wprowadzenie
w narzędziach do zarządzania bazami danych dominuje relacyjny model danych, który porządkuje dane w tabelach wierszy i kolumn. Obecnie istnieją inne modele danych, w tym NoSQL i NewSQL, ale relacyjne systemy zarządzania bazami danych (rdbmss) pozostają dominujące w przechowywaniu i zarządzaniu danymi na całym świecie.
Ten artykuł porównuje i kontrastuje trzy z najczęściej wdrażanych RDBMSs open-source: SQLite, MySQL i PostgreSQL. W szczególności zbada typy danych, których używa każdy RDBMS, ich zalety i wady oraz sytuacje, w których są najlepiej zoptymalizowane.
trochę o systemach zarządzania bazami danych
bazy danych są logicznie modelowanymi klastrami informacji lub danych. System zarządzania bazą danych (DBMS), z drugiej strony, to program komputerowy, który współdziała z bazą danych. DBMS umożliwia kontrolowanie dostępu do bazy danych, zapisywanie danych, uruchamianie zapytań i wykonywanie innych zadań związanych z zarządzaniem bazą danych. Chociaż systemy zarządzania bazami danych są często określane jako „bazy danych”, te dwa terminy nie są wymienne. Baza danych może być dowolnym zbiorem danych, nie tylko przechowywanym na komputerze, podczas gdy DBMS jest oprogramowaniem, które pozwala na interakcję z bazą danych.
wszystkie systemy zarządzania bazami danych mają podstawowy model, który strukturyzuje sposób przechowywania i dostępu do danych. Relacyjny system zarządzania bazami danych to DBMS wykorzystujący relacyjny model danych. W tym modelu dane są zorganizowane w tabele, które w kontekście RDBMSs są bardziej formalnie określane jako relacje.
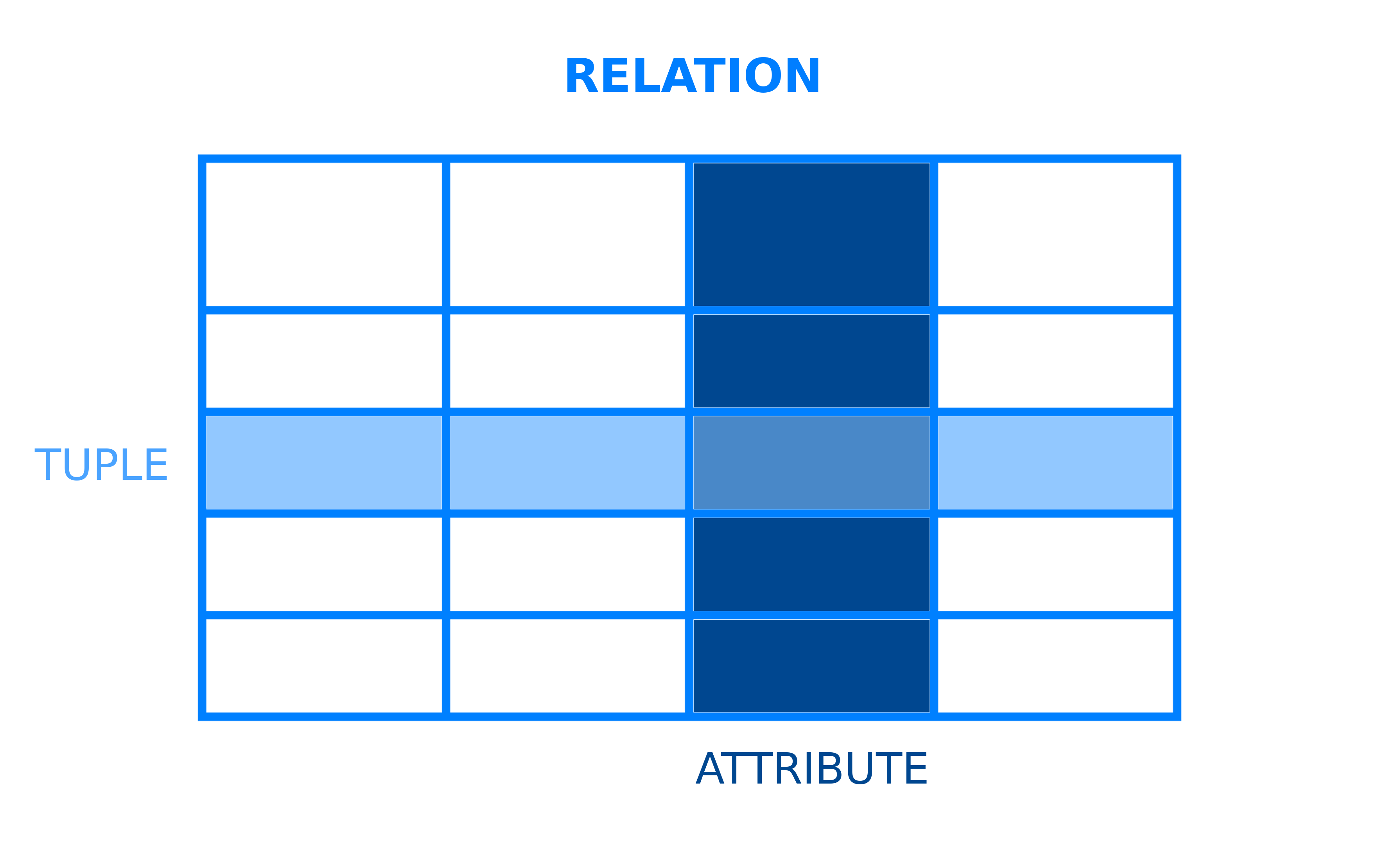
Większość relacyjnych baz danych używa strukturalnego języka zapytań (SQL) do zarządzania danymi i zapytań. Jednak wiele RDBMS używa własnego specyficznego dialektu SQL, który może mieć pewne ograniczenia lub rozszerzenia. Rozszerzenia te zazwyczaj zawierają dodatkowe funkcje, które umożliwiają użytkownikom wykonywanie bardziej złożonych operacji niż w przypadku standardowego SQL.
Uwaga: Termin „standardowy SQL” pojawia się kilka razy w tym przewodniku. Normy SQL są wspólnie utrzymywane przez American National Standards Institute (ANSI), Międzynarodową Organizację Normalizacyjną (ISO) oraz Międzynarodową Komisję elektrotechniczną (IEC). Ilekroć ten artykuł wspomina „standard SQL” lub „standard SQL”, odnosi się do bieżącej wersji standardu SQL opublikowanego przez te organy.
