VMware High Availability (HA) è un’utility che elimina la necessità di hardware e software di standby dedicati in un ambiente virtualizzato. VMware HA viene spesso utilizzato per migliorare l’affidabilità, ridurre i tempi di inattività negli ambienti virtuali e migliorare il disaster recovery/business continuity.
Questo capitolo estratto da VCP4 Exam Cram: VMware Certified Professional, 2nd Edition di Elias Khnaser esplora le best practice di VMware HA.
VMware High Availability si occupa principalmente dell’errore dell’host ESX / ESXi e di ciò che accade alle macchine virtuali (VM) in esecuzione su questo host. HA può anche monitorare e riavviare una VM controllando se gli strumenti VMware sono ancora in esecuzione. Quando un host ESX/ESXi fallisce per qualsiasi motivo, anche tutte le macchine virtuali in esecuzione falliscono. VMware HA assicura che le macchine virtuali dall’host fallito possano essere riavviate su altri host ESX/ESXi.
Molte persone confondono erroneamente VMware HA con la tolleranza ai guasti. VMware HA non è fault tolerant in quanto se un host fallisce, anche le VM su di esso falliscono. HA si occupa solo di riavviare quelle VM su altri host ESX / ESXi con risorse sufficienti. La tolleranza ai guasti, d’altra parte, fornisce un accesso ininterrotto alle risorse in caso di guasto dell’host.
 Clicca sull’immagine di copertina del libro qui sopra
Clicca sull’immagine di copertina del libro qui sopra per scaricare l’intero capitolo di Elias Khnaser
su backup e alta disponibilità.
VMware HA mantiene un canale di comunicazione con tutti gli altri host ESX / ESXi che sono membri dello stesso cluster utilizzando un heartbeat che invia ogni 1 secondo in vSphere 4.0 o ogni 10 secondi in vSphere 4.1 per impostazione predefinita. Quando un server ESX manca un heartbeat, gli altri host attendono 15 secondi affinché l’altro host risponda di nuovo. Dopo 15 secondi, il cluster avvia il riavvio delle macchine virtuali sull’host ESX/ESXi non funzionante sugli host ESX/ESXi rimanenti nel cluster. VMware HA inoltre monitora costantemente gli host ESX / ESXi membri del cluster e garantisce che le risorse siano sempre disponibili per soddisfare i requisiti in caso di errore dell’host.
Virtual Machine Failure Monitoring
Virtual Machine Failure Monitoring è una tecnologia disabilitata per impostazione predefinita. La sua funzione è quella di monitorare le macchine virtuali, che interroga ogni 20 secondi tramite un battito cardiaco. Lo fa utilizzando gli strumenti VMware installati all’interno della VM. Quando una VM perde un battito cardiaco, VMware HA ritiene che questa VM non sia riuscita e tenta di ripristinarla. Pensa al monitoraggio dei guasti delle macchine virtuali come a una sorta di alta disponibilità per le macchine virtuali.
Virtual Machine Failure Monitoring può rilevare se una macchina virtuale è stata spenta, sospesa o migrata manualmente e quindi non tenta di riavviarla.
Prerequisiti di configurazione VMware HA
HA richiede i seguenti prerequisiti di configurazione prima di poter funzionare correttamente:
- vCenter: Poiché VMware HA è una funzionalità di classe enterprise, richiede vCenter prima di poter essere abilitato.
- Risoluzione DNS: Tutti gli host ESX / ESXi che sono membri del cluster HA devono essere in grado di risolversi a vicenda utilizzando DNS.
- Accesso allo storage condiviso: tutti gli host nel cluster HA devono avere accesso e visibilità allo stesso storage condiviso; altrimenti, non avrebbero accesso alle macchine virtuali.
- Accesso alla stessa rete: Tutti gli host ESX / ESXi devono avere le stesse reti configurate su tutti gli host in modo che quando una VM viene riavviata su qualsiasi host, abbia nuovamente accesso alla rete corretta.
