Hi en Welkom bij een geïllustreerde gids voor lange korte termijn geheugen (LSTM) en gated recurrent units (Gru). Ik ben Michael, en ik ben een machine Learning ingenieur in de AI stem assistent ruimte.
in dit bericht zullen we beginnen met de intuïtie achter LSTM ’s en GRU’ s. Daarna zal ik de interne mechanismen uitleggen die LSTM ’s en GRU’ s zo goed laten presteren. Als u wilt begrijpen wat er gebeurt onder de motorkap voor deze twee netwerken, dan is dit bericht is voor jou.
u kunt ook de videoversie van dit bericht op youtube bekijken als u dat wilt.
terugkerende neurale netwerken lijden aan kortetermijngeheugen. Als een reeks lang genoeg is, zullen ze het moeilijk hebben om informatie van eerdere stappen naar latere te dragen. Dus als je probeert om een paragraaf van de tekst te verwerken om voorspellingen te doen, kunnen RNN ‘ s belangrijke informatie vanaf het begin weglaten.
tijdens rugpropagatie lijden terugkerende neurale netwerken aan het verdwijnende gradiëntprobleem. Gradiënten zijn waarden die worden gebruikt om een neurale netwerken gewichten bij te werken. De verdwijnende gradiënt probleem is wanneer de gradiënt krimpt als het terug zich voortplant door de tijd. Als een gradiëntwaarde extreem klein wordt, draagt het niet te veel bij aan het leren.

dus in terugkerende neurale netwerken stoppen lagen die een kleine gradiëntupdate krijgen met leren. Dat zijn meestal de eerdere lagen. Dus omdat deze lagen niet leren, kunnen RNN ‘ s vergeten wat ze zagen in langere sequenties, waardoor ze een kortetermijngeheugen hebben. Als u meer wilt weten over de mechanica van terugkerende neurale netwerken in het algemeen, kunt u mijn vorige bericht hier lezen.
LSTM ’s en GRU’ s als een oplossing
LSTM ’s en GRU’ s werden gemaakt als de oplossing voor korte termijn geheugen. Ze hebben interne mechanismen genaamd poorten die de stroom van informatie kunnen regelen.

deze poorten kunnen leren welke data in een reeks belangrijk is om te bewaren of weg te gooien. Door dat te doen, kan het relevante informatie doorgeven langs de lange keten van sequenties om voorspellingen te doen. Bijna alle state of the art resultaten op basis van terugkerende neurale netwerken worden bereikt met deze twee netwerken. LSTM ’s en GRU’ s zijn te vinden in spraakherkenning, spraaksynthese en tekstgeneratie. U kunt ze zelfs gebruiken om bijschriften voor video ‘ s te genereren.
Ok, dus aan het einde van dit bericht Zou je een goed begrip moeten hebben van waarom LSTM ’s en GRU’ s goed zijn in het verwerken van lange sequenties. Ik ga dit benaderen met intuïtieve uitleg en illustraties en vermijd zoveel mogelijk wiskunde.
Intuã tie
Ok, laten we beginnen met een gedachte-experiment. Stel dat je online reviews bekijkt om te bepalen of je life cereal wilt kopen (vraag me niet waarom). Je leest eerst de recensie en dan bepalen of iemand dacht dat het goed was of dat het slecht was.

wanneer u de recensie leest, onthoudt uw brein onbewust alleen belangrijke trefwoorden. Je pick-up woorden als “geweldig ” en”perfect uitgebalanceerd ontbijt”. Je geeft niet veel om woorden als” dit”,” gaf”,” alles”,” zou”, enz. Als een vriend je de volgende dag vraagt wat de recensie zei, zou je het waarschijnlijk niet woord voor woord onthouden. Je zou kunnen herinneren de belangrijkste punten al als “zal zeker weer kopen”. Als je veel op mij lijkt, verdwijnen de andere woorden uit het geheugen.

en dat is in wezen wat een LSTM of Gru doet. Het kan leren om alleen relevante informatie te houden om voorspellingen te doen en niet-relevante gegevens te vergeten. In dit geval, de woorden die je je herinnerde deed je oordelen dat het goed was.
overzicht van terugkerende neurale netwerken
om te begrijpen hoe LSTM ’s of GRU’ s dit bereiken, laten we het terugkerende neurale netwerk bekijken. Een RNN werkt zo; de eerste woorden worden omgezet in machineleesbare vectoren. Dan verwerkt RNN de opeenvolging van vectoren één voor één.