należy zauważyć, że pełny standard SQL jest duży i złożony: pełna zgodność z rdzeniem SQL:2011 wymaga 179 funkcji. Z tego powodu większość RDBMSs nie obsługuje całego standardu, chociaż niektóre są bliżej pełnej zgodności niż inne.
każdej kolumnie przypisany jest typ danych, który określa, jakiego rodzaju wpisy są dozwolone w tej kolumnie. Różne RDBMSs implementują różne typy danych, które nie zawsze są bezpośrednio wymienne. Niektóre popularne typy danych obejmują daty, ciągi znaków, liczby całkowite i wartości logiczne.
Numeryczne typy danych mogą być podpisane, co oznacza, że mogą reprezentować zarówno liczby dodatnie, jak i ujemne, lub niepodpisane, co oznacza, że mogą reprezentować tylko liczby dodatnie. Na przykład typ danych MySQL tinyint może zawierać 8 bitów danych, co odpowiada 256 możliwym wartościom. Signed range tego typu danych to od -128 do 127, natomiast unsigned range to od 0 do 255.
czasami administrator bazy danych nakłada ograniczenie na tabelę, aby ograniczyć, jakie wartości można do niej wprowadzić. Ograniczenie zwykle dotyczy jednej konkretnej kolumny, ale niektóre ograniczenia mogą również dotyczyć całej tabeli. Oto kilka ograniczeń, które są powszechnie używane w SQL:
-
UNIQUE: Zastosowanie tego ograniczenia do kolumny zapewnia, że żadne dwa wpisy w tej kolumnie nie są identyczne. -
NOT NULL: to ograniczenie zapewnia, że kolumna nie ma żadnych wpisówNULL. -
PRIMARY KEY: połączenieUNIQUEINOT NULLPRIMARY KEYograniczenie zapewnia, że żaden wpis w kolumnie nie jestNULLI że każdy wpis jest odrębny. -
FOREIGN KEYFOREIGN KEYjest kolumną w jednej tabeli, która odnosi się doPRIMARY KEYinnej tabeli. To ograniczenie jest używane do łączenia dwóch tabel: wpisy do kolumnyFOREIGN KEYmuszą już istnieć w kolumnie rodzicaPRIMARY KEY, aby proces zapisu przebiegał pomyślnie. -
CHECK: to ograniczenie ogranicza zakres wartości, które można wprowadzić do kolumny. Na przykład, jeśli Twoja aplikacja jest przeznaczona tylko dla mieszkańców Alaski, możesz dodać ograniczenieCHECKw kolumnie kodu pocztowego, aby zezwalać tylko na wpisy między 99501 a 99950.