Ridondanza della Console di servizio
La pratica consigliata impone che la Console di servizio (SC) abbia ridondanza. VMware HA si lamenta e emette un avviso se rileva che la console di servizio è configurata su un vSwitch con un solo vmnic. Come mostra la Figura 1, è possibile configurare la ridondanza della console di servizio in due modi:
- Creare due gruppi di porte della console di servizio, ciascuno su un vSwitch diverso.
- Assegnare due schede di interfaccia di rete fisica (NIC) sotto forma di un team NIC al Service Console vSwitch.
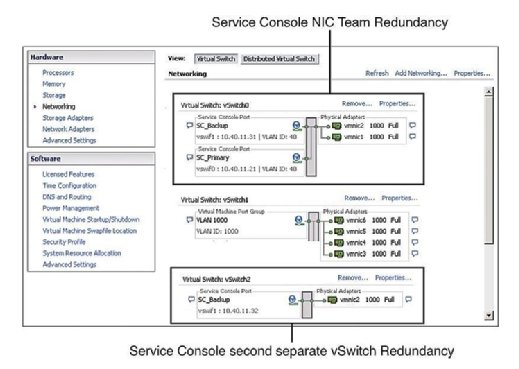
In entrambi i casi, è necessario configurare l’intero stack IP con indirizzo IP, sottorete e gateway. I VSWITCH della console di servizio vengono utilizzati per i battiti cardiaci e la sincronizzazione dello stato e utilizzano le seguenti porte:
- in Arrivo la porta TCP 8042
- in Arrivo la porta UDP 8045
- porta TCP in Uscita il 2050
- in Uscita la porta UDP 2250
- in Arrivo la porta TCP 8042-8045
- in Arrivo la porta UDP 8042-8045
- porta TCP in Uscita 2050-2250
- in Uscita la porta UDP 2050-2250
la Mancata configurazione di SC ridondanza risultati in un messaggio di avviso quando si abilita l’HA. Quindi, per evitare di vedere questo messaggio di errore e di aderire alle best practice, configurare SC in modo che sia ridondante.
Pianificazione della capacità di failover dell’host
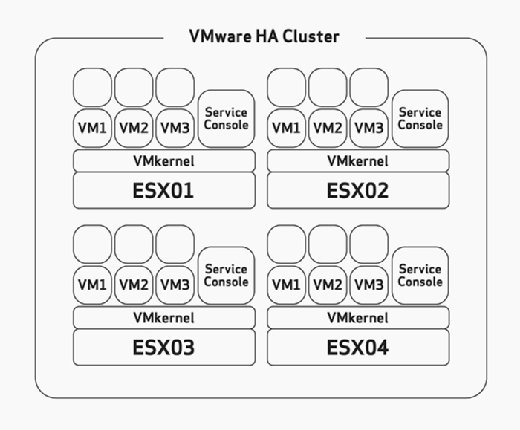
Quando si configura HA, è necessario configurare manualmente la massima tolleranza di errore dell’host. Questa è un’attività che dovresti considerare attentamente durante la fase di dimensionamento e pianificazione dell’hardware della tua distribuzione. Ciò presuppone che gli host ESX/ESXi siano stati creati con risorse sufficienti per eseguire più macchine virtuali del previsto per poter ospitare HA. Ad esempio, nella Figura 2, si noti che il cluster HA ha quattro host ESX e che tutti e quattro questi host hanno una capacità sufficiente per eseguire almeno altre tre VM. Poiché sono già in esecuzione tre VM, ciò significa che questo cluster può permettersi la perdita di due host ESX/ESXi perché i restanti due host ESX/ESXi possono accendere le sei VM fallite senza problemi se si verifica un errore.
