VMware High Availability (HA) is een hulpprogramma dat de behoefte aan speciale stand-by hardware en software in een gevirtualiseerde omgeving elimineert. VMware HA wordt vaak gebruikt om de betrouwbaarheid te verbeteren, downtime in virtuele omgevingen te verminderen en disaster recovery/bedrijfscontinuïteit te verbeteren.
Dit hoofdstuk uittreksel uit Vcp4 examen Cram: VMware Certified Professional, 2nd Edition door Elias Khnaser onderzoekt VMware HA best practices.
VMware High Availability gaat voornamelijk over ESX / ESXi host failure en wat er gebeurt met de virtuele machines (VM ‘ s) die op deze host draaien. HA kan ook een VM controleren en herstarten door te controleren of de VMware Tools nog steeds actief zijn. Wanneer een ESX / ESXi host om welke reden dan ook faalt, falen ook alle draaiende VM ‘ s. VMware HA zorgt ervoor dat de VM ‘ s van de mislukte host kunnen worden herstart op andere ESX/ESXi hosts.
veel mensen verwarren VMware HA ten onrechte met fouttolerantie. VMware HA is niet fouttolerant in die zin dat als een host faalt, de VM ‘ s erop ook falen. HA behandelt alleen het herstarten van die VM ‘ s op andere ESX/ESXi hosts met voldoende bronnen. Fouttolerantie, anderzijds, biedt ononderbroken toegang tot middelen in het geval van een storing van de host.
 klik op de afbeelding van de boekomslag hierboven
klik op de afbeelding van de boekomslag hierboven Om Elias Khnaser ‘ s volledige hoofdstuk
over back-up en hoge beschikbaarheid te downloaden.
VMware HA onderhoudt een communicatiekanaal met alle andere ESX/ESXi-hosts die lid zijn van hetzelfde cluster door een hartslag te gebruiken die standaard elke 1 seconde in vSphere 4.0 of elke 10 seconden in vSphere 4.1 wordt verzonden. Wanneer een ESX server een hartslag mist, wachten de andere hosts 15 seconden tot de andere host weer reageert. Na 15 seconden start het cluster de herstart van de VMs op de falende ESX/ESXi-host op de resterende ESX/ESXi-hosts in het cluster. VMware HA houdt ook voortdurend toezicht op de ESX/ESXi-hosts die lid zijn van het cluster en zorgt ervoor dat resources altijd beschikbaar zijn om aan de vereisten te voldoen in het geval van een storing in de host.
bewaking van virtuele Machinefouten
bewaking van virtuele Machinefouten is standaard uitgeschakeld. De functie is om virtuele machines te controleren, die het elke 20 seconden via een hartslag opvraagt. Het doet dit met behulp van de VMware Tools die zijn geïnstalleerd in de VM. Wanneer een VM een hartslag mist, beschouwt VMware HA deze VM als mislukt en probeert deze te resetten. Zie Virtual Machine Failure Monitoring als een soort hoge beschikbaarheid voor VM ‘ s.
Virtual Machine Failure Monitoring kan detecteren of een virtuele machine handmatig is uitgeschakeld, onderbroken of gemigreerd, en probeert daardoor niet opnieuw op te starten.
VMware HA-configuratievereisten
HA vereist de volgende configuratievereisten voordat het goed kan functioneren:
- vCenter: omdat VMware HA een enterprise-class-functie is, vereist het vCenter voordat het kan worden ingeschakeld.
- DNS-resolutie: Alle ESX / ESXi-hosts die lid zijn van het HA-cluster moeten in staat zijn elkaar op te lossen met DNS.
- toegang tot gedeelde opslag: alle hosts in het HA-cluster moeten toegang en zichtbaarheid hebben tot dezelfde gedeelde opslag; anders zouden ze geen toegang hebben tot de VMs.
- toegang tot hetzelfde netwerk: Alle ESX / ESXi hosts moeten dezelfde netwerken hebben geconfigureerd op alle hosts, zodat wanneer een VM wordt herstart op elke host, het weer toegang heeft tot het juiste netwerk.
redundantie van de Serviceconsole
De aanbevolen praktijk bepaalt dat de Serviceconsole (SC) redundantie heeft. VMware HA klaagt en geeft een waarschuwing als het detecteert dat de Service Console is geconfigureerd op een vSwitch met slechts één vmnic. Zoals figuur 1 laat zien, kunt u redundantie van de Serviceconsole op twee manieren configureren:
- maak twee serviceconsole-poortgroepen aan, elk op een andere vSwitch.