Jeśli chcesz dowiedzieć się więcej o systemach zarządzania bazami danych, zapoznaj się z naszym artykułem na temat zrozumienia baz danych SQL i NoSQL oraz różnych modeli baz danych.
teraz, gdy omówiliśmy ogólnie relacyjne systemy zarządzania bazami danych, przejdźmy do pierwszej z trzech relacyjnych baz danych open-source ten artykuł obejmie: SQLite.
SQLite
SQLite jest samodzielnym, opartym na plikach i w pełni otwartym oprogramowaniem RDBMS znanym z przenośności, niezawodności i wysokiej wydajności nawet w środowiskach o niskiej pamięci. Jego transakcje są zgodne z normą ACID, nawet w przypadku awarii systemu lub przerwy w zasilaniu.
strona projektu SQLite opisuje ją jako bazę danych „bezserwerową”. Większość silników relacyjnych baz danych jest zaimplementowana jako proces serwera, w którym programy komunikują się z serwerem hosta poprzez komunikację międzyprocesową, która przekazuje żądania. Jednak w przypadku SQLite każdy proces, który uzyskuje dostęp do bazy danych, odczytuje i zapisuje bezpośrednio do pliku dysku bazy danych. Upraszcza to proces konfiguracji SQLite, ponieważ eliminuje potrzebę konfigurowania procesu serwera. Podobnie, nie ma potrzeby konfigurowania programów, które będą korzystać z bazy danych SQLite: wszystko, czego potrzebują, to dostęp do dysku.
SQLite jest wolnym i otwartym oprogramowaniem i nie jest wymagana żadna specjalna licencja do jego używania. Jednak projekt oferuje kilka rozszerzeń-każdy za jednorazową opłatą-które pomagają w kompresji i szyfrowaniu. Ponadto projekt oferuje różne pakiety wsparcia komercyjnego, każdy za opłatą roczną.
Obsługiwane typy danych SQLite
SQLite pozwala na różne typy danych, zorganizowane w następujące klasy pamięci:
| typ danych | Wyjaśnienie |
|---|---|
null |
zawiera dowolne wartościNULL. |
| Signed integers, stored in 1, 2, 3, 4, 6, lub 8 bajtów w zależności od wielkości wartości. | |
| liczby rzeczywiste lub wartości zmiennoprzecinkowe, przechowywane jako 8-bajtowe liczby zmiennoprzecinkowe. | |
| ciągi tekstowe przechowywane przy użyciu kodowania bazy danych, które może być UTF-8, UTF-16BE lub UTF-16LE. | |
| dowolny obiekt blob danych, z każdym obiektem Blob zapisanym dokładnie tak, jak został wprowadzony. |
w kontekście SQLite terminy „Klasa pamięci” i „typ danych” są uważane za wymienne. Jeśli chcesz dowiedzieć się więcej o typach danych SQLite i powinowactwie typu SQLite, zapoznaj się z oficjalną dokumentacją SQLite na ten temat.
zalety SQLite
- mały rozmiar: jak sama nazwa wskazuje, biblioteka SQLite jest bardzo lekka. Chociaż przestrzeń, z której korzysta, różni się w zależności od systemu, w którym jest zainstalowany, może zająć mniej niż 600 Kb miejsca. Dodatkowo jest w pełni autonomiczny, co oznacza, że nie ma żadnych zewnętrznych zależności, które musisz zainstalować w systemie, aby SQLite działał.
- przyjazny dla użytkownika: SQLite jest czasami opisywany jako baza danych „zerowej konfiguracji”, która jest gotowa do użycia po wyjęciu z pudełka. SQLite nie działa jako proces serwera, co oznacza, że nigdy nie trzeba go zatrzymywać, uruchamiać ani ponownie uruchamiać i nie zawiera żadnych plików konfiguracyjnych, którymi należy zarządzać. Funkcje te pomagają usprawnić ścieżkę od instalacji SQLite do integracji z aplikacją.
- Portable: W przeciwieństwie do innych systemów zarządzania bazami danych, które zazwyczaj przechowują dane jako dużą partię oddzielnych plików, cała baza danych SQLite jest przechowywana w jednym pliku. Plik ten może znajdować się w dowolnym miejscu w hierarchii katalogów i może być udostępniany za pomocą nośników wymiennych lub protokołu przesyłania plików.
wady SQLite
- ograniczona współbieżność: chociaż wiele procesów może uzyskać dostęp do bazy danych SQLite i odpytywać ją jednocześnie, tylko jeden proces może wprowadzać zmiany w bazie danych w danym momencie. Oznacza to, że SQLite obsługuje większą współbieżność niż większość innych wbudowanych systemów zarządzania bazami danych, ale nie tak bardzo, jak RDBMS klientów/serwerów, takich jak MySQL lub PostgreSQL.