tijdens het verwerken wordt de vorige verborgen status doorgegeven aan de volgende stap van de reeks. De verborgen toestand fungeert als het neurale netwerkgeheugen. Het bevat informatie over eerdere gegevens die het netwerk eerder heeft gezien.

laten we eens kijken naar een cel van de RNN om te zien hoe je de verborgen toestand zou berekenen. Eerst worden de invoer en de vorige verborgen toestand gecombineerd om een vector te vormen. Die vector heeft nu informatie over de huidige invoer en eerdere invoer. De vector gaat door de tanh activering, en de output is de nieuwe verborgen toestand, of het geheugen van het netwerk.

tanh-activering
de tanh-activering wordt gebruikt om de waarden die door het netwerk stromen te helpen reguleren. De tanh-functie drukt waarden samen om altijd tussen -1 en 1 te liggen.

Wanneer de vectoren die door een neuraal netwerk, het ondergaat veel veranderingen als gevolg van verschillende wiskundige bewerkingen. Stel je een waarde voor die nog steeds vermenigvuldigd wordt met Laten we zeggen 3. Je kunt zien hoe sommige waarden kunnen exploderen en astronomisch worden, waardoor andere waarden onbelangrijk lijken.

Een tanh-functie zorgt ervoor dat de waarden tussen -1 en 1, dus het reguleren van de output van het neurale netwerk. U kunt zien hoe dezelfde waarden van bovenaf tussen de grenzen blijven die door de tanh functie zijn toegestaan.

dus dat is een RNN. Het heeft zeer weinig operaties intern maar werkt vrij goed gezien de juiste omstandigheden (zoals korte sequenties). RNN ’s gebruiken veel minder rekenkrachtbronnen dan de geëvolueerde varianten, LSTM’ s en GRU ‘ S.
LSTM
een LSTM heeft een vergelijkbare controlestroom als een terugkerend neuraal netwerk. Het verwerkt gegevens die informatie doorgeven terwijl het zich voortplant. De verschillen zijn de bewerkingen binnen de cellen van de LSTM.

