Activeringsfuncties zijn het meest cruciale onderdeel van elk neuraal netwerk in deep learning. In het diepe leren, zijn de zeer ingewikkelde taken beeldclassificatie, taaltransformatie, objectopsporing, enz.die nodig zijn om met behulp van neurale netwerken en activeringsfunctie aan te pakken. Dus, zonder dat, deze taken zijn uiterst complex om te behandelen.
In het kort, een neuraal netwerk is een zeer krachtige techniek in machine learning die in principe imiteert hoe een brein begrijpt, hoe? De hersenen ontvangen de stimuli, als input, uit de omgeving, verwerken het en produceren dan de output dienovereenkomstig.
Inleiding
de neurale netwerkactiveringsfuncties zijn in het algemeen de belangrijkste component van Deep Learning, ze worden fundamenteel gebruikt voor het bepalen van de output van deep learning-modellen, de nauwkeurigheid ervan en de prestatie-efficiëntie van het trainingsmodel dat een neuraal netwerk op grote schaal kan ontwerpen of verdelen.
Activeringsfuncties hebben aanzienlijke effecten achtergelaten op het vermogen van neurale netwerken om te convergeren en convergentiesnelheid, wilt u niet hoe? Laten we doorgaan met een introductie tot de activeringsfunctie, typen activeringsfuncties & hun belang en beperkingen via deze blog.
Wat is de activeringsfunctie?
activeringsfunctie definieert de output van input of set van inputs of in andere termen definieert knooppunt van de output van knooppunt dat wordt gegeven in inputs. Ze besluiten om neuronen te deactiveren of te activeren om de gewenste output te krijgen. Het voert ook een niet-lineaire transformatie op de input om betere resultaten op een complex neuraal netwerk te krijgen.
activeringsfunctie helpt ook om de uitvoer van elke ingang in het bereik tussen 1 en -1 te normaliseren. De activeringsfunctie moet efficiënt zijn en het zou de rekentijd moeten verminderen omdat het neurale netwerk soms op miljoenen gegevenspunten wordt getraind.
activeringsfunctie bepaalt in principe in elk neuraal netwerk dat gegeven input of het ontvangen van informatie relevant of irrelevant is. Laten we een voorbeeld nemen om beter te begrijpen wat een neuron is en hoe de activeringsfunctie de uitgangswaarde tot een bepaalde limiet begrenst.
het neuron is in principe een gewogen gemiddelde van de input, dan wordt deze som doorgegeven door een activeringsfunctie om een output te krijgen.
Y = ∑ (gewichten*input + bias)
Hier kan Y alles zijn voor een neuron tussen bereik-oneindigheid tot +oneindigheid. Dus moeten we onze output binden om de gewenste voorspelling of gegeneraliseerde resultaten te krijgen.
Y = activeringsfunctie(∑ (gewichten*input + bias))
dus we geven dat neuron aan activeringsfunctie door aan gebonden uitgangswaarden.
Waarom hebben we Activeringsfuncties nodig?
zonder activeringsfunctie zouden gewicht en bias alleen een lineaire transformatie hebben, of neuraal netwerk is slechts een lineair regressiemodel, een lineaire vergelijking is een polynoom van slechts één graad die eenvoudig op te lossen is, maar beperkt in termen van het vermogen om complexe problemen of hogere graad polynomen op te lossen.
maar omgekeerd voert de toevoeging van de activeringsfunctie aan het neurale netwerk de niet-lineaire transformatie naar invoer uit en maakt het het mogelijk om complexe problemen zoals taalvertalingen en beeldclassificaties op te lossen.
daarnaast zijn Activeringsfuncties differentieerbaar waardoor ze gemakkelijk back propagations, geoptimaliseerde strategie kunnen implementeren terwijl ze backpropagaties uitvoeren om gradiëntverliesfuncties in de neurale netwerken te meten.
Soorten Activering van Functies
De meest bekende activering functies worden hieronder gegeven,
-
Binaire stap
-
Lineaire
-
ReLU
-
LeakyReLU
-
Dikke
-
Tanh
-
Softmax
1. Binaire stap activeringsfunctie
Deze activeringsfunctie is zeer basisch en het komt elke keer als we proberen om output te binden in gedachten. Het is eigenlijk een drempel basis classifier, in dit, we besluiten een drempelwaarde om te beslissen output dat neuron moet worden geactiveerd of gedeactiveerd.