- wijs twee fysieke netwerkkaarten (Nic ‘ s) in de vorm van een NIC-team toe aan de Serviceconsole vSwitch.
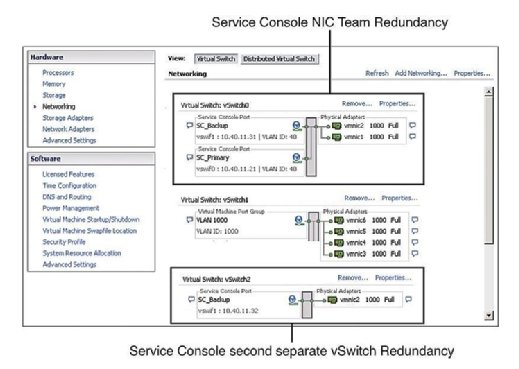
in beide gevallen moet u de gehele IP-stack configureren met IP-adres, subnet en gateway. De Service Console vSwitches worden gebruikt voor hartslagen en statussynchronisatie en gebruiken de volgende poorten:
- Inkomende TCP-poort 8042
- Inkomende UDP-poort 8045
- Uitgaande TCP-poort 2050
- Uitgaande UDP-poort 2250
- Inkomende TCP-poort 8042-8045
- Inkomende UDP-poort 8042-8045
- Uitgaande TCP-poort 2050-2250
- Uitgaande UDP-poort 2050-2250
het Nalaten te configureren SC redundantie resulteert in een waarschuwing weergegeven wanneer u het inschakelt HA. Dus, om te voorkomen dat het zien van deze foutmelding en om zich te houden aan de beste praktijken, configureer de SC redundant.
host failover capacity planning
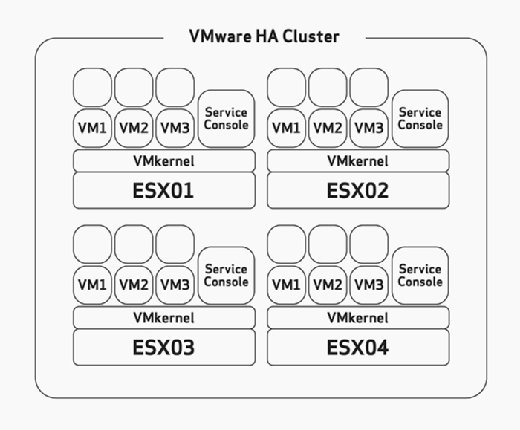
wanneer u HA configureert, moet u handmatig de maximale host failover tolerantie configureren. Dit is een taak die u zorgvuldig moet overwegen tijdens de hardware sizing en planning fase van uw implementatie. Dit zou ervan uitgaan dat je je ESX / ESXi hosts hebt gebouwd met genoeg middelen om meer VM ‘ s te draaien dan gepland om HA te kunnen accommoderen. Merk bijvoorbeeld in Figuur 2 op dat het HA-cluster vier ESX-hosts heeft en dat alle vier deze hosts voldoende capaciteit hebben om ten minste drie VM ‘ s meer te draaien. Omdat ze allemaal al drie VM ’s draaien, betekent dit dat dit cluster het verlies van twee ESX/ESXi-hosts kan veroorloven, omdat de resterende twee ESX/ESXi-hosts de zes mislukte VM’ s zonder probleem kunnen inschakelen als er een storing optreedt.
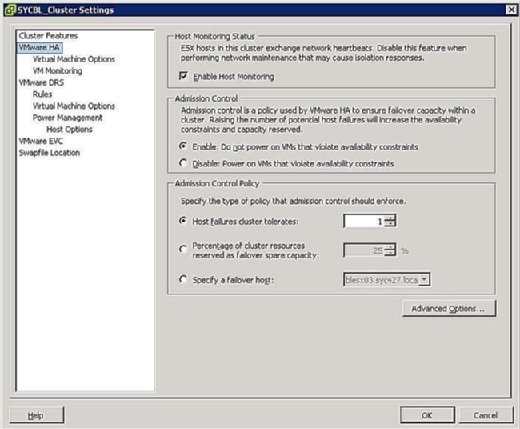
tijdens de configuratiefase van het HA-cluster krijgt u een scherm te zien dat vergelijkbaar is met het scherm in Figuur 3 dat u vraagt om twee clusterbrede configuraties als volgt te definiëren:
- host Monitoring Status:
- host Monitoring inschakelen: met deze instelling kunt u bepalen of het HA-cluster de hosts moet controleren op een hartslag. Dit is de manier waarop het cluster bepaalt of een host nog actief is. In sommige gevallen, wanneer u onderhoudstaken uitvoert op ESX/ESXi-hosts, kan het wenselijk zijn om deze optie uit te schakelen om te voorkomen dat een host wordt geïsoleerd.