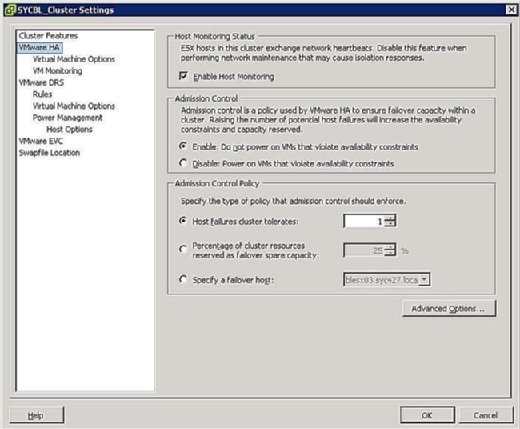
Durante la fase di configurazione del cluster HA, viene visualizzata una schermata simile a quella mostrata in Figura 3 che richiede di definire due configurazioni a livello di cluster come segue:
- Stato monitoraggio host:
- Abilita monitoraggio host: Questa impostazione consente di controllare se il cluster HA deve monitorare gli host per un battito cardiaco. Questo è il modo del cluster di determinare se un host è ancora attivo. In alcuni casi, quando si eseguono attività di manutenzione su host ESX / ESXi, potrebbe essere consigliabile disabilitare questa opzione per evitare di isolare un host.
- Controllo di ammissione:
- Abilita: non accendere le VM che violano i vincoli di disponibilità: La selezione di questa opzione indica che se non sono disponibili risorse per soddisfare una VM, non deve essere attivata.
- Disable: Accensione di macchine virtuali che violano i vincoli di disponibilità: Selezionando questa opzione si indica che è necessario accendere una macchina virtuale anche se è necessario sovraccaricare le risorse.
- Criterio di controllo di ammissione:
- Tolleranza cluster errori host: Questa impostazione consente di configurare il numero di errori host che si desidera tollerare. Le impostazioni consentite sono da 1 a 4.
- Percentuale di risorse cluster riservate come capacità di riserva di failover: Selezionando questa opzione si indica che si sta riservando una percentuale delle risorse totali del cluster in spare per il failover. In un cluster a quattro host, una prenotazione del 25% indica che si sta impostando un host completo per il failover. Se si desidera mettere da parte meno, è possibile scegliere invece il 10% delle risorse del cluster.
- Specificare un host di failover: Selezionando questa opzione si indica che si sta selezionando un determinato host come host di failover nel cluster. Questo potrebbe essere il caso se si dispone di un host di riserva o di un host particolare che ha significativamente più risorse di calcolo e memoria disponibili.
Isolamento host
Un fenomeno di rete noto come split-brain si verifica quando l’host ESX / ESXi ha smesso di ricevere un heartbeat dal resto del cluster. Il battito cardiaco viene interrogato per ogni secondo in vSphere 4.0 o 10 secondi in vSphere 4.1. Se non viene ricevuta una risposta, il cluster ritiene che l’host ESX / ESXi non sia riuscito. Quando ciò si verifica, l’host ESX/ESXi ha perso la connettività di rete sulla sua interfaccia di gestione. L’host potrebbe essere ancora attivo e funzionante e le macchine virtuali potrebbero non essere interessate considerando che potrebbero utilizzare un’interfaccia di rete diversa che non è stata interessata. Tuttavia, vSphere deve agire quando ciò accade perché ritiene che un host abbia fallito. Del resto, è stata creata la risposta di isolamento dell’host. Host isolation response è il modo di HA di trattare con un host ESX/ESXi che ha perso la connessione di rete.
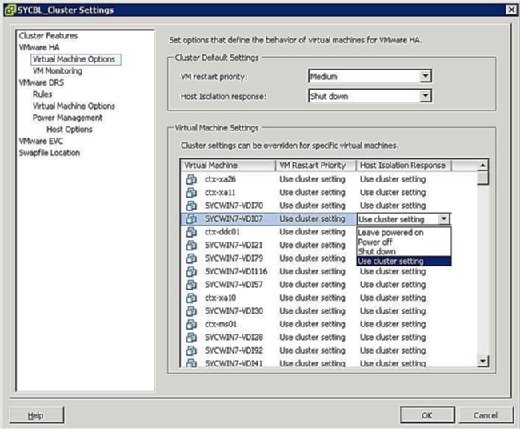
È possibile controllare cosa succede alle macchine virtuali in caso di isolamento dell’host. Per accedere alla schermata di risposta all’isolamento della VM, fare clic con il pulsante destro del mouse sul cluster in questione e fare clic su Modifica impostazioni. È quindi possibile fare clic su Opzioni macchina virtuale sotto il banner VMware HA nel riquadro di sinistra. È possibile controllare le opzioni clusterwide impostando l’opzione di risposta di isolamento host di conseguenza. Questo viene applicato a tutte le macchine virtuali sull’host interessato. Detto questo, è sempre possibile sovrascrivere le impostazioni del cluster definendo una risposta diversa a livello di VM.
