laatst bijgewerkt op 17 februari 2021
een voorspelling vanuit een machine learning perspectief is een enkel punt dat de onzekerheid van die voorspelling verbergt.
Voorspellingsintervallen bieden een manier om de onzekerheid in een voorspelling te kwantificeren en te communiceren. Zij verschillen van betrouwbaarheidsintervallen die in plaats daarvan de onzekerheid in een populatieparameter zoals een gemiddelde of standaardafwijking proberen te kwantificeren. Voorspellingsintervallen beschrijven de onzekerheid voor één specifieke uitkomst.
in deze tutorial zult u het voorspellingsinterval ontdekken en hoe u dit kunt berekenen voor een eenvoudig lineair regressiemodel.
na het voltooien van deze tutorial, zult u weten:
- dat een voorspellingsinterval de onzekerheid van een enkele punt voorspelling kwantificeert.
- dat voorspellingsintervallen analytisch kunnen worden geschat voor eenvoudige modellen, maar uitdagender zijn voor niet-lineaire machine learning modellen.
- het voorspellingsinterval berekenen voor een eenvoudig lineair regressiemodel.
start uw project met mijn nieuwe boek statistieken voor Machine Learning, inclusief stap-voor-stap tutorials en de Python broncode bestanden voor alle voorbeelden.
laten we beginnen.
- bijgewerkt juni / 2019: gecorrigeerd significantieniveau als fractie van standaardafwijkingen.
- bijgewerkt Apr / 2020: vaste typo in plot van voorspellingsinterval.

Voorspellingsintervallen voor Machine Learning
Foto door Jim Bendon, enkele rechten voorbehouden.
Tutorial Overview
Deze tutorial is verdeeld in 5 delen; ze zijn:
- Wat is er mis met een puntschatting?
- Wat Is een voorspellingsinterval?
- Hoe bereken je een voorspellingsinterval
- voorspellingsinterval voor lineaire regressie
- gewerkt voorbeeld
hulp nodig met statistieken voor Machine Learning?
neem nu mijn gratis 7-daagse e-mail spoedcursus (met voorbeeldcode).
Klik om u aan te melden en ontvang ook een gratis PDF Ebook versie van de cursus.
Download Your FREE Mini-Course
Why Calculate a Prediction Interval?
In predictive modeling, a prediction or a forecast is a single outcome value given some input variables.
For example:
|
1
|
yhat = model.predict (X)
|
waarbij yhat de geschatte uitkomst of voorspelling is van het getrainde model voor de gegeven invoergegevens X.
Dit is een puntvoorspelling.
per definitie is het een schatting of een benadering en bevat het enige onzekerheid.
de onzekerheid komt voort uit de fouten in het model zelf en ruis in de invoergegevens. Het model is een benadering van de relatie tussen de input variabelen en de output variabelen.
gegeven het proces dat wordt gebruikt om het model te kiezen en af te stemmen, zal het de beste benadering zijn die gegeven de beschikbare informatie wordt gemaakt, maar het zal nog steeds fouten maken. Gegevens van het domein zullen natuurlijk de onderliggende en onbekende relatie tussen de input en output variabelen verduisteren. Dit maakt het een uitdaging om in het model te passen, en maakt het ook een uitdaging voor een fit model om voorspellingen te doen.
gezien deze twee belangrijkste foutenbronnen is hun puntvoorspelling uit een voorspellend model onvoldoende om de werkelijke onzekerheid van de voorspelling te beschrijven.
Wat Is een voorspellingsinterval?
een voorspellingsinterval is een kwantificering van de onzekerheid op een voorspelling.
Het biedt een probabilistische boven-en ondergrenzen voor de schatting van een outcome variabele.
een voorspellingsinterval voor een enkele toekomstige waarneming is een interval dat, met een bepaalde betrouwbaarheidsgraad, een toekomstige willekeurig geselecteerde waarneming uit een distributie zal bevatten.
— Page 27, Statistical intervallen: A Guide for Practitioners and Researchers, 2017.
