door William W Wold
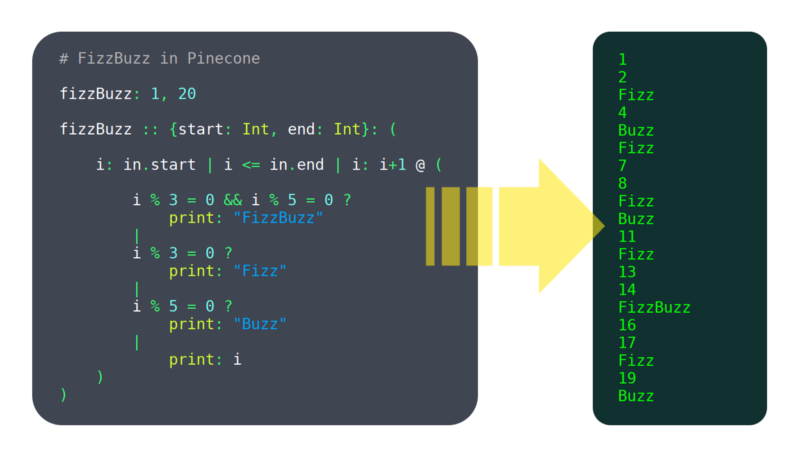
De afgelopen 6 maanden heb ik gewerkt aan een programmeertaal genaamd Pinecone. Ik zou het nog niet volwassen noemen, maar het heeft al genoeg functies die werken om bruikbaar te zijn, zoals:
- variabelen
- functies
- door de gebruiker gedefinieerde structuren
als je hierin geïnteresseerd bent, bekijk dan Pinecone ‘ s landing page of zijn GitHub repo.
Ik ben geen expert. Toen ik met dit project begon, had ik geen idee wat ik aan het doen was, en dat doe ik nog steeds niet. Ik heb nul lessen over taalcreatie gevolgd, heb er maar een beetje over gelezen online, en heb niet veel van het advies dat ik heb gekregen opgevolgd.
en toch heb ik een volledig nieuwe taal gemaakt. En het werkt. Dus ik moet iets goed doen.
In dit bericht zal ik onder de motorkap duiken en je de pijplijn laten zien die Pinecone (en andere programmeertalen) gebruikt om broncode in magie te veranderen.
Ik zal ook ingaan op een aantal van de afwegingen die ik heb gemaakt, en waarom ik de beslissingen die ik heb gemaakt.
Dit is geenszins een volledige tutorial over het schrijven van een programmeertaal, maar het is een goed startpunt als je nieuwsgierig bent naar taalontwikkeling.
aan de slag
“Ik heb absoluut geen idee waar ik zou beginnen” is iets wat ik veel hoor als ik andere ontwikkelaars vertel dat ik een taal aan het schrijven ben. In het geval dat je reactie, Ik zal nu gaan door een aantal eerste beslissingen die worden gemaakt en stappen die worden genomen bij het starten van een nieuwe taal.
gecompileerd vs geïnterpreteerd
Er zijn twee belangrijke talen: gecompileerd en geïnterpreteerd:
- een compiler zoekt uit wat een programma zal doen, verandert het in “machine code” (een formaat dat de computer heel snel kan draaien), en slaat dat vervolgens op om later uit te voeren.
- een interpreter gaat regel voor regel door de broncode, om uit te zoeken wat hij doet terwijl hij bezig is.
technisch gezien kan elke taal worden gecompileerd of geïnterpreteerd, maar de ene of de andere is meestal zinvoller voor een specifieke taal. Over het algemeen is interpreteren meestal flexibeler, terwijl compileren meestal hogere prestaties heeft. Maar dit is slechts het krassen van de oppervlakte van een zeer complex onderwerp.
Ik hecht veel waarde aan prestaties, en ik zag een gebrek aan programmeertalen die zowel hoge prestaties als eenvoud-georiënteerd zijn, dus ging ik voor compiled for Pinecone.
Dit was een belangrijke beslissing om in een vroeg stadium te nemen, omdat veel beslissingen over taalontwerp erdoor worden beïnvloed (bijvoorbeeld, statisch typen is een groot voordeel voor gecompileerde talen, maar niet zozeer voor geïnterpreteerde talen).
ondanks het feit dat Pinecone ontworpen was met compileren in gedachten, heeft het een volledig functionele interpreter die de enige manier was om het een tijdje te draaien. Daar zijn een aantal redenen voor, die ik later zal toelichten.
het kiezen van een taal
Ik weet dat het een beetje meta is, maar een programmeertaal is zelf een programma, en dus moet je het in een taal schrijven. Ik koos voor C++ vanwege zijn prestaties en grote feature set. Ook vind ik het leuk om in C++te werken.
als u een geà nterpreteerde taal aan het schrijven bent, heeft het veel zin om deze in een gecompileerde taal te schrijven (zoals C, C++ of Swift) omdat de prestaties die verloren gaan in de taal van uw interpreter en de interpreter die uw interpreter interpreteert, gecompileerd zullen worden.