Come mostrato nella Figura 4, le opzioni di risposta all’isolamento sono le seguenti:
- Lasciare acceso: Come suggerisce l’etichetta, questa impostazione significa che in caso di isolamento dell’host, la VM rimane accesa.
- Spegnimento: questa impostazione definisce che, in caso di isolamento, la VM è spenta. Questo è un potere duro fuori.
- Shut down: questa impostazione definisce che, in caso di isolamento, la VM viene chiusa con garbo utilizzando VMware Tools. Se questa attività non viene completata correttamente entro cinque minuti, viene immediatamente eseguito uno spegnimento. Se VMware Tools non è installato, viene invece eseguito uno spegnimento.
- Usa impostazione cluster: Questa impostazione inoltra l’attività all’impostazione clusterwide definita nella finestra mostrata precedentemente in Figura 4.
In caso di isolamento, ciò non significa necessariamente che l’host sia inattivo. Poiché le macchine virtuali potrebbero essere configurate con NIC fisici diversi e collegate a reti diverse, potrebbero continuare a funzionare correttamente; è quindi necessario considerare questo quando si imposta la priorità per l’isolamento. Quando un host è isolato, ciò significa semplicemente che la sua Console di servizio non può comunicare con il resto degli host ESX/ESXi nel cluster.
Priorità di ripristino della macchina virtuale
Se il cluster HA non è in grado di ospitare tutte le macchine virtuali in caso di errore, è possibile assegnare priorità alle macchine virtuali. Le priorità determinano quali macchine virtuali vengono riavviate per prime e quali non sono così importanti in caso di emergenza. Queste opzioni sono configurate nella stessa schermata della risposta di isolamento trattata nella sezione precedente. È possibile configurare le impostazioni di clusterwide che verranno applicate a tutte le macchine virtuali sull’host interessato oppure eseguire l’override delle impostazioni del cluster configurando un’override a livello di macchina virtuale.
È possibile impostare la priorità di riavvio di una VM su una delle seguenti opzioni:
- High: le VM con priorità elevata vengono riavviate per prime.
- Medio: Questa è l’impostazione predefinita.
- Basso: le macchine virtuali con priorità bassa vengono riavviate per ultime.
- Usa impostazione cluster: le macchine virtuali vengono riavviate in base all’impostazione definita a livello di cluster definita nella finestra mostrata nella figura seguente.
- Disabilitato: la VM non si accende.
La priorità deve essere impostata in base all’importanza delle macchine virtuali. In altre parole, è possibile riavviare i controller di dominio e non riavviare i server di stampa. Le macchine virtuali con priorità maggiore vengono riavviate per prime. Le macchine virtuali che possono tollerare di rimanere spente in caso di emergenza devono essere configurate per rimanere spente per risparmiare risorse.
MSCS clustering
Lo scopo principale di un cluster è garantire che i sistemi critici rimangano online ad ogni costo e in ogni momento. Simile alle macchine fisiche che possono essere raggruppate, le macchine virtuali possono anche essere raggruppate con ESX utilizzando tre diversi scenari:
- Cluster-in-a-box: In questo scenario, tutte le macchine virtuali che fanno parte del cluster risiedono sullo stesso host ESX / ESXi. Come avrai intuito, questo crea immediatamente un singolo punto di errore: l’host ESX/ESXi. Per quanto riguarda lo storage condiviso, è possibile utilizzare i dischi virtuali come storage condiviso in questo scenario, oppure è possibile utilizzare Raw Device Mapping (RDM) in modalità di compatibilità virtuale.