Voorspellingsintervallen worden het meest gebruikt bij het maken van voorspellingen of voorspellingen met een regressiemodel, waarbij een hoeveelheid wordt voorspeld.
een voorbeeld van de presentatie van een voorspellingsinterval is als volgt:
gegeven een voorspelling van ‘y’ gegeven ‘x’, is er een 95% waarschijnlijkheid dat het bereik ‘a’ tot ‘b’ de ware uitkomst dekt.
het voorspellingsinterval omringt de voorspelling van het model en dekt hopelijk het bereik van de ware uitkomst.
het onderstaande diagram helpt om de relatie tussen de voorspelling, het voorspellingsinterval en de werkelijke uitkomst visueel te begrijpen.
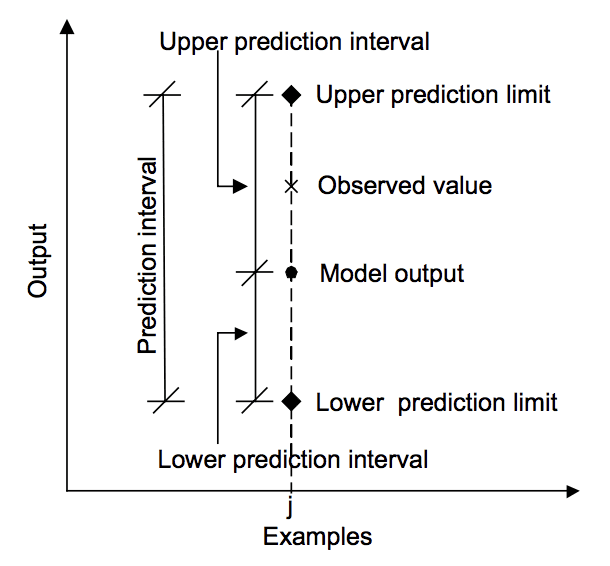
relatie tussen voorspelling, werkelijke waarde en voorspellingsinterval.
overgenomen uit” Machine learning approaches for estimation of prediction interval for the model output”, 2006.
een voorspellingsinterval verschilt van een betrouwbaarheidsinterval.
een betrouwbaarheidsinterval kwantificeert de onzekerheid op een geschatte populatievariabele, zoals het gemiddelde of de standaardafwijking. Terwijl een voorspellingsinterval de onzekerheid kwantificeert op een enkele waarneming die vanuit de populatie wordt geschat.
in voorspellende modellering kan een betrouwbaarheidsinterval worden gebruikt om de onzekerheid van de geschatte vaardigheid van een model te kwantificeren, terwijl een voorspellings-interval kan worden gebruikt om de onzekerheid van een enkele voorspelling te kwantificeren.
een voorspellingsinterval is vaak groter dan het betrouwbaarheidsinterval omdat rekening moet worden gehouden met het betrouwbaarheidsinterval en de variantie in de voorspelde outputvariabele.
Voorspellingsintervallen zullen altijd breder zijn dan betrouwbaarheidsintervallen , omdat ze de onzekerheid verklaren die gepaard gaat met e, de onherleidbare fout.
– Page 103, An Introduction to Statistical Learning: with Applications in R, 2013.
hoe een voorspellingsinterval te berekenen
een voorspellingsinterval wordt berekend als een combinatie van de geschatte variantie van het model en de variantie van de uitkomstvariabele.
Voorspellingsintervallen zijn gemakkelijk te beschrijven, maar in de praktijk moeilijk te berekenen.
in eenvoudige gevallen, zoals lineaire regressie, kunnen we het voorspellingsinterval direct schatten.
in het geval van niet-lineaire regressiealgoritmen, zoals kunstmatige neurale netwerken, is het een veel grotere uitdaging en vereist de keuze en implementatie van gespecialiseerde technieken. Algemene technieken zoals de bootstrap resampling methode kunnen worden gebruikt, maar zijn berekenbaar duur.
het artikel “A Comprehensive Review of Neural Network-based Prediction intervallen and New Advances” biedt een redelijk recente studie van voorspellingsintervallen voor niet-lineaire modellen in de context van neurale netwerken. De volgende lijst geeft een samenvatting van enkele methoden die kunnen worden gebruikt voor voorspellingsonzekerheid voor niet-lineaire machine learning modellen:
- De Delta methode, uit het veld van niet-lineaire regressie.
