in lineaire regressie kunt u categorische variabelen niet gemakkelijk als voorspellers gebruiken: U moet ze opsplitsen in dichotome variabelen, zogenaamde dummy variabelen.
de ideale manier om deze te maken is ons dummy variabelen Gereedschap. Als u deze tool niet wilt gebruiken, dan toont deze tutorial de juiste manier om het handmatig te doen.
- voorbeeld I – Elke numerieke variabele
- voorbeeld II – numerieke variabele met aangrenzende gehele getallen
- voorbeeld III – String variabele met conversie
- voorbeeld IV-String variabele zonder conversie
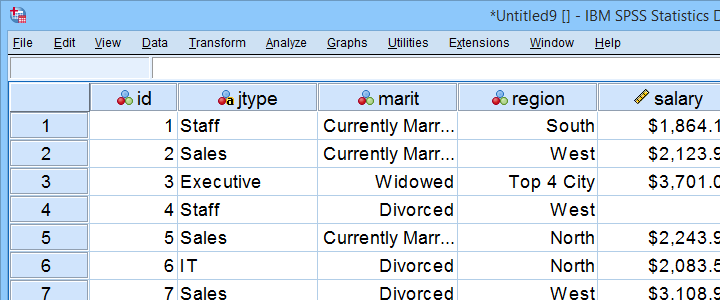
voorbeeld gegevensbestand
Deze tutorial gebruikt notenbalk.sav overal. Een deel van dit gegevensbestand wordt hieronder weergegeven.
voorbeeld I – Elke numerieke variabele
laten we eerst dummy variabelen maken voor marit, kort voor burgerlijke staat. Onze eerste stap is het uitvoeren van een BASISFREQUENTIETABEL metfrequenties marit.De tabel hieronder toont de resulterende tabel.
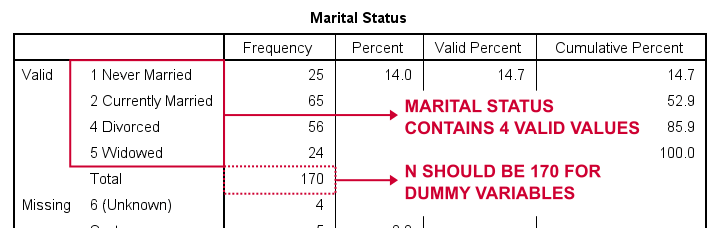
dus hoe de burgerlijke staat op te splitsen in dummy variabelen? Ten eerste laten we altijd één categorie Weg, de referentiecategorie. U kunt elke categorie als referentiecategorie kiezen.
dus voor dit voorbeeld kiezen we 5 (weduwnaar). Dit houdt in dat we 3 dummy variabelen creëren die de categorieën 1, 2 en 4 vertegenwoordigen (merk op dat 3 niet voorkomt in deze variabele).
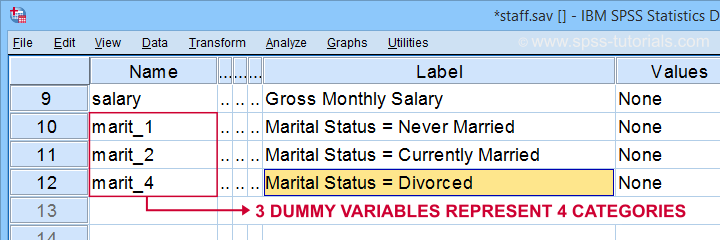
onderstaande syntaxis laat zien hoe u onze 3 dummy variabelen kunt aanmaken en labelen. Laten we het natrekken.
bereken marit_1 =(marit = 1).
bereken marit_2 = (marit = 2).
bereken marit_4 =(marit = 4).
* variabele labels toepassen op dummy variabelen.
variabele labels
marit_1 ‘ Burgerlijke staat = nooit gehuwd ‘
marit_2’Burgerlijke staat = momenteel Gehuwd ‘
marit_4’Burgerlijke staat = Gescheiden’.
* Quick check first dummy variabele
frequenties marit_1.
Results
ten eerste, merk op dat we 3 mooi gelabelde dummy variabelen hebben aangemaakt in onze actieve dataset.
de tabel hieronder toont de frequentieverdeling voor onze eerste dummy variabele.

merk op dat onze dummy variabele 3 verschillende waarden heeft:
- respondenten met een burgerlijke staat die niet” nooit getrouwd “is score 0;
- respondenten met een burgerlijke staat die” nooit getrouwd ” is score 1;
- respondenten met een burgerlijke staat die een ontbrekende waarde (en daarom onbekend) heeft, hebben een systeem ontbrekende waarde.
We kunnen nu de resultaten grondiger controleren door te runningcrosstabs marit door marit_1 naar marit_4.Hierdoor ontstaan 3 contingency tables, waarvan de eerste hieronder wordt weergegeven.