- Toelatingscontrole:
- inschakelen: niet inschakelen op VM ‘ s die de beschikbaarheidsbeperkingen schenden: Als u deze optie selecteert, geeft dit aan dat als er geen bronnen beschikbaar zijn om aan een VM te voldoen, deze niet moet worden ingeschakeld.
- Disable: VM ‘ s inschakelen die de beschikbaarheidsbeperkingen schenden: als u deze optie selecteert, geeft u aan dat u een VM moet inschakelen, zelfs als u middelen overcommit.
- Admission Control Policy:
- host failures cluster tolereert: met deze instelling kunt u instellen hoeveel host failures u wilt tolereren. De toegestane instellingen zijn 1 tot en met 4.
- Percentage clusterbronnen gereserveerd als reservecapaciteit voor failover: Als u deze optie selecteert, wordt aangegeven dat u een percentage reserveert van de totale clusterbronnen in reserve voor failover. In een cluster met vier hosts geeft een reservering van 25% aan dat u een volledige host reserveert voor failover. Als u minder wilt reserveren, kunt u in plaats daarvan 10% van de clusterbronnen kiezen.
- Geef een failover-host op: Als u deze optie selecteert, geeft u aan dat u een bepaalde host selecteert als de failover-host in het cluster. Dit kan het geval zijn als je een reserve host hebt of een bepaalde host die aanzienlijk meer Reken-en geheugenbronnen beschikbaar heeft.
hostisolatie
een netwerkverschijnsel dat bekend staat als een split-brain treedt op wanneer de ESX/ESXi host geen hartslag meer ontvangt van de rest van het cluster. De hartslag wordt elke seconde in vSphere 4.0 of 10 seconden in vSphere 4.1 opgevraagd. Als er geen antwoord wordt ontvangen, denkt het cluster dat de ESX/ESXi-host is mislukt. Wanneer dit gebeurt, heeft de ESX/ESXi host zijn netwerkconnectiviteit verloren op zijn beheerinterface. De host kan nog steeds actief zijn en de VM ‘ s kunnen zelfs niet worden beà nvloed aangezien ze een andere netwerkinterface gebruiken die niet is beà nvloed. Echter, vSphere moet actie ondernemen wanneer dit gebeurt omdat het gelooft dat een host heeft gefaald. Wat dat betreft, de gastheer isolatie reactie werd gecreëerd. Host isolation response is HA ‘ S manier om om te gaan met een ESX/ESXi host die zijn netwerkverbinding heeft verloren.
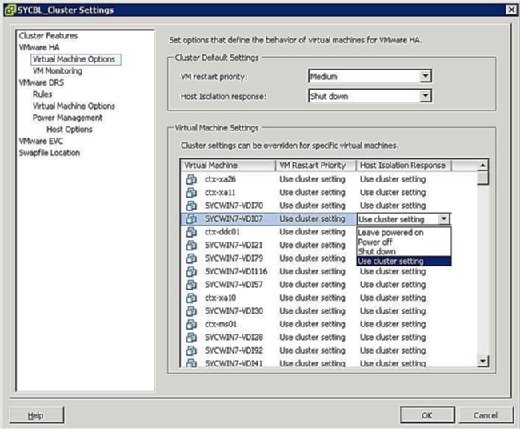
u kunt bepalen wat er gebeurt met VMs in het geval van een host isolatie. Klik met de rechtermuisknop op het cluster in kwestie en klik op Instellingen bewerken om naar het scherm VM-Isolatierespons te gaan. U kunt vervolgens klikken op virtuele Machine opties onder de VMware HA banner in het linkerdeelvenster. U kunt opties clusterwide beheren door de host isolation response optie dienovereenkomstig in te stellen. Dit wordt toegepast op alle VM ‘ s op de getroffen host. Dat gezegd hebbende, kunt u altijd de clusterinstellingen overschrijven door een ander antwoord op VM-niveau te definiëren.
zoals weergegeven in Figuur 4, zijn uw Isolatieresponsopties als volgt:
- laat ingeschakeld: zoals het label impliceert, betekent deze instelling dat in het geval van hostisolatie de VM ingeschakeld blijft.