f(x) = 1 if x > 0 else 0 if x < 0
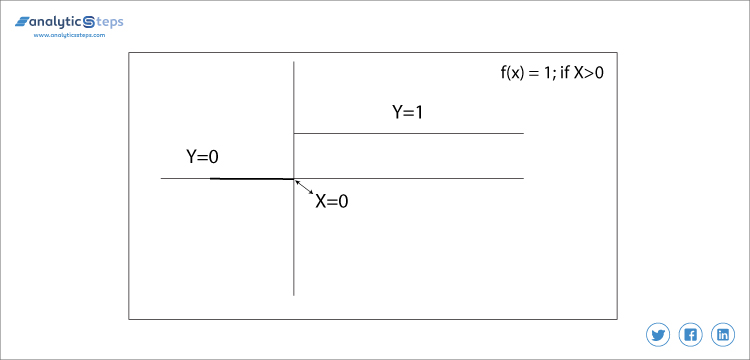
binaire stapfunctie
hierin bepalen we de drempelwaarde tot 0. Het is heel eenvoudig en handig om binaire problemen of classifier te classificeren.
2. Lineaire activeringsfunctie
Het is een eenvoudige rechte activeringsfunctie waarbij onze functie recht evenredig is met de gewogen som van neuronen of input. Lineaire activeringsfuncties zijn beter in het geven van een breed scala aan activeringen en een lijn met een positieve helling kan de ontstekingssnelheid verhogen naarmate de Ingangssnelheid toeneemt.
in binair, is een neuron aan het vuren of niet. Als je gradiëntafdaling kent in diep leren dan zou je merken dat in deze functie afgeleide constant is.
Y = mZ
waar de afgeleide met betrekking tot Z constant m is. de Betekenis gradiënt is ook constant en het heeft niets te maken met Z. In dit, als de veranderingen in de backpropagatie constant zullen zijn en niet afhankelijk van Z, dus dit zal niet goed zijn voor het leren.
In deze, onze tweede laag is de output van een lineaire functie van de vorige lagen invoer. Wacht eens even, wat hebben we hierin geleerd dat als we alle lagen vergelijken en alle lagen verwijderen behalve de eerste en laatste dan kunnen we ook alleen een output krijgen die een lineaire functie is van de eerste laag.
3. ReLU (Rectified Linear unit) activeringsfunctie
gerectificeerde lineaire eenheid of ReLU wordt op dit moment het meest gebruikt activeringsfunctie die varieert van 0 tot oneindig, alle negatieve waarden worden omgezet in nul, en deze conversiesnelheid is zo snel dat het niet goed kan in kaart brengen of passen in gegevens, wat een probleem veroorzaakt, maar waar er een probleem is, is er een oplossing.
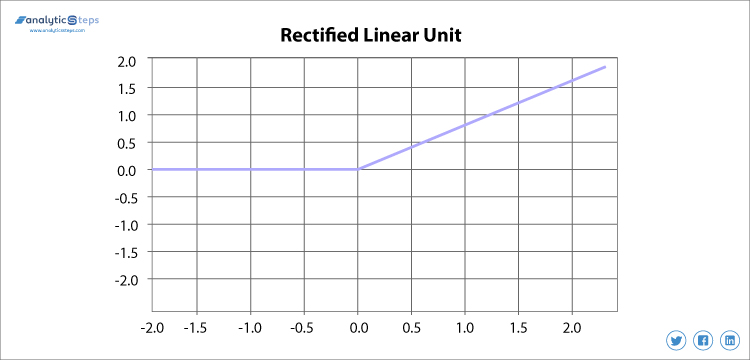
gerectificeerde Lineaire eenheid activeringsfunctie
We gebruiken Leaky ReLU-functie in plaats van ReLU om dit unfitting te voorkomen, in Leaky ReLU range wordt uitgebreid wat de prestaties verbetert.
lekkende ReLU-activeringsfunctie
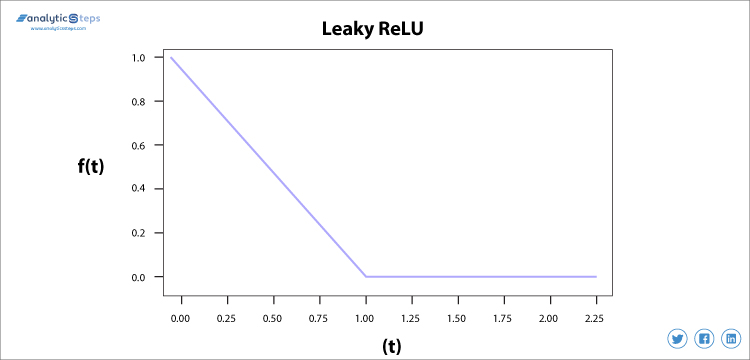
Leaky ReLU Activation Function
We hadden de Leaky ReLU activation function nodig om het ‘Dying ReLU’ probleem op te lossen, zoals besproken in ReLU, zien we dat alle negatieve input waarden zeer snel in nul veranderen en in het geval van Leaky ReLU maken we niet alle negatieve input tot nul maar tot een waarde dicht bij nul die het belangrijkste probleem van de ReLU activation function oplost.