Als u van plan bent om te compileren, is een langzamere taal (zoals Python of JavaScript) acceptabeler. Compilatietijd kan slecht zijn, maar naar mijn mening is dat lang niet zo ‘ n grote deal als slechte runtime.
ontwerp op hoog niveau
een programmeertaal is over het algemeen gestructureerd als een pijplijn. Dat wil zeggen, het heeft verschillende fasen. Elke fase heeft gegevens geformatteerd op een specifieke, goed gedefinieerde manier. Het heeft ook functies om gegevens te transformeren van elke fase naar de volgende.
de eerste fase is een string die het volledige invoerbronbestand bevat. De laatste fase is iets dat kan worden uitgevoerd. Dit zal allemaal duidelijk worden als we stap voor stap door de Dennenappelpijplijn gaan.
Lexing

de eerste stap in de meeste programmeertalen is Lexen of tokeniseren. ‘Lex’ is een afkorting voor lexicale analyse, een heel mooi woord voor het opsplitsen van een bos tekst in tokens. Het woord ’tokenizer ‘is een stuk logischer, maar’ lexer ‘ is zo leuk om te zeggen dat ik het toch gebruik.
Tokens
een token is een kleine eenheid van een taal. Een token kan een variabele of functienaam (ook bekend als een identifier), een operator of een nummer zijn.
taak van de Lexer
De lexer wordt verondersteld een string in te nemen die een volledige broncode bevat en een lijst uit te spuwen die elk token bevat.
toekomstige stadia van de pijplijn verwijzen niet naar de oorspronkelijke broncode, dus de lexer moet alle informatie produceren die nodig is. De reden voor deze relatief strikte pipeline-indeling is dat de lexer taken kan uitvoeren zoals het verwijderen van opmerkingen of het detecteren als iets een nummer of identifier is. Je wilt die logica opgesloten houden in de lexer, beide zodat je niet hoeft na te denken over deze regels bij het schrijven van de rest van de taal, en zodat je dit type syntaxis allemaal op één plaats kunt veranderen.
Flex
de dag dat ik de taal begon, was het eerste wat ik schreef een eenvoudige lexer. Kort daarna, begon ik te leren over tools die zogenaamd lexing eenvoudiger zou maken, en minder buggy.
Het belangrijkste is Flex, een programma dat lexers genereert. Je geeft het een bestand met een speciale syntaxis om de grammatica van de taal te beschrijven. Daaruit genereert het een C programma dat een string lext en de gewenste output produceert.
mijn beslissing
Ik koos ervoor om de lexer die ik schreef voorlopig te behouden. Uiteindelijk zag ik geen significante voordelen van het gebruik van Flex, althans niet genoeg om het toevoegen van een afhankelijkheid te rechtvaardigen en het bouwproces te compliceren.
mijn lexer is slechts een paar honderd regels lang, en geeft me zelden problemen. Het draaien van mijn eigen lexer geeft me ook meer flexibiliteit, zoals de mogelijkheid om een operator toe te voegen aan de taal zonder meerdere bestanden te bewerken.
Parsing

de tweede fase van de pijplijn is de parser. De parser verandert een lijst van tokens in een boom van knooppunten. Een boom die wordt gebruikt voor het opslaan van dit type gegevens staat bekend als een abstracte syntaxis boom, of AST. Tenminste in Dennenappel heeft de AST geen informatie over typen of welke identifiers welke zijn. Het is gewoon gestructureerde tokens.
Parser taken
de parser voegt structuur toe aan de geordende lijst van tokens die lexer produceert. Om dubbelzinnigheden te stoppen, moet de parser rekening houden met haakjes en de volgorde van bewerkingen. Gewoon parsing operators is niet erg moeilijk, maar als meer taalconstructies worden toegevoegd, parsing kan zeer complex worden.