- de Bayesiaanse methode, uit Bayesiaanse modellering en statistieken.
- de methode voor de schatting van de gemiddelde variantie, waarbij gebruik wordt gemaakt van geschatte statistieken.
- de Bootstrap methode, met behulp van data resampling en het ontwikkelen van een ensemble van modellen.
We kunnen de berekening van een voorspellingsinterval concreet maken met een bewerkt voorbeeld in de volgende sectie.
voorspellingsinterval voor lineaire regressie
een lineaire regressie is een model dat de lineaire combinatie van inputs beschrijft om de outputvariabelen te berekenen.
For example, an estimated linear regression model may be written as:
|
1
|
yhat = b0 + b1 . x
|
Where yhat is the prediction, b0 and b1 are coefficients of the model estimated from training data and x is the input variable.
We kennen de werkelijke waarden van de coëfficiënten b0 en b1 niet. We kennen ook niet de werkelijke populatie parameters zoals gemiddelde en standaardafwijking voor x of y. al deze elementen moeten worden geschat, wat onzekerheid in het gebruik van het model introduceert om voorspellingen te doen.
We kunnen enkele aannames maken, zoals de distributies van x en y en de voorspellingsfouten gemaakt door het model, de zogenaamde reststoffen, zijn Gaussiaans.
het voorspellingsinterval rond yhat kan als volgt worden berekend:
|
1
|
yhat +/- z * sigma
|
Where yhat is the predicted value, z is the number of standard deviations from the Gaussian distribution (e.g. 1.96 for a 95% interval) and sigma is the standard deviation of the predicted distribution.
we weten in de praktijk niet. We kunnen een onbevooroordeelde schatting van de van de voorspelde standaardafwijking als volgt berekenen (uit Machine learning-benaderingen voor de schatting van het voorspellingsinterval voor de modeloutput):
|
1
|
stdev = sqrt(1 / (N – 2) * e(i)^2 for i to N)
|
Where stdev is an unbiased estimate of the standard deviation for the predicted distribution, n are the total predictions made, and e(i) is the difference between the ith prediction and actual value.
gewerkt voorbeeld
laten we het geval van lineaire regressie voorspellingsintervallen concreet maken met een gewerkt voorbeeld.
laten we eerst een eenvoudige dataset met twee variabelen definiëren waarbij de uitvoervariabele (y) afhankelijk is van de invoervariabele (x) met wat Gaussiaanse ruis.
het voorbeeld hieronder definieert de dataset die we voor dit voorbeeld zullen gebruiken.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
# genereer gerelateerde variabelen
van numpy importeren gemiddelde
van numpy importeren std
from numpy.random import randn
from numpy.random import seed
from matplotlib import pyplot
# seed random number generator
seed(1)
# prepare data
x = 20 * randn(1000) + 100
y = x + (10 * randn(1000) + 50)
# summarize
print(‘x: mean=%.3f stdv=%.3f’ % (mean(x), std(x)))
print(‘y: mean=%.3f stdv=%.3f’ % (mean(y), std(y)))
# plot
pyplot.scatter(x, y)
pyplot.show()
|
Running the example first prints the mean and standard deviations of the two variables.
|
1
2
|
x: mean=100.776 stdv=19.620
y: mean=151.050 stdv=22.358
|
een plot van de dataset wordt vervolgens gemaakt.
We kunnen de duidelijke lineaire relatie tussen de variabelen zien met de spreiding van de punten die de ruis of willekeurige fout in de relatie markeren.