- brak zarządzania użytkownikami: systemy bazodanowe często mają wsparcie dla użytkowników lub zarządzane połączenia z predefiniowanymi uprawnieniami dostępu do bazy danych i tabel. Ponieważ SQLite odczytuje i zapisuje bezpośrednio do zwykłego pliku dysku, jedynymi uprawnieniami dostępu są typowe uprawnienia dostępu bazowego systemu operacyjnego. To sprawia, że SQLite jest złym wyborem dla aplikacji, które wymagają wielu użytkowników ze specjalnymi uprawnieniami dostępu.
- bezpieczeństwo: silnik bazy danych, który korzysta z serwera, może w niektórych przypadkach zapewnić lepszą ochronę przed błędami w aplikacji klienckiej niż bezserwerowa baza danych, taka jak SQLite. Na przykład, bezpańskie wskaźniki w kliencie nie mogą uszkodzić pamięci na serwerze. Ponadto, ponieważ serwer jest pojedynczym trwałym procesem, baza danych klient-serwer może uzyskać dostęp do danych z większą precyzją niż bezserwerowa baza danych, umożliwiając bardziej precyzyjne blokowanie i lepszą współbieżność.
kiedy używać SQLite
- aplikacje wbudowane: SQLite to świetny wybór bazy danych dla aplikacji, które wymagają przenośności i nie wymagają przyszłej rozbudowy. Przykłady obejmują aplikacje lokalne dla pojedynczego użytkownika oraz aplikacje mobilne lub gry.
- wymiana dostępu do dysku: w przypadkach, gdy aplikacja musi bezpośrednio odczytywać i zapisywać pliki na dysku, korzystne może być użycie SQLite dla dodatkowej funkcjonalności i prostoty związanej z użyciem SQL.
- testowanie: W przypadku wielu aplikacji testowanie ich funkcjonalności za pomocą DBMS, który wykorzystuje dodatkowy proces serwera, może być przesadą. SQLite ma tryb w pamięci, który może być używany do szybkiego uruchamiania testów bez obciążania rzeczywistych operacji na bazie danych, co czyni go idealnym wyborem do testowania.
kiedy nie używać SQLite
- praca z dużą ilością danych: SQLite może technicznie obsługiwać bazę danych o rozmiarze do 140 TB, o ile dysk i system plików również obsługują wymagania dotyczące rozmiaru bazy danych. Jednak strona internetowa SQLite zaleca, aby każda baza danych zbliżająca się do 1 TB była umieszczona w scentralizowanej bazie danych klient-serwer, ponieważ baza danych SQLite o tej lub większej wielkości byłaby trudna do zarządzania.
- wysoki wolumen zapisu: SQLite pozwala na wykonanie tylko jednej operacji zapisu w danym momencie, co znacznie ogranicza jego przepustowość. Jeśli Twoja aplikacja wymaga wielu operacji zapisu lub wielu jednoczesnych zapisów, SQLite może nie być odpowiedni dla Twoich potrzeb.
- wymagany jest dostęp do sieci: Ponieważ SQLite jest bazą danych bezserwerową, nie zapewnia bezpośredniego dostępu sieciowego do swoich danych. Dostęp ten jest wbudowany w aplikację, więc jeśli dane w SQLite znajdują się na oddzielnym komputerze od aplikacji, będzie to wymagało łącza engine-to-disk o dużej przepustowości w całej sieci. Jest to kosztowne, nieefektywne rozwiązanie i w takich przypadkach lepszym wyborem może być DBMS klient-serwer.
MySQL
według rankingu DB-Engines, MySQL jest najpopularniejszym open-source RDBMS od czasu, gdy strona zaczęła śledzić popularność baz danych w 2012 roku. Jest to bogaty w funkcje produkt, który zasila wiele największych witryn i aplikacji na świecie, w tym Twitter, Facebook, Netflix i Spotify. Rozpoczęcie pracy z MySQL jest stosunkowo proste, w dużej mierze dzięki wyczerpującej dokumentacji i dużej społeczności programistów, a także obfitości zasobów związanych z MySQL online.
MySQL został zaprojektowany z myślą o szybkości i niezawodności, kosztem pełnego przestrzegania standardu SQL. Programiści MySQL nieustannie pracują nad zbliżeniem się do standardowego SQL, ale nadal pozostaje w tyle za innymi implementacjami SQL. Ma jednak różne tryby SQL i rozszerzenia, które przybliżają go do zgodności. W przeciwieństwie do aplikacji używających SQLite, aplikacje korzystające z bazy danych MySQL uzyskują do niej dostęp poprzez oddzielny proces demona. Ponieważ proces serwera stoi pomiędzy bazą danych a innymi aplikacjami, pozwala na większą kontrolę nad tym, kto ma dostęp do bazy danych.