Deze operaties worden gebruikt om de LSTM te houden of het vergeten van informatie. Kijken naar deze operaties kan een beetje overweldigend zijn, dus we zullen dit stap voor stap bespreken.
kernconcept
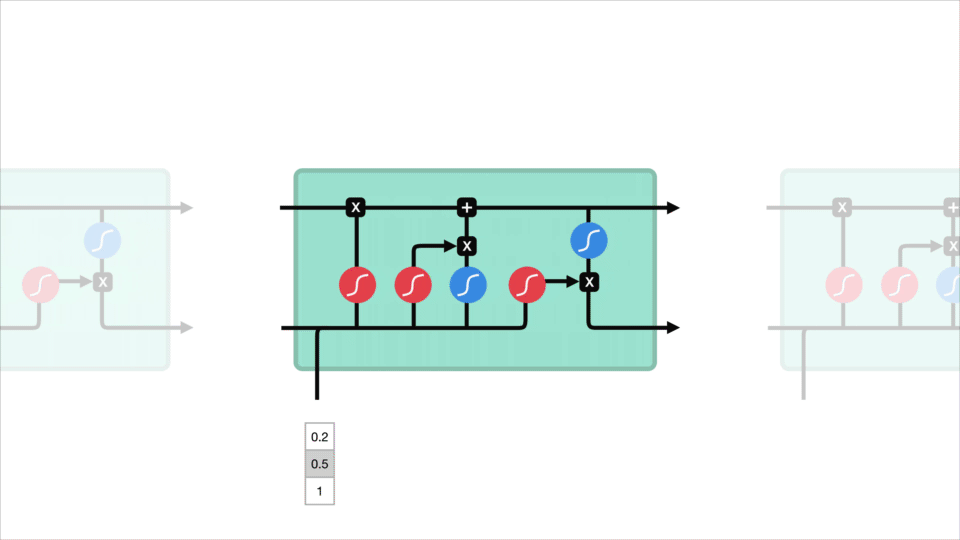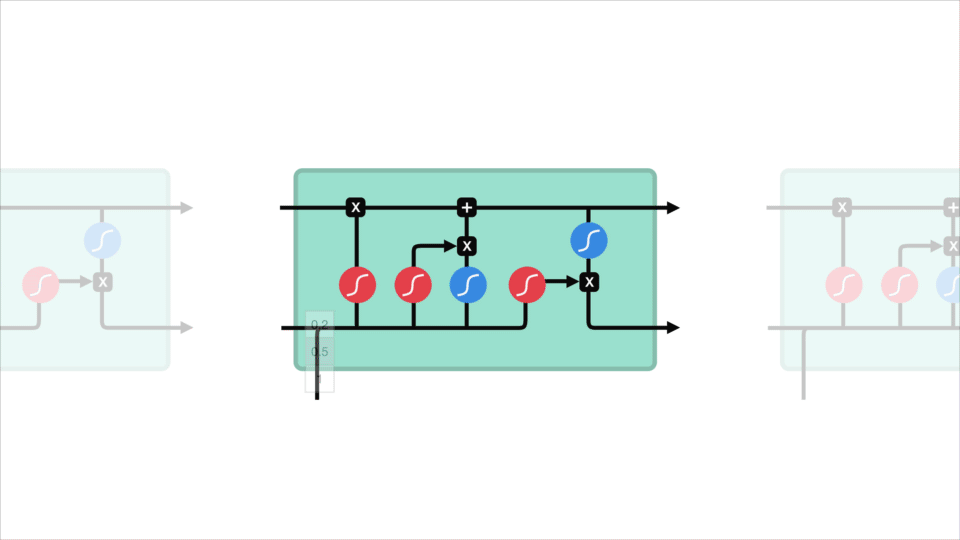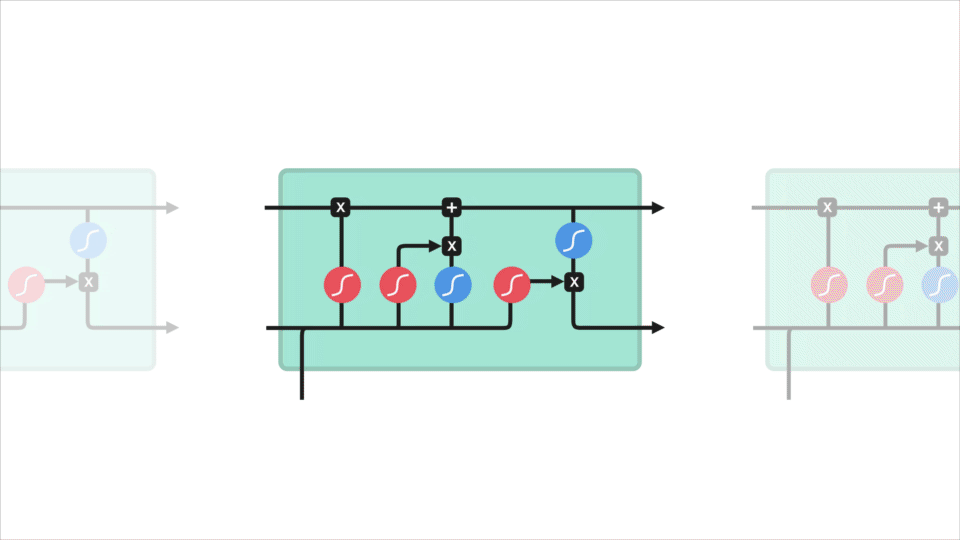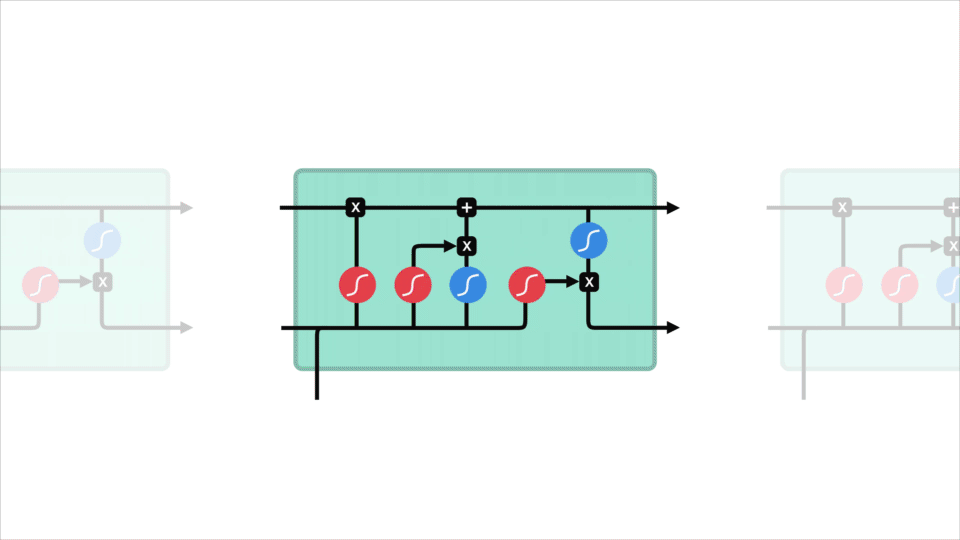
het kernconcept van LSTM ‘ s is de celstatus, en het zijn verschillende poorten. De celstaat doet dienst als transportweg die relatieve informatie helemaal onderaan de opeenvolgingsketen overbrengt. Je kunt het zien als het” geheugen ” van het netwerk. De celstaat, in theorie, kan relevante informatie door de verwerking van de opeenvolging dragen. Dus zelfs informatie uit de eerdere tijd stappen kan maken het is weg naar latere tijd stappen, het verminderen van de effecten van korte termijn geheugen. Aangezien de celstaat op zijn reis gaat, wordt de informatie toegevoegd of verwijderd aan de celstaat via poorten. De poorten zijn verschillende neurale netwerken die beslissen welke informatie is toegestaan op de cel staat. De gates kunnen leren welke informatie relevant is om te bewaren of te vergeten tijdens de training.
Sigmoid
Gates bevat sigmoid-activeringen. Een sigmoid activering is vergelijkbaar met de tanh activering. In plaats van waarden tussen -1 en 1 te drukken, worden waarden tussen 0 en 1 geplet. Dat is handig om gegevens bij te werken of te vergeten, omdat elk getal dat wordt vermenigvuldigd met 0 0 is, waardoor waarden verdwijnen of worden “vergeten.”Elk getal vermenigvuldigd met 1 is dezelfde waarde dus die waarde blijft hetzelfde of wordt” behouden.”Het netwerk kan leren welke gegevens niet belangrijk zijn en dus vergeten kunnen worden of welke gegevens belangrijk zijn om te bewaren.