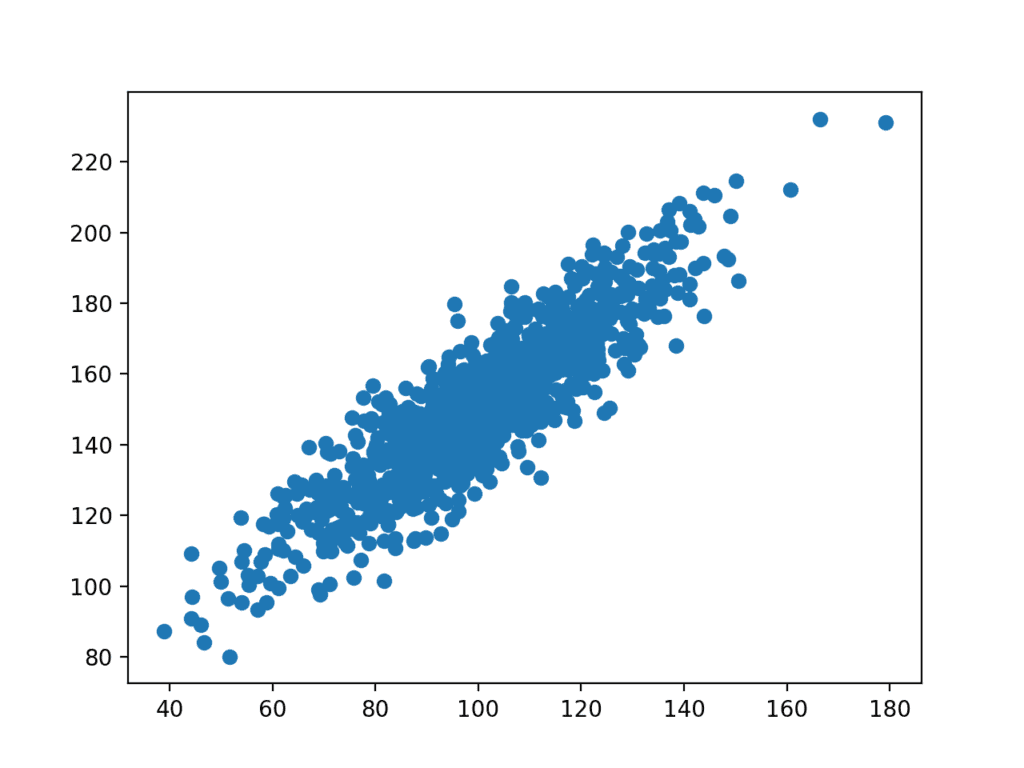
scatterplot van gerelateerde variabelen
vervolgens kunnen we een eenvoudige lineaire regressie ontwikkelen die gegeven de invoervariabele x, De y-variabele zal voorspellen. We kunnen de linregress () SciPy functie gebruiken om het model te passen en de B0-en b1-coëfficiënten voor het model terug te geven.
|
1
2
|
# fit linear regression model
b1, b0, r_value, p_value, std_err = linregress(x, y)
|
We can use the coefficients to calculate the predicted y values, called yhat, for each of the input variables. The resulting points will form a line that represents the learned relationship.
|
1
2
|
# make prediction
yhat = b0 + b1 * x
|
The complete example is listed below.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
# eenvoudige niet-lineaire regressie model
van numpy.random import randn
from numpy.random import seed
from scipy.stats import linregress
from matplotlib import pyplot
# seed random number generator
seed(1)
# prepare data
x = 20 * randn(1000) + 100
y = x + (10 * randn(1000) + 50)
# fit linear regression model
b1, b0, r_value, p_value, std_err = linregress(x, y)
print(‘b0=%.3f, b1=%.3f’ % (b1, b0))
# make prediction
yhat = b0 + b1 * x
# plot data and predictions
pyplot.scatter(x, y)
pyplot.plot(x, yhat, color=’r’)
pyplot.show()
|
Running the example fits the model and prints the coefficients.
|
1
|
b0=1.011, b1=49.117
|
De coëfficiënten worden vervolgens gebruikt bij de ingangen van de dataset om een voorspelling te doen. De resulterende ingangen en voorspelde y-waarden worden uitgezet als een lijn bovenop de scatter plot voor de dataset.
We kunnen duidelijk zien dat het model de onderliggende relatie in de dataset heeft geleerd.