MySQL zainspirował wiele aplikacji, narzędzi i zintegrowanych bibliotek innych firm, które rozszerzają jego funkcjonalność i ułatwiają pracę. Niektóre z szerzej używanych narzędzi innych firm to phpMyAdmin, DBeaver i HeidiSQL.
Obsługiwane typy danych MySQL
typy danych MySQL można podzielić na trzy szerokie kategorie: typy liczbowe, typy daty i czasu oraz typy ciągów znaków.
typy liczbowe:
| typ danych | Wyjaśnienie |
|---|---|
tinyint |
bardzo mała liczba całkowita. Zakres sygnowany dla tego numerycznego typu danych wynosi od -128 do 127, podczas gdy zakres unsigned wynosi od 0 do 255. |
| mała liczba całkowita. Zakres sygnowany dla tego typu numerycznego wynosi od -32768 do 32767, podczas gdy zakres niepodpisany wynosi od 0 do 65535. | |
| średniej wielkości liczba całkowita. Zakres sygnowany dla tego numerycznego typu danych wynosi od -8388608 do 8388607, natomiast zakres unsigned wynosi od 0 do 16777215. | |
| liczba całkowita o normalnym rozmiarze. Zakres sygnowany dla tego numerycznego typu danych wynosi od -2147483648 do 2147483647, natomiast zakres bez znaku wynosi od 0 do 4294967295. | |
| duża liczba całkowita. Sygnowany zakres dla tego numerycznego typu danych wynosi od -9223372036854775808 do 9223372036854775807, podczas gdy zakres bez znaku wynosi od 0 do 18446744073709551615. | |
| mała liczba zmiennoprzecinkowa. | |
| Liczba zmiennoprzecinkowa o normalnym rozmiarze (Podwójna precyzja). | |
| spakowany numer punktu stałego. Długość wyświetlania wpisów dla tego typu danych jest definiowana podczas wytworzenia kolumny i każdy wpis jest do tej długości. | |
Boolean to typ danych, który ma tylko dwie możliwe wartości, Zwykle truelub false. |
|
| typ wartości bitowej, dla której można określić liczbę bitów na wartość, od 1 do 64. |
typy daty i czasu:
| Data Type | Explanation |
|---|---|
date |
A date, represented as YYYY-MM-DD. |
datetime |
A timestamp showing the date and time, displayed as YYYY-MM-DD HH:MM:SS. |
timestamp |
A timestamp indicating the amount of time since the Unix epoch (00:00:00 on January 1, 1970). |
time |
A time of day, displayed as HH:MM:SS. |
year |
A year expressed in either a 2 or 4 digit format, with 4 digits being the default. |
String types:
| Data Type | Explanation |
|---|---|
char |
A fixed-length string; wpisy tego typu są wyściełane po prawej stronie spacjami, aby spełnić określoną długość podczas przechowywania. |
| ciąg znaków o zmiennej długości. | |
podobny do typu char, ale binarny łańcuch bajtów o określonej długości, a nie Niestandardowy łańcuch znaków. |
|
podobny do typu varchar, ale binarny łańcuch bajtów o zmiennej długości, a nie Niestandardowy łańcuch znaków. |
|
blob |
A binary string with a maximum length of 65535 (2^16 – 1) bytes of data. |
tinyblob |
A blob column with a maximum length of 255 (2^8 – 1) bytes of data. |
mediumblob |
A blob column with a maximum length of 16777215 (2^24 – 1) bytes of data. |
longblob |
A blob column with a maximum length of 4294967295 (2^32 – 1) bytes of data. |
text |
A string with a maximum length of 65535 (2^16 – 1) characters. |
tinytext |
A text column with a maximum length of 255 (2^8 – 1) characters. |
mediumtext |
A text column with a maximum length of 16777215 (2^24 – 1) characters. |
longtext |
A text column with a maximum length of 4294967295 (2^32 – 1) characters. |
| wyliczenie, które jest obiektem łańcuchowym, który pobiera pojedynczą wartość z listy wartości zadeklarowanych podczas tworzenia tabeli. | |
| obiekt typu string, który może mieć zero lub więcej wartości, z których każda musi być wybrana z listy dozwolonych wartości, które są określone podczas tworzenia tabeli. |
zalety MySQL
- popularność i łatwość obsługi: Jako jeden z najpopularniejszych systemów bazodanowych na świecie nie brakuje administratorów baz danych, którzy mają doświadczenie w pracy z MySQL. Podobnie, istnieje mnóstwo dokumentacji drukowanej i online na temat instalacji i zarządzania bazą danych MySQL, a także wiele narzędzi innych firm-takich jak phpMyAdmin — które mają na celu uproszczenie procesu rozpoczynania pracy z bazą danych.