- Power Off: deze instelling definieert dat in het geval van een isolatie, de VM wordt uitgeschakeld. Dit is een harde uitschakeling.
- Shut down: deze instelling definieert dat in het geval van een isolatie, de VM gracieus wordt afgesloten met behulp van VMware Tools. Als deze taak niet binnen vijf minuten met succes is voltooid, wordt onmiddellijk een power off uitgevoerd. Als VMware Tools niet is geïnstalleerd, wordt in plaats daarvan een power off uitgevoerd.
- gebruik Clusterinstelling: deze instelling stuurt de taak door naar de clusterbrede instelling die is gedefinieerd in het eerder in Figuur 4 getoonde venster.
in het geval van een isolatie betekent dit niet noodzakelijk dat de host down is. Omdat de VM ’s geconfigureerd kunnen worden met verschillende fysieke Nic’ s en verbonden kunnen worden met verschillende netwerken, kunnen ze goed blijven functioneren; daarom moet u hiermee rekening houden bij het instellen van de prioriteit voor isolatie. Wanneer een host geïsoleerd is, betekent dit simpelweg dat de Serviceconsole niet kan communiceren met de rest van de ESX/ESXi hosts in het cluster.
virtual machine recovery priority
als uw HA-cluster niet in staat is om alle VM ’s te verwerken in het geval van een storing, hebt u de mogelijkheid om prioriteit te geven aan VM’ s. De prioriteiten bepalen welke VM ’s als eerste worden herstart en welke VM’ s niet zo belangrijk zijn in geval van nood. Deze opties worden geconfigureerd op hetzelfde scherm als de Isolatierespons die in de vorige sectie is behandeld. U kunt clusterbrede instellingen configureren die worden toegepast op alle VM ‘ s op de betreffende host, of u kunt de clusterinstellingen overschrijven door een overschrijving op VM-niveau te configureren.
u kunt de herstartprioriteit van een VM instellen op een van de volgende:
- hoog: VM ‘ s met een hoge prioriteit worden eerst opnieuw gestart.
- Medium: Dit is de standaardinstelling.
- laag: VM ‘ s met een lage prioriteit worden als laatste herstart.
- gebruik Clusterinstelling: VM ‘ s worden opnieuw gestart op basis van de instelling die is gedefinieerd op clusterniveau die is gedefinieerd in het venster dat in de onderstaande afbeelding wordt weergegeven.
- uitgeschakeld: de VM staat niet aan.
de prioriteit moet worden bepaald op basis van het belang van de VMs. Met andere woorden, misschien wilt u domeincontrollers herstarten en niet afdrukservers herstarten. De virtuele machines met hogere prioriteit worden eerst opnieuw gestart. VM ‘ s die kunnen verdragen dat ze in geval van nood uitgeschakeld blijven, moeten zo worden geconfigureerd dat ze uitgeschakeld blijven om hulpbronnen te besparen.
MSCS clustering
Het hoofddoel van een cluster is ervoor te zorgen dat kritieke systemen tegen elke prijs en te allen tijde online blijven. Net als fysieke machines die geclusterd kunnen worden, kunnen virtuele machines ook geclusterd worden met ESX met behulp van drie verschillende scenario ‘s:
- Cluster-in-a-box: In dit scenario bevinden alle VM’ s die deel uitmaken van het cluster zich op dezelfde ESX/ESXi-host. Zoals je misschien al geraden hebt, creëert dit onmiddellijk een enkel foutpunt: de ESX / ESXi host. Wat gedeelde opslag betreft, kunt u virtuele schijven gebruiken als gedeelde opslag in dit scenario, of u kunt Raw Device Mapping (RDM) gebruiken in de modus virtuele Compatibiliteit.