- Cluster-across-boxes: in questo scenario, i nodi del cluster (VM che sono membri del cluster) risiedono su più host ESX / ESXi, in cui ciascuno dei nodi che compongono il cluster può accedere allo stesso storage in modo che se una VM fallisce, l’altra può continuare a funzionare e accedere agli stessi dati. Questo scenario crea un ambiente cluster ideale eliminando un singolo punto di errore. Lo storage condiviso è un prerequisito in questo e deve risiedere su SAN Fibre Channel. È inoltre necessario utilizzare un RDM in modalità di compatibilità fisica o virtuale poiché i dischi virtuali non sono una configurazione supportata per l’archiviazione condivisa. Per cui ciascuno dei nodi che compongono il cluster può accedere allo stesso storage in modo che se una VM fallisce, l’altra può continuare a funzionare e accedere agli stessi dati.
- Cluster fisico-virtuale: In questo scenario, un membro del cluster è una macchina virtuale, mentre l’altro membro è una macchina fisica. Lo storage condiviso è un prerequisito in questo scenario e deve essere configurato come RDM in modalità Compatibilità fisica.
Ogni volta che si progetta una soluzione di clustering è necessario affrontare il problema dello storage condiviso, che consentirebbe a più host o VM di accedere agli stessi dati. vSphere offre diversi metodi con cui è possibile eseguire il provisioning dello storage condiviso come segue:
- Dischi virtuali: È possibile utilizzare un disco virtuale come area di archiviazione condivisa solo se si sta eseguendo il clustering in una scatola, in altre parole, solo se entrambe le macchine virtuali risiedono sullo stesso host ESX / ESXi.
- RDM in modalità compatibilità fisica: Questa modalità consente di collegare un LUN fisico direttamente in una macchina virtuale o fisica. Questa modalità impedisce l’utilizzo di funzionalità come le istantanee e viene idealmente utilizzata quando un membro del cluster è una macchina fisica mentre l’altro è una VM.
- RDM in modalità di compatibilità virtuale: Questa modalità consente di collegare un LUN fisico direttamente in una macchina virtuale o fisica. Questa modalità offre tutti i vantaggi dei dischi virtuali in esecuzione su VMFS, incluse le istantanee e il blocco avanzato dei file. Il disco è accessibile tramite l’hypervisor ed è ideale quando si configura uno scenario cluster-across-box in cui è necessario dare a entrambe le VM l’accesso allo storage condiviso.
Al momento della stesura di questo documento, l’unico servizio di clustering supportato da VMware è Microsoft Clustering Services (MSCS). È possibile consultare il white paper VMware ” Setup for Failover Clustering and Microsoft Cluster Service.”
VMware Fault Tolerance
VMware Fault Tolerance (FT) è un’altra forma di clustering di VM sviluppata da VMware per sistemi che richiedono tempi di attività estremi. Una delle caratteristiche più interessanti di FT è la sua facilità di installazione. FT è semplicemente una casella di controllo che può essere abilitata. Rispetto al clustering tradizionale che richiede configurazioni specifiche e in alcuni casi il cablaggio, FT è semplice ma potente.
Come funziona?
Quando si proteggono le VM con FT, viene creata una VM secondaria in fase di blocco della VM protetta, la prima VM. FT funziona scrivendo contemporaneamente alla prima VM e alla seconda VM contemporaneamente. Ogni attività è scritta due volte. Se si fa clic sul menu Start della prima VM, verrà fatto clic anche sul menu Start della seconda VM. La potenza di FT è la sua capacità di mantenere entrambe le VM sincronizzate.
Se la VM protetta dovesse andare giù per qualsiasi motivo, la VM secondaria prende immediatamente il suo posto, cogliendo la sua identità e il suo indirizzo IP, continuando a servire gli utenti senza interruzioni. La VM protetta appena promossa crea quindi una secondaria per se stessa su un altro host e il ciclo si riavvia.
Per chiarire, vediamo un esempio. Se si desidera proteggere un server Exchange, è possibile abilitare FT. Se per qualsiasi motivo l’host ESX/ESXi che trasporta la VM protetta fallisce, la VM secondaria entra in funzione e assume le sue funzioni senza interruzioni nel servizio.