Bison
opnieuw was er een beslissing om te maken met een bibliotheek van derden. De belangrijkste parsing bibliotheek is Bizon. Bison werkt net als Flex. U schrijft een bestand in een aangepast formaat dat de grammatica-informatie opslaat, dan Bison gebruikt dat Voor het genereren van een C-programma dat uw parsing zal doen. Ik koos er niet voor Bizon te gebruiken.
waarom aangepast beter is
met de lexer was de beslissing om mijn eigen code te gebruiken vrij duidelijk. Een lexer is zo ’n triviaal programma dat het niet schrijven van mijn eigen voelde bijna net zo dom als het niet schrijven van mijn eigen’links-pad’.
met de parser is het een andere zaak. Mijn Dennenappel parser is momenteel 750 regels lang, en ik heb drie van hen geschreven omdat de eerste twee waren prullenbak.
Ik heb mijn beslissing oorspronkelijk genomen om een aantal redenen, en hoewel het niet helemaal soepel is verlopen, zijn de meeste van hen waar. De belangrijkste zijn als volgt:
- minimaliseer context switching in workflow: context switching tussen C++ en Pinecone is al erg genoeg zonder het toevoegen van Bison ‘ s grammatica grammatica
- houd build simple: elke keer dat de grammatica verandert moet Bison worden uitgevoerd voordat de build. Dit kan worden geautomatiseerd, maar het wordt een pijn bij het schakelen tussen bouwsystemen.
- ik vind het leuk om coole shit te bouwen: Ik heb Pinecone niet gemaakt omdat ik dacht dat het makkelijk zou zijn, dus waarom zou ik een centrale rol delegeren als ik het zelf kon doen? Een aangepaste parser mag niet triviaal zijn, maar het is volledig te doen.
In het begin was ik niet helemaal zeker of ik een levensvatbaar pad zou bewandelen, maar ik kreeg vertrouwen van wat Walter Bright (een ontwikkelaar van een vroege versie van C++, en de maker van de D-taal) te zeggen had over het onderwerp:
“iets meer controversieel, zou ik geen moeite doen om tijd te verspillen met lexer of parser generators en andere zogenaamde” compiler compilers.”Ze zijn tijdverspilling. Het schrijven van een lexer en parser is een klein percentage van de taak van het schrijven van een compiler. Het gebruik van een generator zal ongeveer net zoveel tijd in beslag nemen als het schrijven van een met de hand, en het zal je trouwen met de generator (wat van belang is bij het porten van de compiler naar een nieuw platform). En generatoren hebben ook de ongelukkige reputatie slechte foutmeldingen uit te zenden.”
Actieboom
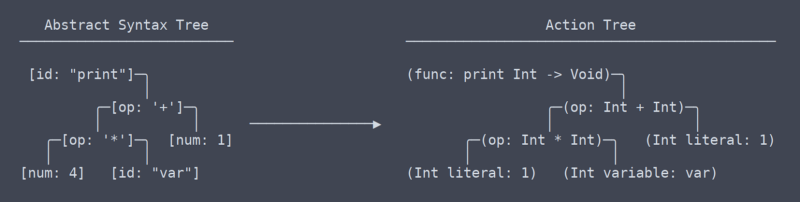
we hebben nu het gebied van algemene, universele termen verlaten, of tenminste ik weet niet meer wat de termen zijn. Wat ik de ‘action tree’ noem lijkt het meest op LLVM ‘ s IR (intermediate representation).
Er is een subtiel maar zeer significant verschil tussen de actie boom en de abstracte syntax boom. Het kostte me een tijdje om erachter te komen dat er zelfs een verschil tussen hen moet zijn (die bijgedragen aan de noodzaak van herschrijven van de parser).
Actieboom vs AST
simpel gezegd is de actieboom de AST met context. Die context is info zoals welk type een functie retourneert, of dat twee plaatsen waar een variabele wordt gebruikt in feite dezelfde variabele gebruiken. Omdat het al deze context moet achterhalen en onthouden, heeft de code die de actieboom genereert veel namespace lookup tabellen en andere thingamabobs nodig.
het uitvoeren van de Actieboom
zodra we de actieboom hebben, is het uitvoeren van de code eenvoudig. Elk actieknooppunt heeft een functie ‘uitvoeren’ die wat input neemt, doet wat de actie zou moeten doen (inclusief eventueel het aanroepen van subactie) en de uitvoer van de actie retourneert. Dit is de tolk in actie.
compileren van opties
” maar wacht!”Ik hoor je zeggen,” hoort Dennenappel daar niet bij?”Ja, dat is het. Maar compileren is moeilijker dan interpreteren. Er zijn een paar mogelijke benaderingen.
