Wat is Reinforcement Learning?
Reinforcement Learning wordt gedefinieerd als een Machine Learning methode die zich bezighoudt met hoe software agents acties moeten ondernemen in een omgeving. Reinforcement Learning is een onderdeel van de deep learning methode die u helpt om een deel van de cumulatieve beloning te maximaliseren.
deze neurale netwerk leermethode helpt u om te leren hoe u een complex doel kunt bereiken of een specifieke dimensie over vele stappen kunt maximaliseren.
In Reinforcement Learning tutorial leert u:
- Wat is Reinforcement Learning?
- belangrijke termen gebruikt in Deep Reinforcement Learning method
- Hoe Reinforcement Learning werkt?
- Reinforcement Learning Algorithms
- kenmerken van Reinforcement Learning
- soorten Reinforcement Learning
- leermodellen van Reinforcement Learning
- toepassing van Reinforcement Learning
- waarom Reinforcement Learning gebruiken?
- wanneer gebruik je geen Reinforcement Learning?
- Challenges of Reinforcement Learning
belangrijke termen gebruikt in Deep Reinforcement Learning method
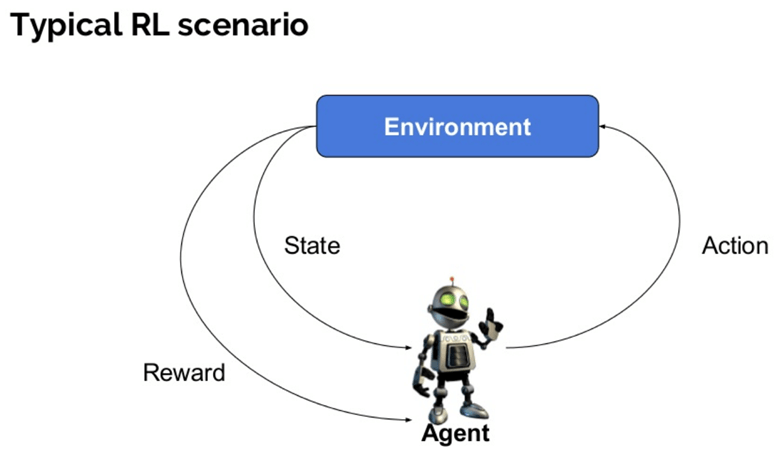
Hier zijn enkele belangrijke termen gebruikt in Reinforcement AI:
- Agent: Het is een veronderstelde entiteit die acties uitvoert in een omgeving om enige beloning te krijgen.
- omgeving (e): een scenario waar een agent mee te maken heeft.
- beloning (R): Een onmiddellijke terugkeer gegeven aan een agent wanneer hij of zij specifieke actie of taak uitvoert.
- toestand (en): toestand verwijst naar de huidige situatie die door het milieu wordt teruggegeven.
- beleid (?) : Het is een strategie die van toepassing is door de agent om de volgende actie te beslissen op basis van de huidige toestand.
- waarde (V): Het wordt verwacht lange termijn rendement met korting, in vergelijking met de korte termijn beloning.
- waarde functie: het specificeert de waarde van een toestand die het totale bedrag van de beloning is. Het is een agent die verwacht moet worden vanaf die staat.
- model van de omgeving: dit bootst het gedrag van de omgeving na. Het helpt je om gevolgtrekkingen te maken en ook te bepalen hoe de omgeving zich zal gedragen.
- modelgebaseerde methoden: het is een methode voor het oplossen van versterkingsleerproblemen waarbij gebruik wordt gemaakt van modelgebaseerde methoden.
- Q-waarde of actiewaarde (Q): Q-waarde is vrijwel gelijk aan waarde. Het enige verschil tussen de twee is dat het neemt een extra parameter als een huidige actie.
hoe Reinforcement Learning werkt?
laten we een eenvoudig voorbeeld bekijken dat u helpt om het versterkingsleermechanisme te illustreren.
overweeg het scenario van het leren van nieuwe trucs aan uw kat
- aangezien kat geen Engels of enige andere menselijke taal begrijpt, kunnen we haar niet direct vertellen wat ze moet doen. In plaats daarvan volgen we een andere strategie.