- Cluster-across-boxes: In dit scenario bevinden de clusterknooppunten (VM ‘ s die lid zijn van het cluster) zich op meerdere ESX/ESXi-hosts, waarbij elk van de knooppunten die deel uitmaken van het cluster toegang heeft tot dezelfde opslag, zodat als een VM faalt, de andere kan blijven functioneren en toegang heeft tot dezelfde gegevens. Dit scenario creëert een ideale clusteromgeving door een enkel storingspunt te elimineren. Gedeelde opslag is hierbij een voorwaarde en moet zich bevinden op Fibre Channel SAN. U moet ook een RDM gebruiken in de fysieke of virtuele compatibiliteitsmodus, omdat virtuele schijven geen ondersteunde configuratie zijn voor gedeelde opslag. Waarbij elk van de knooppunten die deel uitmaken van het cluster toegang heeft tot dezelfde opslag, zodat als een VM faalt, de andere kan blijven functioneren en toegang heeft tot dezelfde gegevens.
- fysiek-naar-virtueel cluster: In dit scenario is één lid van het cluster een virtuele machine, terwijl het andere Lid een fysieke machine is. Gedeelde opslag is een voorwaarde in dit scenario en moet worden geconfigureerd als een RDM in de modus fysieke Compatibiliteit.
wanneer u een clusteringsoplossing ontwerpt, moet u het probleem van gedeelde opslag aanpakken, waardoor meerdere hosts of VMs toegang krijgen tot dezelfde gegevens. vSphere biedt verschillende methoden waarmee u gedeelde opslag als volgt kunt bieden:
- virtuele schijven: U kunt een virtuele schijf alleen gebruiken als een gedeeld opslaggebied als u clustering doet in een box-met andere woorden, alleen als beide VM ‘ s zich op dezelfde ESX/ESXi-host bevinden.
- RDM in fysieke compatibiliteitsmodus: met deze modus kunt u een fysiek LUN rechtstreeks aan een VM of fysieke machine koppelen. Deze modus voorkomt dat U functionaliteit zoals snapshots kunt gebruiken en wordt ideaal gebruikt wanneer het ene lid van het cluster een fysieke machine is en het andere een VM is.
- RDM in Virtual Compatibility Mode: Deze modus stelt u in staat om een fysiek LUN direct aan een VM of fysieke machine te koppelen. Deze modus biedt u alle voordelen van virtuele schijven die op VMFS worden uitgevoerd, inclusief snapshots en geavanceerde bestandsvergrendeling. De schijf is toegankelijk via de hypervisor en is ideaal bij het configureren van een cluster-across-boxes-scenario waarbij u beide VMs toegang moet geven tot gedeelde opslag.
op het moment van schrijven is Microsoft Clustering Services (MSCS) de enige door VMware ondersteunde clustering-service. U kunt de VMware whitepaper “instellingen voor Failover Clustering en Microsoft Cluster Service raadplegen.”
VMware fouttolerantie
VMware fouttolerantie (FT) is een andere vorm van VM-clustering ontwikkeld door VMware voor systemen die extreme uptime vereisen. Een van de meest dwingende kenmerken van FT is het gemak van de installatie. FT is gewoon een selectievakje dat kan worden ingeschakeld. In vergelijking met traditionele clustering die specifieke configuraties en in sommige gevallen bekabeling vereist, is FT eenvoudig maar krachtig.
Hoe werkt het?
wanneer VM ‘ s met FT worden beschermd, wordt een secundaire VM gemaakt in lockstep van de beschermde VM, de eerste VM. FT werkt door tegelijkertijd naar de eerste VM en de tweede VM te schrijven. Elke taak wordt twee keer geschreven. Als u op het menu Start van de eerste VM klikt, wordt ook op het menu Start van de tweede VM geklikt. De kracht van FT is de mogelijkheid om beide VM ‘ s synchroon te houden.
als de beschermde VM om welke reden dan ook uitvalt, neemt de secundaire VM onmiddellijk zijn plaats in, neemt zijn identiteit en zijn IP-adres in beslag en blijft gebruikers zonder onderbreking onderhouden. De nieuw gepromote beschermde VM maakt dan een secundaire voor zichzelf op een andere host en de cyclus herstart.
ter verduidelijking, laten we een voorbeeld bekijken. Als u een Exchange server wilt beschermen, kunt u FT inschakelen. Als Om welke reden dan ook de ESX/ESXi-host die de beschermde VM draagt faalt, treedt de secundaire VM in werking en neemt zijn taken op zich zonder onderbreking in de dienst.
de tabel hieronder schetst de verschillende high Availability en clustering technologieën waartoe u toegang hebt met vSphere en belicht de beperkingen van elk.

