Version info: Code voor deze pagina is getest in Stata 12.
Poisson-regressie wordt gebruikt om variabelen te modelleren.
opmerking: het doel van deze pagina is om te laten zien hoe verschillende data analyse commando ‘ s te gebruiken. Het bestrijkt Niet alle aspecten van het onderzoeksproces die onderzoekers geacht worden te doen. Het heeft met name geen betrekking op het opschonen en controleren van gegevens, verificatie van veronderstellingen, modeldiagnostiek of mogelijke vervolganalyses.
voorbeelden van Poisson regressie
Voorbeeld 1. Het aantal doden door muilezel of paard kicks in het Pruisische leger per jaar.Ladislaus Bortkiewicz verzamelde gegevens uit 20 volumes van preussischen Statistik. Deze gegevens werden verzameld over 10 korpsen van het Pruisische leger in de late jaren 1800 in de loop van 20 jaar.
Voorbeeld 2. Het aantal mensen in de rij voor je bij de supermarkt. Voorspellers kunnen het aantal items bevatten dat momenteel wordt aangeboden tegen een speciale gereduceerde prijs en of een speciaal evenement (bijvoorbeeld een vakantie, een groot sportevenement) drie of minder dagen verwijderd is.
Voorbeeld 3. Het aantal prijzen verdiend door studenten op een middelbare school. Voorspellers van het aantal verdiende prijzen zijn het type programma waarin de student werd ingeschreven (bijvoorbeeld, beroeps -, algemeen of academisch) en de score op hun eindexamen in wiskunde.
beschrijving van de gegevens
ter illustratie hebben we een gegevensverzameling gesimuleerd, bijvoorbeeld 3 hierboven. In dit voorbeeld, num_awards is de uitkomst variabele en geeft het aantal awards verdiend door studenten op een middelbare school in een jaar, wiskunde is een continue voorspeller variabele en vertegenwoordigt studenten scores op hun wiskunde eindexamen, en prog is een categorische voorspeller variabele met drie niveaus die het type programma waarin de studenten werden ingeschreven.
laten we beginnen met het laden van de gegevens en kijken naar enkele beschrijvende statistieken.
use https://stats.idre.ucla.edu/stat/stata/dae/poisson_sim, clearsum num_awards math Variable | Obs Mean Std. Dev. Min Max-------------+-------------------------------------------------------- num_awards | 200 .63 1.052921 0 6 math | 200 52.645 9.368448 33 75
elke variabele heeft 200 geldige waarnemingen en hun distributies lijken redelijk. In dit bijzonder zijn de onvoorwaardelijke gemiddelde en variantie van onze uitkomstvariabele niet extreem verschillend.
laten we doorgaan met onze beschrijving van de variabelen in deze dataset. De tabel hieronder toont het gemiddelde aantal awards per programmatype en lijkt te suggereren dat het programmatype een goede kandidaat is voor het voorspellen van het aantal awards, onze resultaatvariabele, omdat de gemiddelde waarde van het resultaat per prog lijkt te variëren.
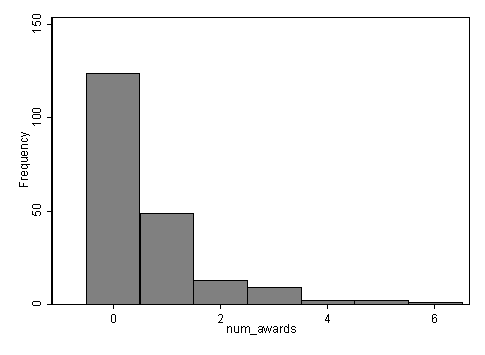
tabstat num_awards, by(prog) stats(mean sd n)Summary for variables: num_awards by categories of: prog (type of program) prog | mean sd N---------+------------------------------ general | .2 .4045199 45academic | 1 1.278521 105vocation | .24 .5174506 50---------+------------------------------ Total | .63 1.052921 200----------------------------------------histogram num_awards, discrete freq scheme(s1mono)(start=0, width=1)
analysemethoden die u zou kunnen overwegen
hieronder vindt u een lijst met een aantal analysemethoden die u wellicht bent tegengekomen. Sommige van de genoemde methoden zijn redelijk, terwijl anderen uit de gunst zijn gevallen of beperkingen hebben.
- Poisson regressie-Poisson regressie wordt vaak gebruikt voor het modelleren van telgegevens. Poisson regressie heeft een aantal uitbreidingen handig voor count modellen.