- We emuleren een situatie, en de kat probeert op veel verschillende manieren te reageren. Als het antwoord van de kat de gewenste manier is, geven we haar vis.
- wanneer de kat aan dezelfde situatie wordt blootgesteld, voert de kat een soortgelijke actie uit met nog meer enthousiasme in de verwachting meer beloning(voedsel) te krijgen.
- Dat is als leren dat cat krijgt van” wat te doen ” van positieve ervaringen.
- tegelijkertijd leert de kat ook wat hij niet doet als hij met negatieve ervaringen wordt geconfronteerd.
uitleg over het voorbeeld:
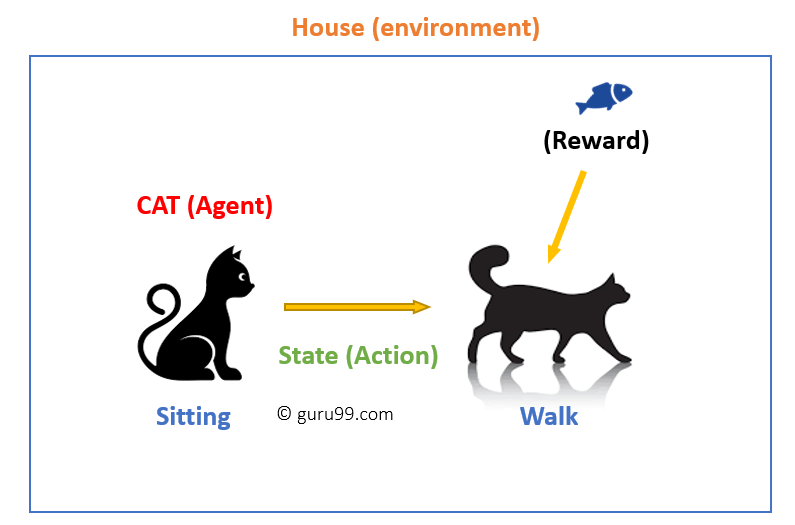
in dit geval is
- uw kat een middel dat wordt blootgesteld aan de omgeving. In dit geval is het jouw huis. Een voorbeeld van een toestand zou uw kat zitten, en u gebruik maken van een specifiek woord in voor kat te lopen.
- onze agent reageert door een actietransitie uit te voeren van de ene “status” naar de andere “status.”
- bijvoorbeeld, uw kat gaat van zitten naar lopen.
- de reactie van een agent is een actie, en het beleid is een methode om een actie te selecteren gegeven een toestand in de verwachting van betere resultaten.
- na de overgang kunnen zij een beloning of boete krijgen.
Reinforcement Learning Algorithms
Er zijn drie benaderingen om een Reinforcement Learning algoritme te implementeren.
Value-Based:
In een value-based Reinforcement Learning method, moet u proberen een value functie V(s) te maximaliseren. In deze methode, de agent verwacht een lange termijn terugkeer van de huidige Staten Onder het beleid ?.
Beleidsgebaseerd:
in een BELEIDSGEBASEERDE RL-methode probeert u een dergelijk beleid te bedenken dat de actie die in elke staat wordt uitgevoerd U helpt om in de toekomst een maximale beloning te krijgen.
twee soorten beleidsgebaseerde methoden zijn:
- deterministisch: voor elke staat wordt dezelfde actie door het beleid geproduceerd ?.
- stochastisch: elke actie heeft een bepaalde waarschijnlijkheid, die wordt bepaald door de volgende vergelijking.Stochastisch beleid:
n{a\s) = P\A, = a\S, =S]
Modelgebaseerd:
in deze Versterkingsleermethode moet u een virtueel model maken voor elke omgeving. De agent leert om te presteren in die specifieke omgeving.