laten we wat dieper graven in wat de verschillende poorten doen, zullen we? We hebben dus drie verschillende poorten die de informatiestroom in een LSTM-cel regelen. Een Vergeet poort, ingang poort, en uitgang Poort.
poort vergeten
eerst hebben we de poort vergeten. Deze poort bepaalt welke informatie moet worden weggegooid of bewaard. Informatie van de vorige verborgen toestand en informatie van de huidige invoer wordt doorgegeven via de sigmoid-functie. Waarden komen tussen 0 en 1. Hoe dichter bij 0 betekent vergeten, en hoe dichter bij 1 betekent houden.

invoerpoort
om de celstatus bij te werken, hebben we de invoerpoort. Eerst geven we de vorige verborgen toestand en huidige invoer door aan een sigmoid functie. Dat bepaalt welke waarden worden bijgewerkt door de waarden om te zetten naar tussen 0 en 1. 0 betekent niet belangrijk, en 1 betekent belangrijk. U geeft ook de verborgen toestand en de huidige invoer door aan de tanh-functie om waarden tussen -1 en 1 te squish om het netwerk te helpen reguleren. Dan vermenigvuldig je de tanh output met de sigmoid output. De sigmoid-uitgang bepaalt welke informatie belangrijk is om te bewaren van de tanh-uitgang.

celstatus
nu moeten we genoeg informatie hebben om de celstatus te berekenen. Ten eerste wordt de celstatus puntsgewijs vermenigvuldigd met de Vergeet-vector. Dit heeft een mogelijkheid om waarden in de celstatus te laten vallen als deze wordt vermenigvuldigd met waarden in de buurt van 0. Dan nemen we de output van de invoerpoort en doen we een puntsgewijze toevoeging die de celstatus bijwerkt naar nieuwe waarden die het neurale netwerk relevant vindt. Dat geeft ons onze nieuwe cel staat.