- bezpieczeństwo: MySQL jest instalowany ze skryptem, który pomaga poprawić bezpieczeństwo bazy danych, ustawiając poziom bezpieczeństwa hasła instalacji, definiując hasło dla użytkownika root, usuwając anonimowe konta i usuwając testowe bazy danych, które są domyślnie dostępne dla wszystkich użytkowników. Ponadto, w przeciwieństwie do SQLite, MySQL obsługuje zarządzanie użytkownikami i umożliwia przyznawanie uprawnień dostępu dla każdego użytkownika.
- szybkość: decydując się nie implementować pewnych funkcji SQL, Programiści MySQL byli w stanie nadać priorytet szybkości. Podczas gdy nowsze testy benchmarkowe pokazują, że inne Rdbmsy, takie jak PostgreSQL, mogą pasować lub przynajmniej zbliżać się do MySQL pod względem szybkości, MySQL nadal ma reputację niezwykle szybkiego rozwiązania bazodanowego.
- replikacja: MySQL obsługuje wiele różnych typów replikacji, które są praktyką udostępniania informacji między dwoma lub więcej hostami, aby poprawić niezawodność, dostępność i odporność na błędy. Jest to pomocne w konfigurowaniu rozwiązania do tworzenia kopii zapasowych bazy danych lub poziomego skalowania bazy danych.
wady MySQL
- znane ograniczenia: Ponieważ MySQL został zaprojektowany z myślą o szybkości i łatwości użycia, a nie pełnej zgodności z SQL, ma pewne ograniczenia funkcjonalne. Na przykład nie obsługuje klauzul
FULL JOIN. - licencjonowanie i funkcje własnościowe: MySQL jest oprogramowaniem z podwójną licencją, z darmową i otwartą edycją społeczności na licencji GPLv2 i kilkoma płatnymi komercyjnymi edycjami wydanymi na licencjach własnościowych. Z tego powodu niektóre funkcje i wtyczki są dostępne tylko dla wersji zastrzeżonych.
- spowolnił rozwój: Od czasu przejęcia projektu MySQL przez Sun Microsystems w 2008 roku, a później przez Oracle Corporation w 2009 roku, użytkownicy skarżyli się, że proces rozwoju DBMS znacznie spowolnił, ponieważ społeczność nie ma już agencji, aby szybko reagować na problemy i wdrażać zmiany.
kiedy używać MySQL
- operacje rozproszone: Obsługa replikacji MySQL sprawia, że jest to doskonały wybór dla rozproszonych konfiguracji baz danych, takich jak architektury primary-secondary lub primary-primary.
- strony internetowe i aplikacje internetowe: MySQL zasila wiele stron internetowych i aplikacji w Internecie. Jest to w dużej mierze spowodowane tym, jak łatwo jest zainstalować i skonfigurować bazę danych MySQL, a także jej ogólną szybkością i skalowalnością w dłuższej perspektywie.
- oczekiwany przyszły wzrost: obsługa replikacji MySQL może ułatwić skalowanie poziome. Ponadto jest to stosunkowo prosty proces aktualizacji do komercyjnego produktu MySQL, takiego jak MySQL Cluster, który obsługuje automatyczne sharding, kolejny proces skalowania poziomego.
kiedy nie używać MySQL
- wymagana jest zgodność z SQL: Ponieważ MySQL nie próbuje zaimplementować pełnego standardu SQL, to narzędzie nie jest całkowicie zgodne z SQL. Jeśli kompletna lub nawet prawie kompletna zgodność z SQL jest koniecznością dla Twojego przypadku użycia, możesz użyć bardziej zgodnego DBMS.
- współbieżność i duże ilości danych: chociaż MySQL na ogół dobrze radzi sobie z operacjami wymagającymi dużej ilości odczytu, współbieżne operacje odczytu i zapisu mogą być problematyczne. Jeśli w Twojej aplikacji będzie wielu użytkowników zapisujących do niej dane naraz, innym RDBMS, takim jak PostgreSQL, może być lepszy wybór bazy danych.