Kenmerken van wapening leren
Hier zijn belangrijke kenmerken van wapening leren
- Er is geen supervisor, alleen een reëel getal of beloningssignaal
- sequentiële besluitvorming
- tijd speelt een cruciale rol in wapening problemen
- Feedback is altijd vertraagd, niet onmiddellijk
- acties van de Agent bepalen de volgende gegevens die het ontvangt
soorten wapening leren h2>
twee soorten versterkingsleermethoden zijn:
positief:
het wordt gedefinieerd als een gebeurtenis, die optreedt vanwege specifiek gedrag. Het verhoogt de sterkte en de frequentie van het gedrag en heeft een positieve invloed op de actie van de agent.
dit type versterking helpt u om de prestaties te maximaliseren en veranderingen te ondersteunen voor een langere periode. Nochtans, kan te veel versterking tot over-optimalisatie van staat leiden, die de resultaten kan beà nvloeden.
negatief:
negatieve versterking wordt gedefinieerd als versterking van gedrag dat optreedt als gevolg van een negatieve aandoening die had moeten stoppen of voorkomen. Het helpt u om de minimale stand van de prestaties te definiëren. Het nadeel van deze methode is echter dat het voldoende biedt om het minimale gedrag te ontmoeten.
leermodellen van versterking
Er zijn twee belangrijke leermodellen bij het leren van versterking:
- Markov beslissingsproces
- Q leren
Markov beslissingsproces
de volgende parameters worden gebruikt om een oplossing te vinden:
- Set van acties-A
- set van toestanden-S
- beloning – R
- beleid – n
- waarde-V
de wiskundige benadering voor het in kaart brengen van een oplossing in reinforcement Learning is recon als een Markov-beslissingsproces of (MDP).
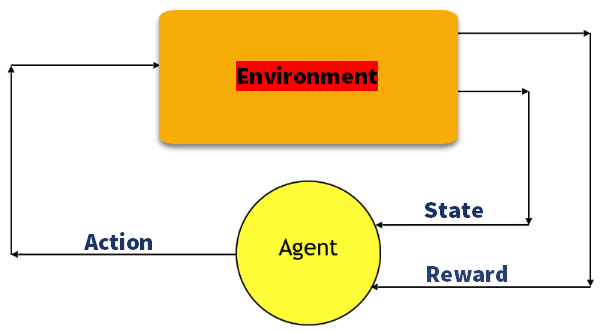
Q-Learning
Q learning is een op waarde gebaseerde methode om informatie te verstrekken om te bepalen welke actie een agent moet ondernemen.
laten we deze methode begrijpen door het volgende voorbeeld:
- Er zijn vijf kamers in een gebouw die met elkaar verbonden zijn door deuren.
- elke kamer is genummerd 0 tot 4
- de buitenkant van het gebouw kan één groot buitengebied zijn (5)
- deuren nummer 1 en 4 leiden naar het gebouw vanuit kamer 5
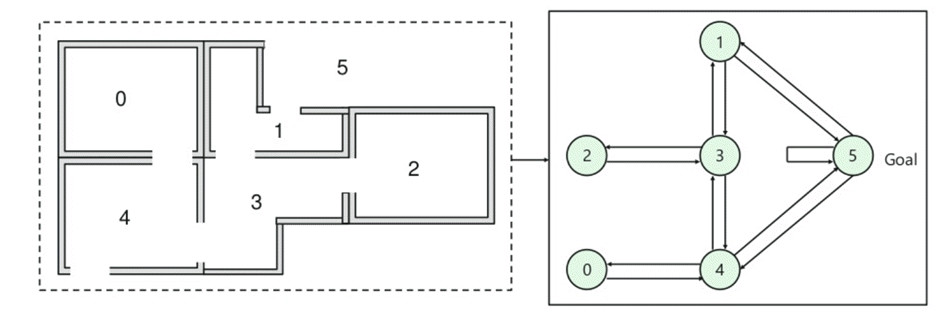
vervolgens moet u een beloningswaarde aan elke deur koppelen:
- Deuren die direct leiden tot het doel, een beloning van 100
- Deuren die niet rechtstreeks verbonden aan de kamer geeft nul beloning
- Als de deuren zijn in twee richtingen en twee pijlen zijn toegewezen voor elke kamer
- Elke pijl in de bovenstaande afbeelding ziet u een instant beloning waarde
Uitleg:
In deze afbeelding, kunt u die kamer staat voor een toestand
Agent beweging van de ene kamer naar de andere vertegenwoordigt een actie
In de hieronder gegeven beeld, een staat wordt beschreven als een knooppunt, terwijl de pijlen tonen de actie.