- negatieve binomiale regressie-negatieve binomiale regressie kan worden gebruikt voor oververspreide telgegevens, dat wil zeggen wanneer de voorwaardelijke variantie het voorwaardelijke gemiddelde overschrijdt. Het kan worden beschouwd als een generalisatie van Poisson regressie omdat het dezelfde gemiddelde structuur heeft als Poisson regressie en het een extra parameter heeft om de overdispersie te modelleren. Als de voorwaardelijke verdeling van de resultaatvariabele oververspreid is, zijn de betrouwbaarheidsintervallen voor negatieve binomialregressie waarschijnlijk smaller in vergelijking met die van een Poisson-regressie.
- Zero-inflated regression model-Zero-inflated modellen proberen overtollige nullen te verantwoorden. Met andere woorden, twee soorten nullen worden verondersteld te bestaan in de gegevens, “echte nullen” en “overtollige nullen”. Nul-opgeblazen modellen schatten twee vergelijkingen tegelijk, een voor het telmodel en een voor de overtollige nullen.
- OLS – regressie-teluitkomstvariabelen worden soms log-getransformeerd en geanalyseerd met OLS-regressie. Veel problemen doen zich voor met deze aanpak, waaronder verlies van gegevens als gevolg van ongedefinieerde waarden gegenereerd door het nemen van de log van nul (die is ongedefinieerd) en bevooroordeelde schattingen.
Poisson regressie
hieronder gebruiken we het Poisson commando om een Poisson regressiemodel te schatten. De i. voor prog geeft aan dat het een factor variabele (d.w.z., categorische variabele), en dat het in het model moet worden opgenomen als een reeks indicatorvariabelen.
we gebruiken de optie VCE (robuust) om robuuste standaardfouten te verkrijgen voor de parameterschattingen zoals aanbevolen door Cameron en Trivedi (2009) om lichte schending van onderliggende aannames te controleren.
poisson num_awards i.prog math, vce(robust)Iteration 0: log pseudolikelihood = -182.75759 Iteration 1: log pseudolikelihood = -182.75225 Iteration 2: log pseudolikelihood = -182.75225 Poisson regression Number of obs = 200 Wald chi2(3) = 80.15 Prob > chi2 = 0.0000Log pseudolikelihood = -182.75225 Pseudo R2 = 0.2118------------------------------------------------------------------------------ | Robust num_awards | Coef. Std. Err. z P>|z| -------------+---------------------------------------------------------------- prog | 2 | 1.083859 .3218538 3.37 0.001 .4530373 1.714681 3 | .3698092 .4014221 0.92 0.357 -.4169637 1.156582 | math | .0701524 .0104614 6.71 0.000 .0496485 .0906563 _cons | -5.247124 .6476195 -8.10 0.000 -6.516435 -3.977814------------------------------------------------------------------------------
de twee graad-vrijheid chi-kwadraat test geeft aan dat prog, samen genomen, is een statistisch significante voorspeller van num_awards.
test 2.prog 3.prog ( 1) 2.prog = 0 ( 2) 3.prog = 0 chi2( 2) = 14.76 Prob > chi2 = 0.0006
om de geschiktheid van het model te helpen beoordelen, kan het estat gof Commando worden gebruikt om de goodness-of-fit chi-squared test te verkrijgen. Dit is geen test van de modelcoëfficiënten (die we zagen in de header informatie), maar een test van het modelformulier: past het poisson modelformulier bij onze gegevens?
estat gof Goodness-of-fit chi2 = 189.4496 Prob > chi2(196) = 0.6182 Pearson goodness-of-fit = 212.1437 Prob > chi2(196) = 0.2040
we concluderen dat het model redelijk goed past omdat de goodness-of-fit chi-squared test statistisch niet significant is. Als de test statistisch significant was geweest, zou dit erop wijzen dat de gegevens niet goed in het model passen. In die situatie kunnen we proberen te bepalen of er weggelaten voorspellende variabelen zijn, of onze lineariteit aanname geldt en/of als er een probleem is van oververspreiding.
soms willen we de regressieresultaten presenteren als incidentele rate ratio ‘ s, we kunnen hunr optie gebruiken. Deze IRR waarden zijn gelijk aan onze coëfficiënten van de output boven exponentiated.
poisson, irrPoisson regression Number of obs = 200 Wald chi2(3) = 80.15 Prob > chi2 = 0.0000Log pseudolikelihood = -182.75225 Pseudo R2 = 0.2118------------------------------------------------------------------------------ | Robust num_awards | IRR Std. Err. z P>|z| -------------+---------------------------------------------------------------- prog | 2 | 2.956065 .9514208 3.37 0.001 1.573083 5.554903 3 | 1.447458 .5810418 0.92 0.357 .6590449 3.179049 | math | 1.072672 .0112216 6.71 0.000 1.050902 1.094893------------------------------------------------------------------------------
de uitgang hierboven geeft aan dat het incidentpercentage voor 2.prog is 2,96 keer het incidentpercentage voor de referentiegroep (1.prog). Ook het incidentpercentage voor 3.prog is 1,45 keer het incidentpercentage voor de referentiegroep die de andere variabelen constant houdt. De procentuele verandering in het incidentpercentage van num_awards is een stijging van 7% voor elke eenheidsstijging in wiskunde.
roep de vorm van onze modelvergelijking op:
log(num_awards) = Intercept + b1(prog=2) + b2(prog=3) + b3math.