Bouw mijn eigen Compiler
dit leek me in het begin een goed idee. Ik hou ervan om dingen zelf te maken, en ik heb zin in een excuus om goed te worden in assemblage.
helaas is het schrijven van een draagbare compiler niet zo eenvoudig als het schrijven van een machinecode voor elk taalelement. Vanwege het aantal architecturen en besturingssystemen, is het onpraktisch voor een individu om een cross-platform compiler backend te schrijven.
zelfs de teams achter Swift, Rust en Clang willen zich er niet alleen mee bezighouden, dus in plaats daarvan gebruiken ze allemaal…
LLVM
LLVM is een verzameling compiler tools. Het is eigenlijk een bibliotheek die je taal zal veranderen in een gecompileerde uitvoerbare binary. Het leek de perfecte keuze, dus ik sprong er direct in. Helaas heb ik niet gekeken hoe diep het water was en ben ik meteen verdronken.
LLVM, hoewel niet assembler taal moeilijk, is gigantische complexe bibliotheek moeilijk. Het is niet onmogelijk om te gebruiken, en ze hebben goede tutorials, maar ik realiseerde me dat ik zou moeten wat oefening voordat ik klaar was om een Pinecone compiler volledig te implementeren met het.
Transpiling
Ik wilde een soort van gecompileerde Dennenappel en ik wilde het snel, dus ik wendde me tot een methode waarvan ik wist dat ik kon werken: transpiling.
Ik schreef een Pinecone naar C++ transpiler, en voegde de mogelijkheid toe om de uitvoerbron automatisch te compileren met GCC. Dit werkt momenteel voor bijna alle Pinecone programma ‘ s (hoewel er een paar rand gevallen die het breken). Het is geen bijzonder draagbare of schaalbare oplossing, maar het werkt voor het moment.
Future
ervan uitgaande dat ik Pinecone blijf ontwikkelen, zal LLVM vroeg of laat compilerende ondersteuning krijgen. Ik vermoed geen mater hoeveel ik werk op het, de transpiler zal nooit volledig stabiel en de voordelen van LLVM zijn talrijk. Het is gewoon een kwestie van wanneer ik tijd heb om een aantal voorbeeldprojecten in LLVM te maken en het onder de knie te krijgen.
tot die tijd is de interpreter geweldig voor triviale programma ‘ s en c++ transpiling werkt voor de meeste dingen die meer prestaties nodig hebben.
conclusie
Ik hoop dat ik programmeertalen iets minder mysterieus voor je heb gemaakt. Als je er zelf een wilt maken, beveel ik het ten zeerste aan. Er zijn een ton van de implementatie details om erachter te komen, maar de schets hier moet genoeg zijn om je op weg te krijgen.
Hier is mijn advies op hoog niveau om aan de slag te gaan (onthoud, ik weet niet echt wat ik doe, dus neem het met een korreltje zout):
- Als u twijfelt, ga dan geïnterpreteerd. Geïnterpreteerde talen zijn over het algemeen gemakkelijker te ontwerpen, te bouwen en te leren. Ik ontmoedig je niet om een gecompileerde te schrijven als je weet dat je dat wilt doen, maar als je op het punt staat, zou ik gaan geïnterpreteerd.
- als het gaat om lexers en parsers, doe dan wat je wilt. Er zijn geldige argumenten voor en tegen het schrijven van uw eigen. Uiteindelijk, als je denkt uit uw ontwerp en implementeren alles op een verstandige manier, het maakt niet echt uit.
- leer van de pijplijn waar ik mee eindigde. Veel trial and error ging in het ontwerpen van de pijplijn die ik nu heb. Ik heb geprobeerd As ’s te elimineren, As’ s die veranderen in acties bomen op zijn plaats, en andere verschrikkelijke ideeën. Deze pijplijn werkt, dus verander het niet tenzij je een echt goed idee hebt.
- als u niet de tijd of motivatie hebt om een complexe algemene taal te implementeren, probeer dan een esoterische taal zoals Brainfuck te implementeren. Deze tolken kunnen zo kort zijn als een paar honderd regels.
Ik heb zeer weinig spijt als het gaat om Dennenappel ontwikkeling. Ik heb een aantal slechte keuzes gemaakt langs de weg, maar ik heb het grootste deel van de code beïnvloed door dergelijke fouten herschreven.
Op dit moment is Pinecone in een goede staat dat het goed functioneert en gemakkelijk kan worden verbeterd. Het schrijven van Pinecone is een enorm leerzame en plezierige ervaring voor mij geweest, en het is nog maar net begonnen.