For example, an agent traverse from room number 2 to 5
- Initial state = state 2
- State 2-> state 3
- State 3 -> state (2,1,4)
- State 4-> state (0,5,3)
- State 1-> state (5,3)
- State 0-> state 4
Reinforcement Learning vs. Begeleid leren
| Parameters | versterking leren | begeleid leren | Beslissingsstijl | versterking leren helpt u om uw beslissingen achtereenvolgens te nemen. | bij deze methode wordt een beslissing genomen over de input die aan het begin wordt gegeven. |
| werkt aan | werkt aan interactie met de omgeving. | werkt aan voorbeelden of gegeven steekproefgegevens. |
| afhankelijkheid van beslissing | in RL methode is de leerbeslissing afhankelijk. Daarom moet u labels geven aan alle afhankelijke beslissingen. | begeleid leren van de beslissingen die onafhankelijk zijn van elkaar, zodat labels worden gegeven voor elke beslissing. |
| Best suited | ondersteunt en werkt beter in AI, waar menselijke interactie overheersend is. | het wordt meestal bediend met een interactief software systeem of toepassingen. |
| voorbeeld | schaakspel | Object recognition |
toepassingen van Reinforcement Learning
Hier zijn toepassingen van Reinforcement Learning:
- Robotics for industrial automation.
- Business strategy planning
- Machine learning and Data processing
- het helpt u om opleidingssystemen te creëren die aangepaste instructies en materialen bieden volgens de eisen van studenten.
- Aircraft control and robot motion control
waarom Reinforcement Learning gebruiken?
Hier zijn belangrijke redenen voor het gebruik van Reinforcement Learning:
- Het helpt u om te vinden welke situatie een actie nodig heeft
- helpt u om te ontdekken welke actie de hoogste beloning oplevert over de langere periode.
- Reinforcement Learning biedt de leeragent ook een beloningsfunctie.
- het maakt het ook mogelijk om de beste methode te vinden voor het verkrijgen van grote beloningen.
wanneer gebruik je geen Reinforcement Learning?
u kunt het versterkingsleermodel niet toepassen. Hier zijn een aantal voorwaarden wanneer je niet moet gebruiken versterking leermodel.
- wanneer u voldoende gegevens hebt om het probleem op te lossen met een begeleide leermethode
- moet u onthouden dat Reinforcement Learning veel rekenwerk en tijdrovend is. in het bijzonder wanneer de actieruimte groot is.
Challenges of Reinforcement Learning
Hier zijn de belangrijkste uitdagingen waarmee u te maken krijgt tijdens het verdienen van versterkingen:
- Feature/reward design die zeer betrokken zouden moeten zijn
- Parameters kunnen de snelheid van het leren beïnvloeden.
- realistische omgevingen kunnen gedeeltelijk waarneembaar zijn.
- te veel versterking kan leiden tot een overbelasting van toestanden die de resultaten kunnen verminderen.
- realistische omgevingen kunnen niet-statisch zijn.
samenvatting:
- Reinforcement Learning is een Machine Learning methode
- helpt u om te ontdekken welke actie de hoogste beloning oplevert over de langere periode.
- drie methoden voor “reinforcement learning” zijn 1) “Value-based” 2) “Policy-based” en “Model based learning”.
- Agent, State, Reward, Environment, Value function Model of the environment, Model based methods, are some important terms using in RL learning method
- het voorbeeld van reinforcement learning is your cat is an agent that is exposed to the environment.
- het grootste kenmerk van deze methode is dat er geen supervisor is, alleen een reëel getal of beloningssignaal
- twee soorten versterkingsleer zijn 1) positief 2) negatief
- twee veelgebruikte leermodellen zijn 1) Markov beslissingsproces 2) Q leren
- Versterkingsleermethode werkt op interactie met de omgeving, terwijl de leermethode onder toezicht werkt op gegeven voorbeeldgegevens of voorbeeld.
- toepassing of versterking leermethoden zijn: Robotics for industrial automation and business strategy planning
- u moet deze methode niet gebruiken als u genoeg gegevens hebt om het probleem op te lossen
- de grootste uitdaging van deze methode is dat parameters De snelheid van het leren kunnen beïnvloeden