La tabella seguente delinea le diverse tecnologie ad alta disponibilità e di clustering a cui si ha accesso con vSphere ed evidenzia i limiti di ciascuna.

Requisiti di tolleranza ai guasti
La tolleranza ai guasti non è diversa da qualsiasi altra funzionalità aziendale in quanto richiede determinati prerequisiti da soddisfare prima che la tecnologia possa funzionare correttamente efficiente. Questi requisiti sono descritti nel seguente elenco e suddivisi nelle diverse categorie che richiedono requisiti minimi specifici:
- Requisiti host:
- CPU compatibile con FT. Consulta questo articolo di VMware KB per ulteriori informazioni.
- La virtualizzazione hardware deve essere abilitata nel bios.
- Le velocità di clock della CPU dell’host devono essere entro 400 MHz l’una dall’altra.
- Requisiti VM:
- Le VM devono risiedere nello storage condiviso supportato (FC, FCsi e NFS).
- Le macchine virtuali devono eseguire un sistema operativo supportato.
- Le macchine virtuali devono essere memorizzate in un VMDK o in un RDM virtuale.
- Le VM non possono avere VMDK con un provisioning sottile e devono utilizzare un disco virtuale Eagerzeroedthick.
- Le VM non possono avere più di una vCPU configurata.
- Requisiti del cluster:
- Tutti gli host ESX / ESXi devono avere la stessa versione e lo stesso livello di patch.
- Tutti gli host ESX/ESXi devono avere accesso ai datastore e alle reti VM.
- VMware HA deve essere abilitato sul cluster.
- Ogni host deve avere una NIC di registrazione vMotion e FT configurata.
- Anche il controllo del certificato host deve essere abilitato.
È altamente consigliabile, oltre a verificare la compatibilità del processore con FT, verificare la compatibilità di marca e modello del server con FT rispetto alla VMware Hardware Compatibility List (HCL).
Mentre FT è un’ottima soluzione di clustering, è importante notare che ha anche alcune limitazioni. Ad esempio, le VM FT non possono essere snapshottate e non possono essere Storage vMotioned. Di fatto, queste macchine virtuali verranno automaticamente contrassegnate come DRS-Disabled e non parteciperanno a alcun bilanciamento dinamico del carico delle risorse.
Come abilitare FT
Abilitare FT non è difficile, ma comporta la configurazione di alcune impostazioni diverse. Le seguenti impostazioni devono essere configurate correttamente per il funzionamento di FT:
- Abilita il controllo del certificato host: Per abilitare questa impostazione, accedere al vCenter server e fare clic su Amministrazione dal menu File e fare clic su Impostazioni vCenter Server. Nel riquadro di sinistra, fare clic su Impostazioni SSL e selezionare la casella vCenter Richiede certificati SSL host verificati.
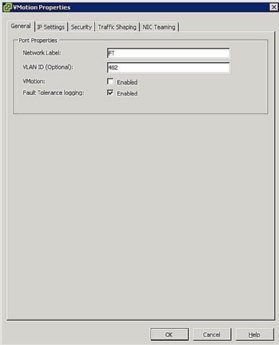
Figura 5. Impostazioni del gruppo di porte FT - Configura rete host: La configurazione di rete per FT è semplice e segue gli stessi passaggi e le stesse procedure di vMotion, tranne che invece di selezionare la casella vMotion, selezionare la casella di registrazione della tolleranza ai guasti come mostrato in Figura 5.
- Accensione e spegnimento di FT: una volta soddisfatti i requisiti precedenti, è ora possibile attivare e disattivare FT per le macchine virtuali. Anche questo processo è semplice: trova la VM che vuoi proteggere, fai clic con il pulsante destro del mouse e seleziona Fault Tolerance > Attiva Fault Tolerance.
Sebbene FT sia una tecnologia di clustering di prima generazione, funziona in modo impressionante e semplifica i metodi tradizionali troppo complessi di creazione, configurazione e manutenzione dei cluster. FT è una tecnologia impressionante per un punto di vista di uptime e da un punto di vista di failover senza soluzione di continuità.