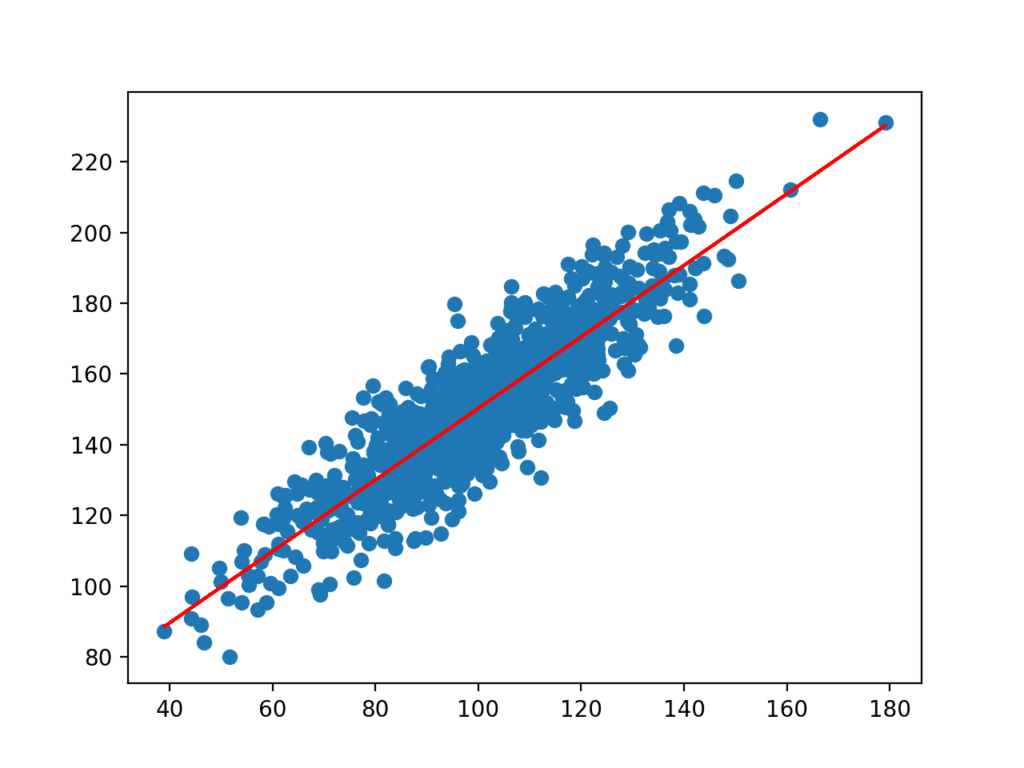
scatterplot van Dataset met lijn voor Simple Linear Regression Model
We zijn nu klaar om een voorspelling te maken met ons simple linear regression model en een voorspellingsinterval toe te voegen.
We passen in het model zoals voorheen. Deze keer nemen we één voorbeeld uit de dataset om het voorspellingsinterval te demonstreren. We gebruiken de input om een voorspelling te maken, berekenen het voorspellingsinterval voor de voorspelling, en vergelijken de voorspelling en het interval met de bekende verwachte waarde.
laten we eerst de invoer, Voorspelling en verwachte waarden definiëren.
|
1
2
3
|
x_in = x
y_out = y
yhat_out = yhat
|
Naast, kunnen we een schatting van de standaard kromming in de voorspelling richting.
|
1
|
SE = sqrt(1 / (N – 2) * e(i)^2 for i to N)
|
We can calculate this directly using the NumPy arrays as follows:
|
1
2
3
|
# estimate stdev of yhat
sum_errs = arraysum((y – yhat)**2)
stdev = sqrt(1/(len(y)-2) * sum_errs)
|
Next, we can calculate the prediction interval for our chosen input:
|
1
|
interval = z . stdev
|
We will use the significance level of 95%, which is 1.96 standard deviations.