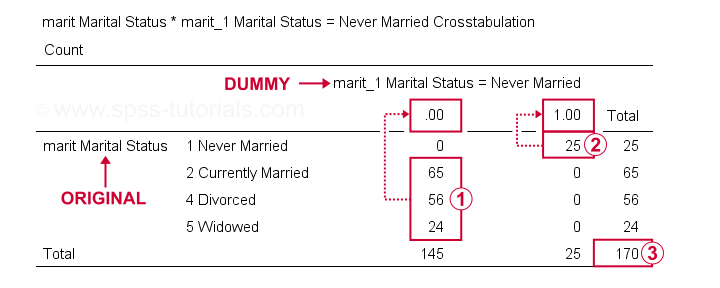
op onze dummy variabele, respondenten met een andere burgerlijke status dan “never married” all score 0;
respondenten met een andere burgerlijke status dan “never married” all score 0; respondenten die “never married” all score 1;
respondenten die “never married” all score 1; we hebben een steekproefgrootte van n = 170 (deze tabel bevat alleen respondenten zonder ontbrekende waarden op een van beide variabelen).
we hebben een steekproefgrootte van n = 170 (deze tabel bevat alleen respondenten zonder ontbrekende waarden op een van beide variabelen).
optioneel is een laatste-zeer grondige-controle om de ANOVA-resultaten voor de oorspronkelijke variabele te vergelijken met de regressieresultaten met behulp van onze dummy-variabelen. De syntaxis hieronder doet precies dat, met behulp van maandsalaris als de afhankelijke variabele.
regressie
/ afhankelijk salaris
/ methode voer marit_1 in tot marit_4.
*minimale ANOVA met originele variabele.een salaris van marit.
merk op dat beide analyses resulteren in identieke ANOVA-tabellen. We bespreken ANOVA versus dummy variabele regressie grondiger in een toekomstige tutorial.
voorbeeld II-numerieke variabele met aangrenzende gehele getallen
We maken nu dummy variabelen voor regio. Nogmaals, we beginnen met het inspecteren van een minimale frequentie tabel die we zullen maken door runningfrequencies regio.Dit resulteert in de onderstaande tabel.
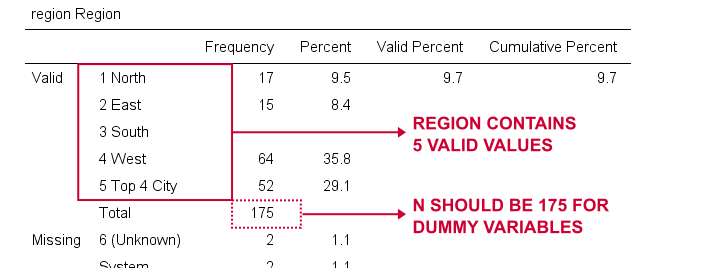
We kiezen 1 (“North”) als onze referentie categorie. We zullen daarom dummy variabelen maken voor de categorieën 2 tot en met 5. Aangezien dit aangrenzende gehele getallen zijn, kunnen we dingen versnellen door DO REPEAT te gebruiken zoals hieronder getoond.
recode regio (#vals = 1) (lo thru hi = 0) in #vars.
einde herhaling.
* variabele labels toepassen op nieuwe variabelen.
variabele labels
region_2 “Region = East”
region_3 “Region = South”
region_4 “Region = West”
region_5 “Region = Top 4 City”.
*Snelle controle.
crosstabs region by region_2 to region_5.
een zorgvuldige inspectie van de resulterende tabellen bevestigt dat alle resultaten correct zijn.
voorbeeld III – String variabele met conversie
helaas werken onze eerste 2 methoden niet voor string variabelen zoals jtype-kort voor “job type”). De eenvoudigste oplossing is om het om te zetten in een numerieke variabele zoals besproken in SPSS Convert String naar numerieke variabele. De syntaxis hieronder gebruikt AUTORECODE om de klus te klaren.
autorecode jtype
/ naar njtype.
* Controleer resultaat.
frequenties njtype.
* stel ontbrekende waarden in.
ontbrekende waarden njtype (1,2).
* controleer het resultaat opnieuw.
frequenties njtype.
resultaat

aangezien njtype-kort voor” numeric job type ” – Een numerieke variabele is, kunnen we nu methode I of methode II gebruiken om deze op te splitsen in dummy variabelen.
voorbeeld IV-String variabele zonder conversie
het converteren van string variabelen naar numerieke variabelen is de eenvoudig te maken dummy variabelen voor hen. Zonder deze conversie is het proces omslachtig omdat SPSS ontbrekende waarden voor stringvariabelen niet goed verwerkt. Echter, syntaxis hieronder krijgt de klus correct gedaan.
frequenties jtype.
*kans ‘(onbekend) ‘ in ‘NA’.
recode jtype (‘(Unknown) ‘ = ‘NA’).
* stel ontbrekende waarden in voor de gebruiker.
ontbrekende waarden jtype ( ” , ‘NA’).
* frequenties opnieuw controleren.
frequenties jtype.
* Maak dummy variabelen voor string variabele.
if(niet ontbrekend (jtype)) jtype_1 = (jtype = ‘IT’).
if(niet ontbrekend (jtype)) jtype_2 = (jtype = ‘Management’).
if(niet ontbrekend (jtype)) jtype_3 = (jtype = ‘Sales’).
if(niet ontbrekend (jtype)) jtype_4 = (jtype = ‘notenbalk’).
* variabele labels toepassen op dummy variabelen.
variabele labels
jtype_1 ‘ Job type = IT ‘
jtype_2’Job type = Management ‘
jtype_3’Job type = Sales ‘
jtype_4’Job type = Staff’.
* controleer de resultaten.
kruist jtype door jtype_1 naar jtype_4.
eindnoten
het maken van dummy variabelen voor numerieke variabelen kan snel en gemakkelijk worden gedaan. Het instellen van de juiste variabele labels vergt echter altijd een beetje werk. String variabelen vereisen een aantal extra stap (s), maar zijn vrij goed te doen.
niettemin is de makkelijkste optie ons SPSS Create Dummy Variables Tool omdat het perfect voor alles zorgt.