PostgreSQL
PostgreSQL, znany również jako Postgres, określa się jako „najbardziej zaawansowana relacyjna baza danych open-source na świecie.”Został stworzony z myślą o tym, aby był wysoce rozszerzalny i Zgodny ze standardami. PostgreSQL jest obiektowo-relacyjną bazą danych, co oznacza, że chociaż jest to przede wszystkim relacyjna baza danych, zawiera również funkcje — takie jak dziedziczenie tabeli i przeciążanie funkcji — które są częściej kojarzone z obiektowymi bazami danych.
Postgres jest w stanie efektywnie obsłużyć wiele zadań w tym samym czasie, co cecha znana jako współbieżność. Osiąga to bez blokad odczytu dzięki implementacji Multiversion Concurrency Control (MVCC), która zapewnia atomiczność, spójność, izolację i trwałość swoich transakcji, znaną również jako ACID compliance.
PostgreSQL nie jest tak szeroko stosowany jak MySQL, ale nadal istnieje wiele narzędzi i bibliotek innych firm zaprojektowanych w celu uproszczenia pracy z PostgreSQL, w tym pgAdmin i Postbird.
Obsługiwane typy danych PostgreSQL
PostgreSQL obsługuje typy danych liczbowych, łańcuchowych oraz daty i czasu, takie jak MySQL. Ponadto obsługuje typy danych dla kształtów geometrycznych, adresów sieciowych, ciągów bitowych, wyszukiwań tekstowych i wpisów JSON, a także kilka idiosynkratycznych typów danych.
typy liczbowe:
| typ danych | Wyjaśnienie |
|---|---|
bigint |
a signed 8 byte integer. |
bigserial |
An autoincrementing 8 byte integer. |
double precision |
An 8 byte double precision floating-point number. |
integer |
A signed 4 byte integer. |
numeric or decimal |
An number of selectable precision, recommended for use in cases where exactness is crucial, such as monetary amounts. |
real |
A 4 byte single precision floating-point number. |
smallint |
A signed 2 byte integer. |
smallserial |
An autoincrementing 2 byte integer. |
serial |
An autoincrementing 4 byte integer. |
Character types:
| Data Type | Explanation |
|---|---|
character |
A character string with a specified fixed length. |
character varying or varchar |
A character string with a variable but limited length. |
text |
A character string of a variable, unlimited length. |
Date and time types:
| Data Type | Explanation |
|---|---|
date |
A calendar date consisting of the day, month, and year. |
interval |
A time span. |
time or time without time zone |
A time of day, not including the time zone. |
time with time zone |
A time of day, including the time zone. |
timestamp or timestamp without time zone |
A date and time, not including the time zone. |
timestamp with time zone |
A date and time, including the time zone. |
Geometric types:
| Data Type | Explanation |
|---|---|
box |
A rectangular box on a plane. |
circle |
A circle on a plane. |
line |
An infinite line on a plane. |
lseg |
A line segment on a plane. |
path |
A geometric path on a plane. |
point |
A geometric point on a plane. |
polygon |
A closed geometric path on a plane. |
Network address types:
| Data Type | Explanation |
|---|---|
cidr |
An IPv4 or IPv6 network address. |
inet |
An IPv4 or IPv6 host address. |
macaddr |
A Media Access Control (MAC) address. |
Bit string types:
| Data Type | Explanation |
|---|---|
bit |
A fixed-length bit string. |
bit varying |
A variable-length bit string. |
Text search types:
| Data Type | Explanation |
|---|---|
tsquery |
A text search query. |
tsvector |
A text search document. |
JSON types:
| Data Type | Explanation |
|---|---|
json |
Textual JSON data. |
jsonb |
Decomposed binary JSON data. |
Other data types:
| Data Type | Explanation |
|---|---|
boolean |
A logical Boolean, representing either true or false. |
bytea |
Short for „byte array”, this type is used for binary data. |
money |
An amount of currency. |
pg_lsn |
A PostgreSQL Log Sequence Number. |
txid_snapshot |
A user-level transaction ID snapshot. |
uuid |
A universally unique identifier. |
xml |
XML data. |
Advantages of PostgreSQL
- SQL compliance: More so than SQLite or MySQL, PostgreSQL aims to closely adhere to SQL standards. According to the official PostgreSQL documentation, PostgreSQL supports 160 out of the 179 features required for full core SQL:2011 zgodność, oprócz długiej listy opcjonalnych funkcji.
- Open-source i napędzane przez społeczność: w pełni otwarty projekt, kod źródłowy PostgreSQL jest rozwijany przez dużą i oddaną społeczność. Podobnie, społeczność Postgres utrzymuje i przyczynia się do wielu zasobów online, które opisują, jak pracować z DBMS, w tym oficjalnej dokumentacji, wiki PostgreSQL i różnych forach internetowych.