Once the interval is calculated, we can summarize the bounds on the prediction to the user.
|
1
2
3
|
# calculate prediction interval
interval = 1.96 * stdev
lower, upper = yhat_out – interval, yhat_out + interval
|
We can tie all of this together. The complete example is listed below.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
|
# linear regression prediction with prediction interval
from numpy.random import randn
from numpy.random import seed
from numpy import power
from numpy import sqrt
from numpy import mean
from numpy import std
from numpy import sum as arraysum
from scipy.statistieken importeren linregress
van matplotlib importeren pyplot
# seed random number generator
zaad(1)
# de voorbereiding van de gegevens
x = 20 * randn(1000) + 100
y = x + (10 * randn(1000) + 50)
# past de niet-lineaire regressie model
b1, b0, r_value, p_value, std_err = linregress(x, y)
# markeer voorspellingen
yhat = b0 + b1 * x
# define nieuwe input, de verwachte waarde en een voorspelling
x_in = x
y_out = y
yhat_out = yhat
# schatting stdev van yhat
sum_errs = arraysum ((y – yhat) * * 2)
stdev = sqrt(1 /(len (y)-2) * sum_errs)
# bereken voorspellingsinterval
interval = 1.96 * stdev
print (‘voorspellingsinterval: %.3f ‘ % interval)
onder, boven = yhat_out – interval, yhat_out + interval
print (‘95% % waarschijnlijkheid dat de werkelijke waarde tussen %ligt.3f en %.3f ‘ % (lower, upper))
print (‘True value:%.3f ‘ % y_out)
# plot dataset en voorspelling met interval
pyplot.scatter (x, y)
pyplot.plot (x, yhat, color=’red’)
pyplot.errorbar (x_in, yhat_out, yerr=interval, color=’black’, fmt=’o’)
pyplot.show ()
|
het uitvoeren van het voorbeeld schat de standaarddeviatie van yhat en berekent vervolgens het voorspellingsinterval.
eenmaal berekend, wordt het voorspellingsinterval voor de gegeven invoervariabele aan de gebruiker gepresenteerd. Omdat we dit voorbeeld hebben bedacht, kennen we de ware uitkomst, die we ook laten zien. We kunnen zien dat in dit geval de 95% voorspellingsinterval de ware verwachte waarde dekt.
|
1
2
3
|
Prediction Interval: 20.204
95% likelihood that the true value is between 160.750 and 201.159
True value: 183.124
|
een plot wordt ook gemaakt met de ruwe dataset als een verstrooiingsdiagram, de voorspellingen voor de dataset als een rode lijn, en de voorspelling en voorspelling interval als een zwarte stip en lijn respectievelijk.
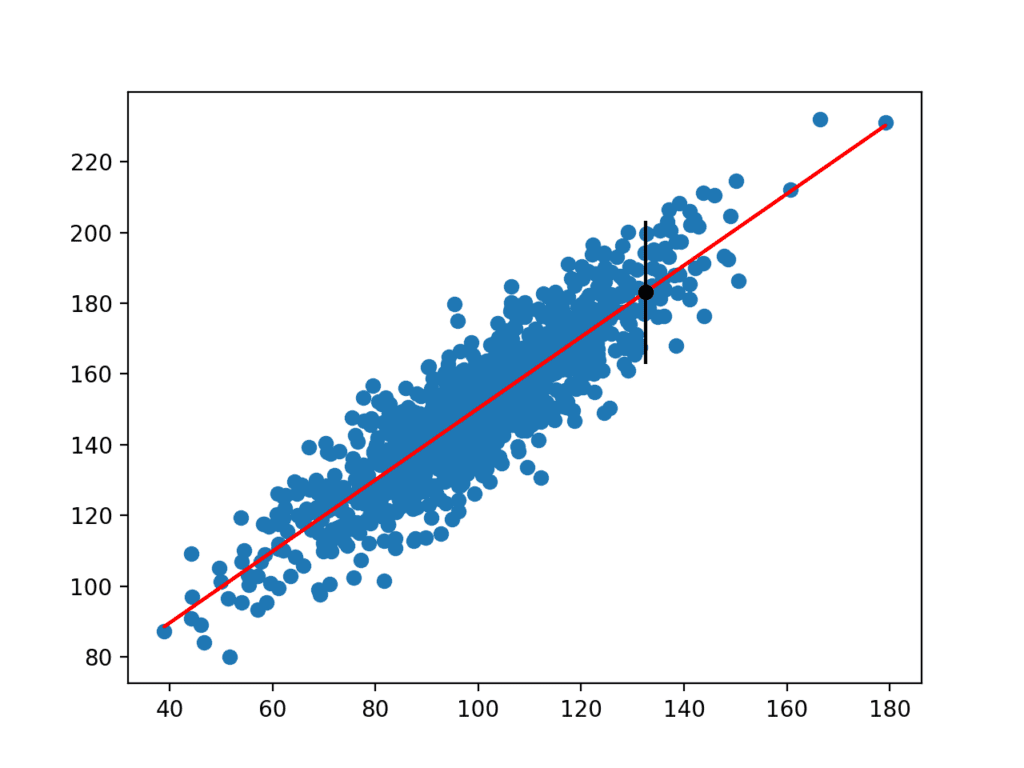
scatterplot van Dataset met lineair Model en voorspellingsinterval
uitbreidingen
Deze sectie bevat enkele ideeën voor het uitbreiden van de tutorial die u misschien wilt verkennen.
