Introduction
the relational data model, which organizes data in tables of rows and columns, predominates in database management tools. Hoje existem outros modelos de dados, incluindo NoSQL e NewSQL, mas os sistemas de gerenciamento de banco de dados relacionais (RDBMSs) permanecem dominantes para armazenar e Gerenciar dados em todo o mundo.
Este artigo compara e contrasta três dos RDBMSs de código aberto mais amplamente implementados: SQLite, MySQL, e PostgreSQL. Especificamente, ele irá explorar os tipos de dados que cada RDBMS usa, suas vantagens e desvantagens, e situações em que eles são melhor otimizados.
a Bit About Database Management Systems
Databases are logically modeled clusters of information, or data. Um sistema de gerenciamento de banco de dados (DBMS), por outro lado, é um programa de computador que interage com um banco de dados. Um DBMS permite que você controle o acesso a um banco de Dados, escrever dados, executar consultas, e executar quaisquer outras tarefas relacionadas com a gestão de banco de dados. Embora os sistemas de gestão de bases de dados sejam muitas vezes referidos como “bases de dados”, os dois termos não são permutáveis. Um banco de dados pode ser qualquer coleção de dados, não apenas um armazenado em um computador, enquanto um DBMS é o software que permite que você interaja com um banco de dados. todos os sistemas de gerenciamento de banco de dados têm um modelo subjacente que estrutura como os dados são armazenados e acessados. Um sistema de gerenciamento de banco de dados relacional é um DBMS que emprega o modelo de dados relacionais. Neste modelo, os dados são organizados em quadros, que no contexto do RDBMSs são mais formalmente designados como relações. Uma relação é um conjunto de tuplas ou linhas em uma tabela, onde cada tupla de partilha de um conjunto de atributos ou colunas:
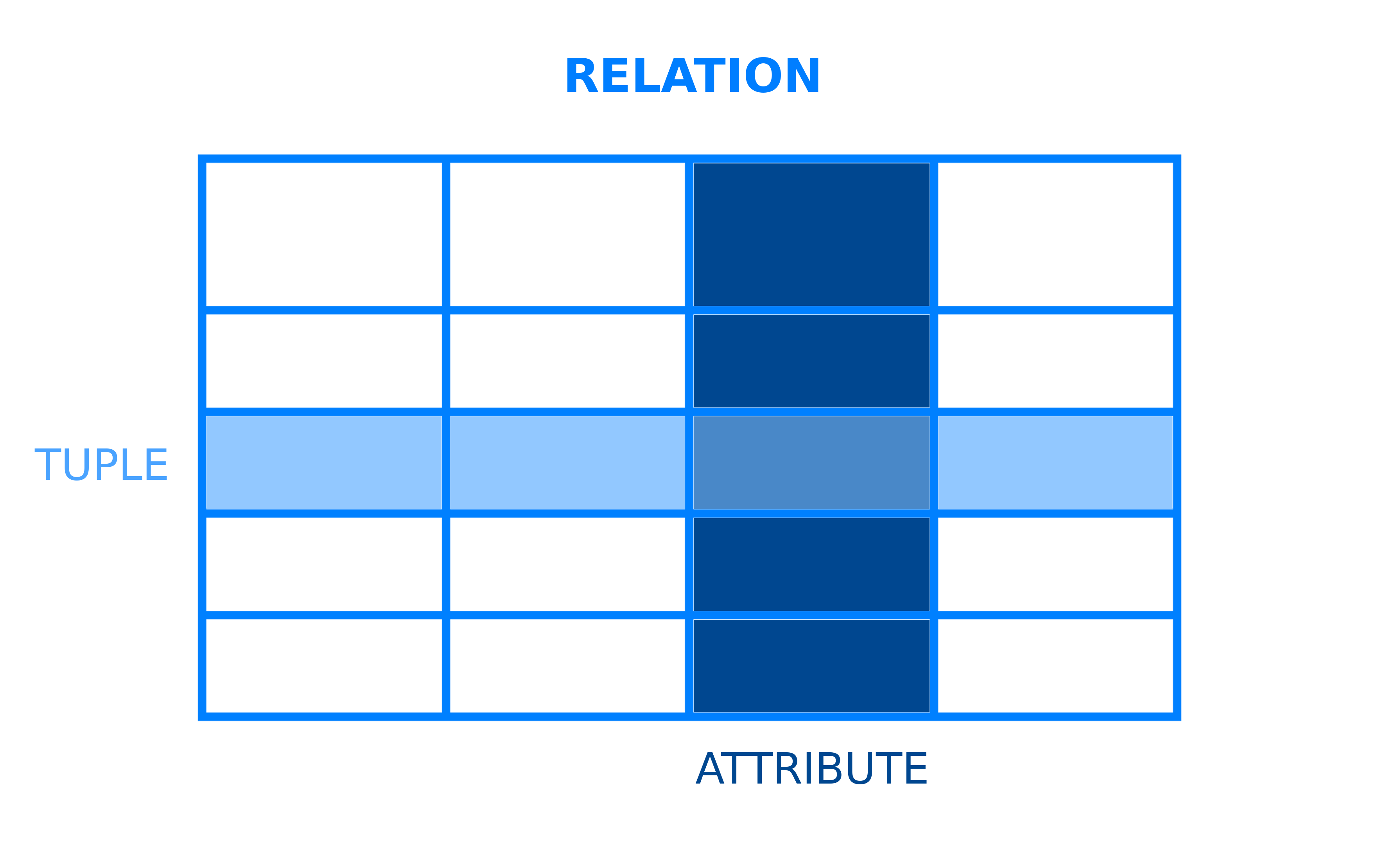
a Maioria dos bancos de dados relacionais use linguagem de consulta estruturada (SQL) para gerenciar e consulta de dados. No entanto, muitos RDBMSs usam seu próprio dialeto particular de SQL, que pode ter certas limitações ou extensões. Estas extensões geralmente incluem recursos extras que permitem aos usuários realizar operações mais complexas do que poderiam com SQL padrão.Nota: O termo “SQL padrão” Surge várias vezes ao longo deste guia. As normas SQL são mantidas conjuntamente pelo American National Standards Institute (ANSI), pela Organização Internacional de normalização (ISO) e pela Comissão Eletrotécnica Internacional (IEC). Sempre que este artigo menciona “padrão SQL” ou “padrão SQL”, refere-se à versão atual do padrão SQL Publicado por esses organismos.
deve-se notar que o padrão SQL completo é grande e complexo: SQL núcleo completo:2011 conformidade requer 179 características. Por causa disso, a maioria dos RDBMSs não suportam todo o padrão, embora alguns se aproximem da plena conformidade do que outros.
a cada coluna é atribuído um tipo de dados que dita que tipo de entradas são permitidas nessa coluna. Diferentes RDBMSs implementam diferentes tipos de dados, que nem sempre são diretamente intercambiáveis. Alguns tipos de dados comuns incluem datas, strings, inteiros e booleanos.
tipos de dados numéricos podem ser assinados, o que significa que podem representar tanto números positivos como negativos, ou sem sinal, o que significa que só podem representar números positivos. Por exemplo, o tipo de dados de MySQL tinyint pode conter 8 bits de dados, o que equivale a 256 valores possíveis. O intervalo assinado deste tipo de dados é de -128 a 127, enquanto o intervalo não assinado é de 0 a 255.