Dit houdt in:
num_awards = exp(Intercept + b1(prog=2) + b2(prog=3)+ b3math) = exp(Intercept) * exp(b1(prog=2)) * exp(b2(prog=3)) * exp(b3math)
De coëfficiënten hebben een additief effect op de log(y) schaal en de IRR hebben een multiplicatieve effect in de y-schaal.
voor aanvullende informatie over de verschillende metrics waarin de resultaten kunnen worden gepresenteerd, en de interpretatie van dergelijke, zie regressiemodellen voor Categorical Dependent Variables Using Stata, Second Edition by J. Scott Long and Jeremy Freese (2006).
om het model beter te begrijpen, kunnen we het marges commando gebruiken. Hieronder gebruiken we het margins commando om de voorspelde tellingen op elk niveau vanprog te berekenen, waarbij alle andere variabelen (in dit voorbeeld, wiskunde) in het model op hun gemiddelde waarden staan.
margins prog, atmeansAdjusted predictions Number of obs = 200Model VCE : RobustExpression : Predicted number of events, predict()at : 1.prog = .225 (mean) 2.prog = .525 (mean) 3.prog = .25 (mean) math = 52.645 (mean)------------------------------------------------------------------------------ | Delta-method | Margin Std. Err. z P>|z| -------------+---------------------------------------------------------------- prog | 1 | .211411 .0627844 3.37 0.001 .0883558 .3344661 2 | .6249446 .0887008 7.05 0.000 .4510943 .7987949 3 | .3060086 .0828648 3.69 0.000 .1435966 .4684205------------------------------------------------------------------------------
in de uitvoer hierboven zien we dat het voorspelde aantal gebeurtenissen voor niveau 1 van prog ongeveer is .21, met wiskunde op het gemiddelde. Het voorspelde aantal gebeurtenissen voor niveau 2 van prog is hoger op .62, en het voorspelde aantal gebeurtenissen voor niveau 3 van prog is ongeveer .31. Merk op dat de voorspelde telling van niveau 2 van prog is (.6249446/.211411) = 2,96 keer hoger dan de voorspelde telling voor niveau 1 van prog. Dit komt overeen met wat we zagen in de IRR-uitvoertabel.
hieronder krijgen we de voorspelde tellingen voor wiskundige waarden die variëren van 35 tot 75 in stappen van 10.
margins, at(math=(35(10)75)) vsquishPredictive margins Number of obs = 200Model VCE : RobustExpression : Predicted number of events, predict()1._at : math = 352._at : math = 453._at : math = 554._at : math = 655._at : math = 75------------------------------------------------------------------------------ | Delta-method | Margin Std. Err. z P>|z| -------------+---------------------------------------------------------------- _at | 1 | .1311326 .0358696 3.66 0.000 .0608295 .2014358 2 | .2644714 .047518 5.57 0.000 .1713379 .3576049 3 | .5333923 .0575203 9.27 0.000 .4206546 .64613 4 | 1.075758 .1220143 8.82 0.000 .8366147 1.314902 5 | 2.169615 .4115856 5.27 0.000 1.362922 2.976308------------------------------------------------------------------------------
de tabel hierboven laat zien dat met prog op zijn waargenomen waarden en wiskunde gehouden op 35 voor alle waarnemingen, de gemiddelde voorspelde telling (of het gemiddelde aantal awards) is ongeveer .13; wanneer math = 75, De gemiddelde voorspelde telling is ongeveer 2,17. Als we de voorspelde tellingen vergelijken bij math = 35 en math = 45, kunnen we zien dat de verhouding (.2644714/.1311326) = 2.017. Dit komt overeen met de IRR van 1,0727 voor een 10 eenheid verandering: 1,0727^10 = 2,017.
het door de gebruiker geschreven fitstat Commando (evenals Stata ’s estat commando’ s) kan worden gebruikt om aanvullende informatie te verkrijgen die nuttig kan zijn als u modellen wilt vergelijken. U kunt zoeken fitstat typen om dit programma te downloaden (zie hoe kan Ik gebruik maken van de search commando om te zoeken naar programma ‘ s en krijg extra hulp? voor meer informatie over het gebruik van zoeken).