output Gate
laatste hebben we de output Gate. De uitgangspoort bepaalt wat de volgende verborgen toestand moet zijn. Vergeet niet dat de verborgen toestand informatie bevat over eerdere invoer. De verborgen toestand wordt ook gebruikt voor voorspellingen. Eerst geven we de vorige verborgen toestand en de huidige invoer door aan een sigmoid functie. Dan geven we de nieuw gewijzigde celtoestand door aan de tanh-functie. We vermenigvuldigen de tanh-uitvoer met de sigmoid-uitvoer om te beslissen welke informatie de verborgen toestand moet bevatten. De uitvoer is de verborgen toestand. De nieuwe cel staat en de nieuwe verborgen wordt dan overgedragen aan de volgende keer stap.

om te beoordelen, bepaalt de forget gate wat relevant is om te bewaren van eerdere stappen. De invoerpoort bepaalt welke informatie relevant is om toe te voegen uit de huidige stap. De uitvoerpoort bepaalt wat de volgende verborgen toestand moet zijn.
Code Demo
voor degenen onder u die beter begrijpen door het zien van de code, hier is een voorbeeld met python pseudo code.

1. Eerst worden de vorige verborgen toestand en de huidige invoer samengevoegd. We noemen het combineren.
2. Combineer get ‘ s fed in de forget laag. Deze laag verwijdert niet-relevante gegevens.
4. Een kandidaatlaag wordt gemaakt met combine. De kandidaat heeft mogelijke waarden om toe te voegen aan de celstatus.
3. Combineer ook get ‘ s ingevoerd in de invoerlaag. Deze laag bepaalt welke gegevens van de kandidaat aan de nieuwe celstatus moeten worden toegevoegd.
5. Na het berekenen van de laag vergeten, kandidaatlaag en de invoerlaag, wordt de celstatus berekend met behulp van die vectoren en de vorige celstatus.
6. De output wordt dan berekend.
7. Puntsgewijs vermenigvuldigen van de output en de nieuwe cel staat geeft ons de nieuwe verborgen staat.
dat is het! De control flow van een LSTM netwerk zijn een paar tensor operaties en een for loop. Je kunt de verborgen toestanden gebruiken voor voorspellingen. Door al deze mechanismen te combineren, kan een LSTM kiezen welke informatie relevant is om te onthouden of te vergeten tijdens de sequentieverwerking.
GRU
dus nu weten we hoe een LSTM werkt, laten we kort kijken naar de GRU. De GRU is de nieuwere generatie van terugkerende neurale netwerken en is vrij vergelijkbaar met een LSTM. GRU heeft de celstatus verwijderd en de verborgen status gebruikt om informatie over te dragen. Het heeft ook slechts twee poorten, een reset gate en update gate.

update Gate
de update Gate werkt vergelijkbaar met de forget en input gate van een LSTM. Het besluit welke informatie weg te gooien en welke nieuwe informatie toe te voegen.
Reset Gate
De Reset gate is een andere poort die wordt gebruikt om te bepalen hoeveel informatie uit het verleden te vergeten.
en dat is een GRU. GRU ‘ s heeft minder tensor operaties; daarom zijn ze een beetje sneller te trainen dan LSTM ‘ s. Er is geen duidelijke winnaar welke beter is. Onderzoekers en ingenieurs meestal proberen beide om te bepalen welke beter werkt voor hun use case.
dus dat is het
om dit samen te vatten, RNN ‘ s zijn goed voor het verwerken van sequentiegegevens voor voorspellingen, maar lijdt aan kortetermijngeheugen. LSTM ’s en GRU’ s werden gemaakt als een methode om korte termijn geheugen te beperken met behulp van mechanismen genaamd gates. Gates zijn neurale netwerken die de informatiestroom regelen die door de sequentieketen stroomt. LSTM ’s en GRU’ s worden gebruikt in state of the art deep learning toepassingen zoals spraakherkenning, spraaksynthese, natuurlijke taal begrip, enz.
als u geà nteresseerd bent om dieper in te gaan, hier zijn links van enkele fantastische bronnen die u een ander perspectief kunnen geven in het begrijpen van LSTM ’s en GRU’ s. dit bericht was sterk geïnspireerd door hen.
http://www.wildml.com/2015/10/recurrent-neural-network-tutorial-part-4-implementing-a-grulstm-rnn-with-python-and-theano
http://colah.github.io/posts/2015-08-Understanding-LSTMs/