Fouttolerantievereisten
fouttolerantie verschilt niet van alle andere bedrijfskenmerken, omdat het vereist dat aan bepaalde voorwaarden wordt voldaan voordat de technologie goed en efficiënt kan functioneren. Deze vereisten worden in de volgende lijst beschreven en onderverdeeld in de verschillende categorieën waarvoor specifieke minimumeisen vereist zijn:
- hostvereisten:
- FT-compatibele CPU. Bekijk dit VMware KB artikel voor meer informatie.
- Hardware virtualisatie moet ingeschakeld zijn in het bios.
- de CPU kloksnelheden van de Host moeten binnen 400 MHz van elkaar liggen.
- VM-vereisten:
- VM ‘ s moeten zich bevinden op ondersteunde gedeelde opslag (FC, iSCSI en NFS).
- VMs moet een ondersteund besturingssysteem draaien.
- VM ‘ s moeten worden opgeslagen in een VMDK of een virtuele RDM.
- VM ‘ s kunnen geen dun provisioned VMDK hebben en moeten een Egerzeroedthick virtuele schijf gebruiken.
- VM ‘ s kunnen niet meer dan één vCPU hebben geconfigureerd.
- clustervereisten:
- alle ESX / ESXi-hosts moeten dezelfde versie en hetzelfde patchniveau hebben.
- alle ESX / ESXi hosts moeten toegang hebben tot de VM datastores en netwerken.
- VMware HA moet ingeschakeld zijn op het cluster.
- elke host moet een vMotion en FT Logging NIC hebben geconfigureerd.
- controle van Hostcertificaten moet ook worden ingeschakeld.
Het is zeer aan te raden dat u, naast het controleren van processorcompatibiliteit met FT, de merk-en modelcompatibiliteit van uw server met FT controleert aan de hand van de VMware Hardware Compatibility List (HCL).
hoewel FT een geweldige clustering oplossing is, is het belangrijk op te merken dat het ook bepaalde beperkingen heeft. Bijvoorbeeld, FT VM ‘ s kunnen niet worden snapshoted, en ze kunnen niet worden opgeslagen Vmotioned. In feite worden deze VM ‘ s automatisch gemarkeerd met DRS-Disabled en nemen ze niet deel aan dynamische taakverdeling van bronnen.
hoe ft
inschakelen van FT is niet moeilijk, maar het vereist wel het configureren van een paar verschillende instellingen. De volgende instellingen moeten correct worden geconfigureerd om FT te laten werken:
- controle van Hostcertificaten inschakelen: Om deze instelling in te schakelen, logt u in op uw vCenter server en klikt u op Beheer in het menu Bestand en klikt u op vCenter Server Instellingen. Klik in het linkerdeelvenster op SSL-instellingen en vink de Vcenter vereist geverifieerde Host SSL-certificaten doos.
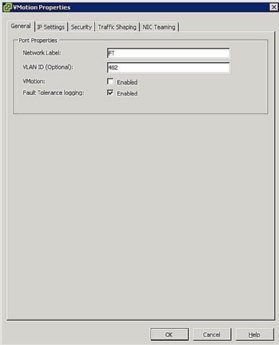
Figuur 5. FT poort groep instellingen - host Netwerk configureren: De netwerkconfiguratie voor FT is eenvoudig en volgt dezelfde stappen en procedures als vMotion, behalve in plaats van het vakje vMotion aan te vinken, vinkt u het Logboekvak fouttolerantie aan zoals weergegeven in Figuur 5.
- Ft in – en uitschakelen: Als u aan de voorgaande vereisten hebt voldaan, kunt u FT nu in-en uitschakelen voor VMs. Dit proces is ook eenvoudig: Zoek de VM die u wilt beschermen, klik er met de rechtermuisknop op en selecteer fouttolerantie>schakel fouttolerantie in.
hoewel FT een eerste generatie clustering technologie is, werkt het indrukwekkend goed en vereenvoudigt het overcompliceerde traditionele methoden voor het bouwen, configureren en onderhouden van clusters. FT is een indrukwekkende technologie voor een uptime standpunt en vanuit een naadloze failover standpunt.