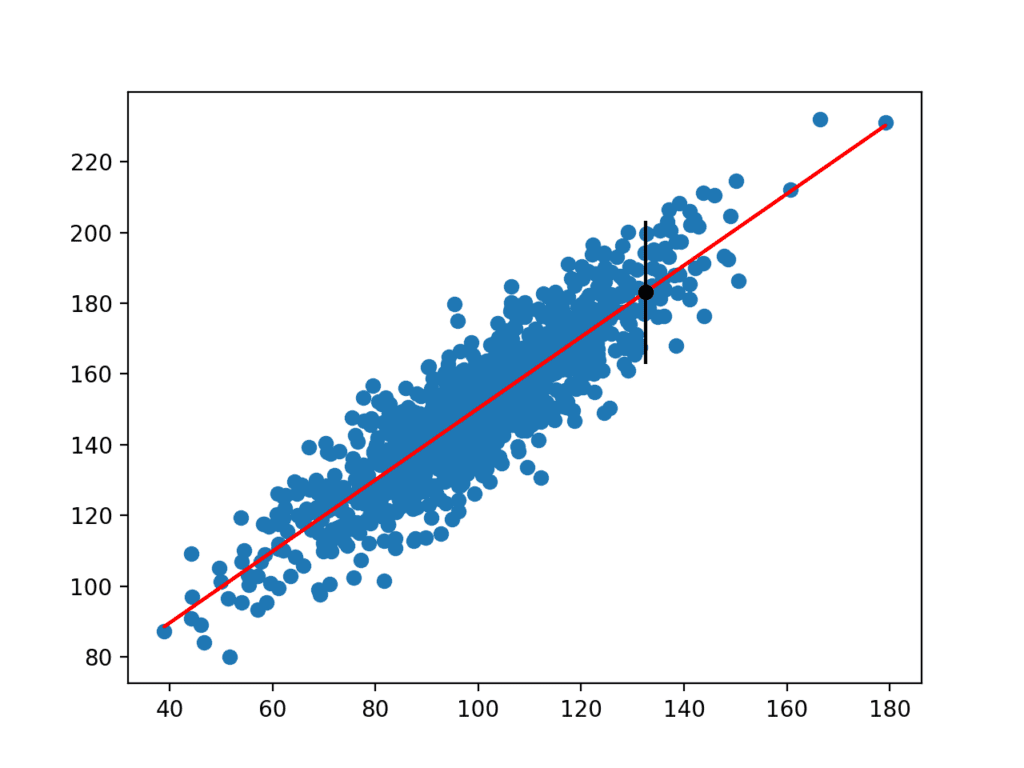
Grafico a dispersione del set di dati con modello lineare e intervallo di previsione
Estensioni
Questa sezione elenca alcune idee per estendere il tutorial che potresti voler esplorare.
- Riassumere la differenza tra tolleranza, confidenza e intervalli di previsione.
- Sviluppare un modello di regressione lineare per un set di dati di apprendimento automatico standard e calcolare gli intervalli di previsione per un piccolo set di test.
- Descrivi in dettaglio come funziona un metodo di intervallo di previsione non lineare.
Se esplori una di queste estensioni, mi piacerebbe saperlo.
Ulteriori letture
Questa sezione fornisce più risorse sull’argomento se stai cercando di approfondire.
Post
- Come Rapporto Prestazioni del Classificatore con Intervalli di Confidenza
- Come Calcolare Bootstrap Intervalli di Confidenza Per la Macchina, i Risultati di Apprendimento in Python
- Capire Time Series Forecast Incertezza Utilizzando Intervalli di Confidenza con Python
- Stimare il Numero di Esperimento si Ripete per Stocastico Algoritmi di Apprendimento automatico
Libri
- Comprendere Le Nuove Statistiche: le Dimensioni dell’Effetto, Intervalli di Confidenza, e la Meta-Analisi, 2017.
- Intervalli statistici: una guida per professionisti e ricercatori, 2017.
- Un’introduzione all’apprendimento statistico: con applicazioni in R, 2013.
- Introduzione alle nuove statistiche: Estimation, Open Science, and Beyond, 2016.
- Previsione: principi e prassi, 2013.
Papers
- A comparison of some error estimates for neural network models, 1995.
- Machine learning approaches for estimation of prediction interval for the model output, 2006.
- A Comprehensive Review of Neural Network-based Prediction Intervals and New Advances, 2010.
API
- scipy.Statistica.linregress () API
- matplotlib.piplot.scatter () API
- matplotlib.piplot.errorbar () API
Articoli
- Intervallo di previsione su Wikipedia
- Intervallo di previsione di Bootstrap su Cross Validated
Riepilogo
In questo tutorial, hai scoperto l’intervallo di previsione e come calcolarlo per un semplice modello di regressione lineare.
In particolare, hai imparato:
- Che un intervallo di previsione quantifica l’incertezza di una previsione di un singolo punto.
- Gli intervalli di previsione possono essere stimati analiticamente per modelli semplici, ma sono più impegnativi per i modelli di apprendimento automatico non lineare.
- Come calcolare l’intervallo di previsione per un semplice modello di regressione lineare.
Hai qualche domanda?
Fai le tue domande nei commenti qui sotto e farò del mio meglio per rispondere.
Ottieni un handle sulle statistiche per l’apprendimento automatico!

Sviluppare una comprensione di lavoro delle statistiche
…scrivendo righe di codice in python
Scopri come nel mio nuovo Ebook:
Metodi statistici per l’apprendimento automatico
Fornisce tutorial di autoapprendimento su argomenti come:
Test di ipotesi, correlazione, statistiche non parametriche, ricampionamento e molto altro…
Scopri come trasformare i dati in conoscenza
Salta gli accademici. Solo risultati.
Guarda cosa c’è dentro