- vat het verschil tussen tolerantie, vertrouwen en voorspellingsintervallen samen.
- Ontwikkel een lineair regressiemodel voor een standaard machine learning dataset en bereken voorspellingsintervallen voor een kleine testset.
- beschrijf in detail hoe een niet-lineaire voorspellingsintervalmethode werkt.
Als u een van deze extensies verkent, zou ik dat graag willen weten.
verder lezen
Deze sectie biedt meer bronnen over het onderwerp als u dieper wilt gaan.
Berichten
- Hoe te Melden Classifier Prestaties met betrouwbaarheidsintervallen
- Hoe te Berekenen Bootstrap betrouwbaarheidsintervallen Voor Machine Learning Resultaten in Python
- Begrijpen tijdreeks Weersverwachting Onzekerheid met Behulp van betrouwbaarheidsintervallen met Python
- een Schatting van het Aantal van het Experiment wordt Herhaald voor Stochastische Machine Learning Algoritmen
Boeken
- het Begrijpen van De Nieuwe Statistieken: Effect sizes, betrouwbaarheidsintervallen, en Meta-Analyse, en met 2017.
- Statistical intervallen: a Guide for Practitioners and Researchers, 2017.
- An Introduction to Statistical Learning: with Applications in R, 2013.
- Introduction to the New Statistics: Estimation, Open Science, and Beyond, 2016.
- Forecasting: principles and practice, 2013.
Papers
- A comparison of some error estimates for neural network models, 1995.
- Machine learning approaches for estimation of prediction interval for the model output, 2006.
- A Comprehensive Review of Neural Network-based Prediction intervallen and New Advances, 2010.
API
- scipy.Statistiek.linregress () API
- matplotlib.pyplot.scatter () API
- matplotlib.pyplot.errorbar () API
artikelen
- voorspellingsinterval op Wikipedia
- Bootstrap voorspellingsinterval op Cross gevalideerd
samenvatting
In deze tutorial ontdekte u het voorspellingsinterval en hoe u dit kunt berekenen voor een eenvoudig lineair regressiemodel.
specifiek leerde u:
- dat een voorspellingsinterval de onzekerheid van een voorspelling met één punt kwantificeert.
- dat voorspellingsintervallen analytisch kunnen worden geschat voor eenvoudige modellen, maar uitdagender zijn voor niet-lineaire machine learning modellen.
- het voorspellingsinterval berekenen voor een eenvoudig lineair regressiemodel.
heeft u vragen?
Stel uw vragen in de opmerkingen hieronder en Ik zal mijn best doen om te beantwoorden.
Krijg grip op statistieken voor Machine Learning!

ontwikkelen van een goed begrip van statistieken
…door het schrijven van regels code in python
ontdek hoe in mijn nieuwe Ebook:
statistische methoden voor Machine Learning
Het biedt zelfstudie tutorials over onderwerpen als:
Hypothesis Tests, correlatie, niet-parametrische statistieken, Resampling, en nog veel meer…
ontdek hoe gegevens in kennis kunnen worden omgezet
sla de academici over. Alleen Resultaten.
bekijk wat er in