Sigmoid activeringsfunctie
de sigmoid activeringsfunctie wordt meestal gebruikt omdat het zijn taak met grote efficiëntie doet, het is in principe een probabilistische benadering van besluitvorming en varieert tussen 0 en 1, dus als we een beslissing moeten nemen of een output moeten voorspellen, gebruiken we deze activeringsfunctie omdat het bereik het minimum is, daarom zou voorspelling nauwkeuriger zijn.
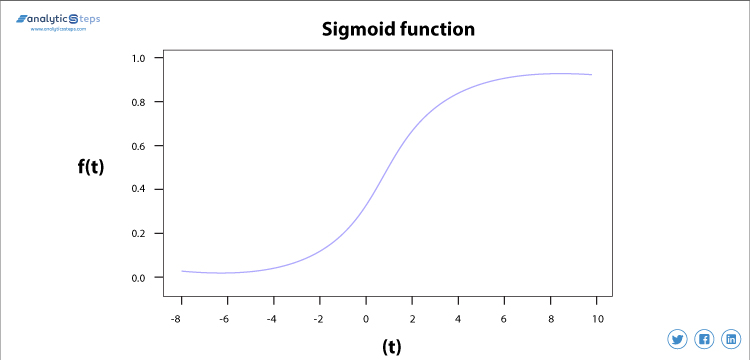
Sigmoid functie Activering
de vergelijking voor De sigmoid functie
f(x) = 1/(1+e(-x) )
De sigmoid functie veroorzaakt een probleem dat vooral genoemd als verdwijnend verloop probleem treedt op omdat we zetten een grote invoer in tussen het bereik van 0 tot 1 en dus hun derivaten worden veel kleiner dat geen bevredigende uitvoer. Om dit probleem op te lossen wordt een andere activeringsfunctie zoals ReLU gebruikt waar we geen klein derivaatprobleem hebben.
hyperbolische Tangentactiveringsfunctie(Tanh)
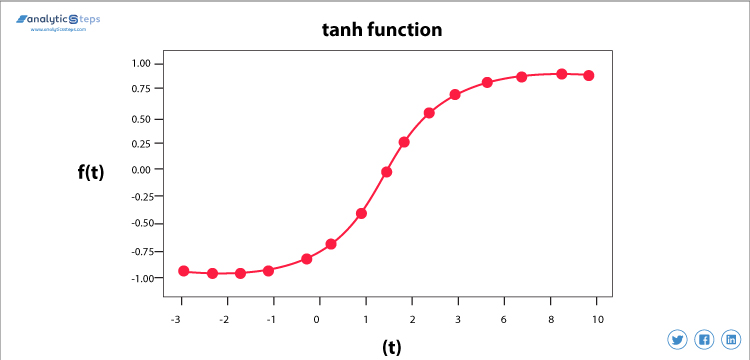
Tanh activeringsfunctie
Deze activeringsfunctie is iets beter dan de sigmoid-functie, net als de sigmoid-functie wordt het ook gebruikt om twee klassen te voorspellen of te onderscheiden, maar het brengt de negatieve invoer alleen in negatieve grootheid en varieert tussen -1 en 1.
Softmax-activeringsfunctie
Softmax wordt voornamelijk gebruikt op de laatste laag i.e-outputlaag voor het nemen van de beslissing hetzelfde als sigmoid activering werkt, softmax geeft in principe waarde aan de inputvariabele volgens hun gewicht en de som van deze gewichten is uiteindelijk één.
Softmax op binaire classificatie
voor binaire classificatie zijn zowel sigmoid als softmax even benaderbaar, maar in het geval van een multi-class classificatieprobleem gebruiken we over het algemeen softmax en cross-entropy samen.
conclusie
De activeringsfuncties zijn die belangrijke functies die een niet-lineaire transformatie naar de input uitvoeren en die het Bekwaam maken om complexere taken te begrijpen en uit te voeren. We hebben 7 voornamelijk gebruikte activeringsfuncties besproken met hun beperking (indien aanwezig), deze activeringsfuncties worden gebruikt voor hetzelfde doel, maar in verschillende omstandigheden.