- Extensible: użytkownicy mogą programowo i w locie rozszerzać PostgreSQL poprzez działanie oparte na katalogu i wykorzystanie dynamicznego ładowania. Można wyznaczyć plik kodu obiektowego, taki jak biblioteka współdzielona, a PostgreSQL załaduje go w razie potrzeby.
wady PostgreSQL
- wydajność pamięci: dla każdego nowego połączenia z klientem PostgreSQL tworzy nowy proces. Każdy nowy Proces jest przydzielany około 10MB pamięci, która może szybko sumować się dla baz danych z dużą ilością połączeń. W związku z tym, w przypadku prostych operacji wymagających dużego odczytu, PostgreSQL jest zazwyczaj mniej wydajny niż inne RDBMSs, takie jak MySQL.
- popularność: Chociaż PostgreSQL jest szeroko stosowany w ostatnich latach, historycznie pozostaje w tyle za MySQL pod względem popularności. Jedną z konsekwencji jest to, że wciąż jest mniej narzędzi innych firm, które mogą pomóc w zarządzaniu bazą danych PostgreSQL. Podobnie, nie ma tak wielu administratorów baz danych z doświadczeniem w zarządzaniu bazą danych Postgres w porównaniu do tych z doświadczeniem MySQL.
kiedy używać PostgreSQL
- integralność danych jest ważna: PostgreSQL jest w pełni zgodny z ACID od 2001 roku i wdraża kontrolę walutową multiversion, aby zapewnić spójność danych, co czyni go silnym wyborem RDBMS, gdy integralność danych jest krytyczna.
- integracja z innymi narzędziami: PostgreSQL jest kompatybilny z szeroką gamą języków programowania i platform. Oznacza to, że jeśli kiedykolwiek będziesz musiał przeprowadzić migrację bazy danych do innego systemu operacyjnego lub zintegrować ją z konkretnym narzędziem, prawdopodobnie będzie to łatwiejsze z bazą danych PostgreSQL niż z innym DBMS.
- kompleksowe operacje: Postgres obsługuje plany zapytań, które mogą wykorzystywać wiele procesorów w celu szybszego odpowiadania na zapytania. To, w połączeniu z silną obsługą wielu jednoczesnych pisarzy, sprawia, że jest to doskonały wybór dla złożonych operacji, takich jak hurtownia danych i przetwarzanie transakcji online.
kiedy nie używać PostgreSQL
- szybkość jest niezbędna: kosztem szybkości, PostgreSQL został zaprojektowany z myślą o rozszerzalności i kompatybilności. Jeśli twój projekt wymaga najszybszych operacji odczytu, PostgreSQL może nie być najlepszym wyborem DBMS.
- proste ustawienia: Ze względu na duży zestaw funkcji i silne przestrzeganie standardowego SQL, Postgres może być przesadą dla prostych konfiguracji baz danych. W przypadku operacji wymagających dużej prędkości odczytu, MySQL jest zazwyczaj bardziej praktycznym wyborem.
- złożona replikacja: chociaż PostgreSQL zapewnia silne wsparcie dla replikacji, jest to wciąż stosunkowo nowa funkcja, a niektóre konfiguracje — jak architektura primary-primary — są możliwe tylko z rozszerzeniami. Replikacja jest bardziej dojrzałą funkcją MySQL i wielu użytkowników uważa, że replikacja MySQL jest łatwiejsza do wdrożenia, szczególnie dla tych, którzy nie mają wymaganego doświadczenia w administrowaniu bazą danych i systemem.
podsumowanie
dzisiaj SQLite, MySQL i PostgreSQL są trzema najpopularniejszymi systemami zarządzania relacyjnymi bazami danych open-source na świecie. Każdy z nich ma swoje unikalne cechy i ograniczenia i wyróżnia się w określonych scenariuszach. Wybór RDBMS rzadko jest tak prosty, jak wybranie najszybszego lub z największą liczbą funkcji. Następnym razem, gdy będziesz potrzebował rozwiązania relacyjnej bazy danych, koniecznie zbadaj te i inne narzędzia dogłębnie, aby znaleźć takie, które najlepiej odpowiada twoim potrzebom.
Jeśli chcesz dowiedzieć się więcej o SQL i jak go używać do zarządzania relacyjną bazą danych, zachęcamy do zapoznania się z naszym arkuszem ściągi jak zarządzać bazą danych SQL. Z drugiej strony, jeśli chcesz dowiedzieć się więcej o nierelacyjnych bazach danych (lub NoSQL), sprawdź nasze porównanie systemów zarządzania bazami danych NoSQL.