fitstatMeasures of Fit for poisson of num_awardsLog-Lik Intercept Only: -231.864 Log-Lik Full Model: -182.752D(195): 365.505 LR(3): 98.223 Prob > LR: 0.000McFadden's R2: 0.212 McFadden's Adj R2: 0.190ML (Cox-Snell) R2: 0.388 Cragg-Uhler(Nagelkerke) R2: 0.430AIC: 1.878 AIC*n: 375.505BIC: -667.667 BIC': -82.328BIC used by Stata: 386.698 AIC used by Stata: 373.505
u kunt een grafiek maken van het voorspelde aantal gebeurtenissen met onderstaande commando ‘ s. De grafiek geeft aan dat de meeste prijzen worden voorspeld voor degenen in de academische opleiding (prog = 2), vooral als de student een hoge wiskunde score heeft. Het laagste aantal voorspelde prijzen is voor die studenten in het algemeen programma (prog = 1).
predict cseparate c, by(prog)twoway scatter c1 c2 c3 math, connect(l l l) sort /// ytitle("Predicted Count") ylabel( ,nogrid) legend(rows(3)) /// legend(ring(0) position(10)) scheme(s1mono)Image poisso2
te overwegen zaken
- Als overdispersie een probleem lijkt te zijn, moeten we eerst controleren of ons model correct is gespecificeerd, zoals weggelaten variabelen.en functionele vormen. Bijvoorbeeld, als we de voorspellende variabele progin het voorbeeld hierboven weglaten, zou Ons model een probleem met oververspreiding lijken te hebben. Met andere woorden, een mis-gespecificeerd model kan een symptoom als een oververspreiding probleem presenteren.
- aannemende dat het model correct is opgegeven, wilt u misschien controleren of er sprake is van oververspreiding. Er zijn verschillende manieren om dit te doen, waaronder de waarschijnlijkheid ratio test van overdispersie parameter Alfa door het uitvoeren van hetzelfde regressiemodel met behulp van negatieve binomiale distributie (nbreg).
- een veel voorkomende oorzaak van overdispersie is overtollige nullen, die op hun beurt worden gegenereerd door een extra proces voor het genereren van gegevens. In deze situatie, nul-opgeblazen model moet worden overwogen.
- als het proces voor het genereren van gegevens Geen 0 ‘ s toelaat (zoals het aantal dagen in het ziekenhuis), dan kan een zero-truncated model geschikter zijn.
- telgegevens hebben vaak een blootstellingsvariabele, die aangeeft hoe vaak de gebeurtenis had kunnen plaatsvinden. Deze variabele moet worden opgenomen in een Poisson-model met behulp van de optie exp ().
- de resultaatvariabele in een Poisson-regressie kan geen negatieve getallen hebben en de blootstelling kan geen 0s hebben.
- in Stata kan een Poisson-model worden geschat via glm-commando met de log-link en de poisson-familie.
- u moet het glm commando gebruiken om de reststoffen te verkrijgen om andere veronderstellingen van het Poisson model te controleren (zie Cameron and Trivedi (1998) en Dupont (2002) voor meer informatie).
- Er bestaan veel verschillende maten van pseudo-R-kwadraat. Ze proberen allemaal informatie te verschaffen die vergelijkbaar is met die van R-kwadraat in OLS-regressie, hoewel geen van hen precies kan worden geïnterpreteerd zoals R-kwadraat in OLS-regressie wordt geïnterpreteerd. Voor een bespreking van verschillende pseudo-R-vierkanten, zie Long and Freese (2006) of onze FAQ pagina wat zijn pseudo-R-squareds?.
- Poisson-regressie wordt geschat via een schatting van de maximale waarschijnlijkheid. Het vereist meestal een grote steekproefgrootte.
zie ook
- geannoteerde uitvoer voor het Poisson-Commando
- Stata FAQ: Hoe kan ik countfit gebruiken bij het kiezen van een telmodel?
- Stata online manual
- poisson
- stata FAQs
- Hoe worden de standaardfouten en betrouwbaarheidsintervallen berekend voor incidentie-rate ratio ’s (IRR’ s) door poisson en nbreg?
- Cameron, A. C. and Trivedi, P. K. (2009). Micro-Economie Met Behulp Van Stata. College Station, TX: Stata Press.
- Cameron, A. C. and Trivedi, P. K. (1998). Regressieanalyse van telgegevens. New York: Cambridge Press.
- Cameron, A. C. Advances in Count Data Regression Talk for the Applied Statistics Workshop, 28 maart 2009.http://cameron.econ.ucdavis.edu/racd/count.html .
- Dupont, W. D. (2002). Statistische modellering voor biomedische onderzoekers: een eenvoudige introductie tot de analyse van complexe Data. New York: Cambridge Press.
- Long, J. S. (1997). Regressiemodellen voor categorische en beperkte afhankelijke variabelen.Thousand Oaks, CA: Sage Publications.
- Long, J. S. and Freese, J. (2006). Regressiemodellen voor categorische afhankelijke variabelen met behulp van Stata, tweede editie. College Station, TX: Stata Press.