Lineaire Discriminant Analysis of Normal Discriminant Analysis of Discriminant Function Analysis is een dimensionaliteitsreductietechniek die vaak wordt gebruikt voor de gesuperviseerde classificatieproblemen. Het wordt gebruikt voor het modelleren van verschillen in groepen dat wil zeggen het scheiden van twee of meer klassen. Het wordt gebruikt om de eigenschappen in de ruimte van de hogere dimensie in een ruimte van de lagere dimensie te projecteren.
bijvoorbeeld, we hebben twee klassen en we moeten ze efficiënt scheiden. Klassen kunnen meerdere functies hebben. Het gebruik van slechts een enkele functie om ze te classificeren kan leiden tot enige overlapping zoals weergegeven in de onderstaande figuur. Dus, we zullen blijven verhogen van het aantal functies voor de juiste classificatie.

voorbeeld:
stel dat we twee reeksen gegevenspunten hebben die behoren tot twee verschillende klassen die we willen classificeren. Zoals getoond in de gegeven 2D grafiek, wanneer de gegevenspunten op het 2D vlak worden uitgezet, is er geen rechte lijn die de twee klassen van de gegevenspunten volledig kan scheiden. Daarom wordt in dit geval LDA (Linear Discriminant Analysis) gebruikt die de 2D-grafiek reduceert tot een 1D-grafiek om de scheidbaarheid tussen de twee klassen te maximaliseren.
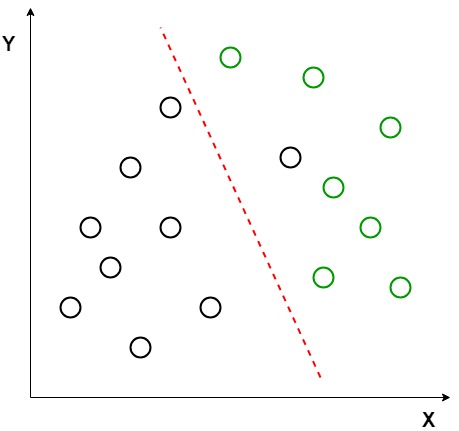
hier gebruikt lineaire Discriminant analyse zowel de assen (X en Y) om een nieuwe as aan te maken en projecteert data op een nieuwe as op een manier om de scheiding van de twee categorieën te maximaliseren en dus de 2D-grafiek te reduceren tot een 1D-grafiek.
twee criteria worden door LDA gebruikt om een nieuwe as te maken:
- Maximaliseer de afstand tussen gemiddelden van de twee klassen.
- minimaliseer de variatie binnen elke klasse.
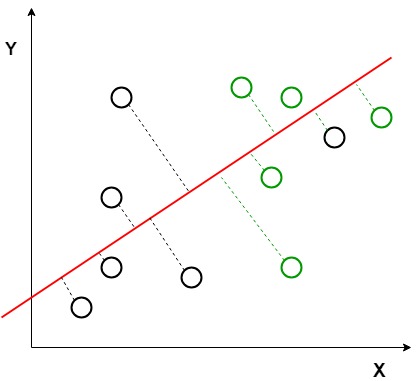
in de bovenstaande grafiek kan worden gezien dat een nieuwe as (in rood) wordt gegenereerd en uitgezet in de 2D-grafiek, zodat deze de afstand tussen de middelen van de twee klassen maximaliseert en de variatie binnen elke klasse minimaliseert. Eenvoudig gezegd vergroot deze nieuw gegenereerde as de scheiding tussen de dtla-punten van de twee klassen. Na het genereren van deze nieuwe as met behulp van de hierboven genoemde criteria, worden alle gegevenspunten van de klassen uitgezet op deze nieuwe AS en worden weergegeven in de onderstaande figuur.

maar Lineaire Discriminant analyse mislukt wanneer het gemiddelde van de distributies wordt gedeeld, omdat het onmogelijk wordt voor LDA om een nieuwe as te vinden die beide klassen lineair scheidbaar maakt. In dergelijke gevallen gebruiken we niet-lineaire discriminantanalyse.
uitbreidingen van LDA:
- kwadratische Discriminant analyse (QDA): Elke klasse gebruikt zijn eigen schatting van variantie (of covariantie wanneer er meerdere invoervariabelen zijn).
- flexibele Discriminant analyse (FDA): waarbij niet-lineaire combinaties van inputs worden gebruikt, zoals splines.
- Regularized Discriminant Analysis (RDA): introduceert regularisatie in de schatting van de variantie (in feite covariantie), waarbij de invloed van verschillende variabelen op LDA wordt gematigd.
toepassingen:
- gezichtsherkenning: Op het gebied van computervisie is gezichtsherkenning een zeer populaire toepassing waarbij elk gezicht wordt vertegenwoordigd door een zeer groot aantal pixelwaarden. Lineaire discriminant analyse (Lda) wordt hier gebruikt om het aantal functies te verminderen tot een meer beheersbaar aantal vóór het classificatieproces. Elk van de gegenereerde nieuwe dimensies is een lineaire combinatie van pixelwaarden, die een sjabloon vormen. De lineaire combinaties verkregen met behulp van Fisher ‘ s lineaire discriminant worden Fisher faces genoemd.
- Medisch: Op dit gebied wordt Lineaire discriminant analyse (Lda) gebruikt om de toestand van de patiënt als mild, matig of ernstig te classificeren op basis van de verschillende parameters van de patiënt en de medische behandeling die hij ondergaat. Dit helpt de artsen om het tempo van hun behandeling te intensiveren of te verminderen.
- klantidentificatie: stel dat we het type klanten willen identificeren dat het meest waarschijnlijk is om een bepaald product in een winkelcentrum te kopen. Door het doen van een eenvoudige vraag en Antwoorden enquãate, kunnen we alle functies van de klanten te verzamelen. Hier, Lineaire discriminant analyse zal ons helpen bij het identificeren en selecteren van de functies die de kenmerken van de groep klanten die het meest waarschijnlijk om dat bepaalde product te kopen in het winkelcentrum kunnen beschrijven.