às vezes, um administrador de banco de dados irá impor uma restrição em uma tabela para limitar quais valores podem ser inseridos nela. Uma restrição normalmente se aplica a uma coluna particular, mas algumas restrições também podem se aplicar a uma tabela inteira. Aqui estão algumas restrições que são comumente usadas em SQL:
-
UNIQUE: A aplicação desta restrição a uma coluna garante que não há duas entradas nessa coluna idênticas. -
NOT NULL: Esta restrição garante que a coluna não tem qualquerNULLentradas. -
PRIMARY KEY: Uma combinação deUNIQUEeNOT NULLPRIMARY KEYrestrição garante que nenhuma entrada na colunaNULLe que cada entrada é diferente. -
FOREIGN KEY: AFOREIGN KEYé uma coluna de uma tabela que se refere aoPRIMARY KEYde outra tabela. Esta restrição é usada para ligar duas tabelas juntas: entradas para a colunaFOREIGN KEYjá deve existir na coluna parentPRIMARY KEYpara que o processo de escrita tenha sucesso. -
CHECK: esta restrição limita a gama de valores que podem ser introduzidos numa coluna. Por exemplo, se sua aplicação se destina apenas a residentes do Alasca, você poderia adicionar uma restriçãoCHECKem uma coluna de código ZIP Para apenas permitir entradas entre 99501 e 99950.
Se quiser saber mais sobre sistemas de gestão de bases de dados, consulte o nosso artigo sobre a compreensão de bases de dados SQL e NoSQL e diferentes modelos de bases de dados.agora que já cobrimos sistemas de gerenciamento de banco de dados relacionais em geral, vamos passar para a primeira das três bases de dados relacionais de código aberto que este artigo cobrirá: SQLite.
SQLite
SQLite é um RDBMS auto-contido, baseado em arquivos, e totalmente de código aberto conhecido por sua portabilidade, confiabilidade e forte desempenho, mesmo em ambientes de baixa memória. Suas transações são ACID-compliant, mesmo nos casos em que o sistema cai ou sofre uma falha de energia.
o site do projecto SQLite descreve-o como uma base de dados “sem servidor”. A maioria dos motores de banco de dados relacionais são implementados como um processo de servidor no qual os programas se comunicam com o servidor host através de uma comunicação interprocess que relés requisita. Com o SQLite, no entanto, qualquer processo que aceda ao banco de dados lê e escreve diretamente para o arquivo de disco de banco de dados. Isto simplifica o processo de configuração do SQLite, uma vez que elimina qualquer necessidade de configurar um processo servidor. Da mesma forma, não há configuração necessária para programas que irão usar o banco de dados SQLite: tudo o que eles precisam é de acesso ao disco.
SQLite é um software livre e de código aberto, e nenhuma licença especial é necessária para usá-lo. No entanto, o projeto oferece várias extensões — cada uma por uma taxa única-que ajudam com a compressão e criptografia. Além disso, o projeto oferece vários pacotes de suporte comercial, cada um por uma taxa anual.
o SQLite é o Suporte a Tipos de Dados
SQLite permite uma variedade de tipos de dados, organizados nas seguintes classes de armazenamento:
| Tipo de Dados | Explicação |
|---|---|
null |
Inclui qualquer NULL valores. |
integer |
inteiros Assinados, armazenado em 1, 2, 3, 4, 6, ou 8 bytes, dependendo da magnitude do valor. |
real |
números reais, ou valores de vírgula flutuante, armazenados como números de vírgula flutuante de 8 bytes. |
text |
text strings armazenadas usando a codificação da base de dados, que pode ser UTF-8, UTF-16BE ou UTF-16LE. |
blob |
qualquer bolha de dados, com cada bolha armazenada exatamente como era de entrada. |
No contexto do SQLite, os termos “classe de armazenamento” e “tipo de dados” são considerados intercambiáveis. Se você gostaria de saber mais sobre os tipos de dados do SQLite e afinidade do tipo SQLite, confira a documentação oficial do SQLite sobre o assunto.
vantagens do SQLite
- pequena pegada: como o seu nome indica, a biblioteca SQLite é muito leve. Embora o espaço que usa varie dependendo do sistema onde está instalado, pode ocupar menos de 600KiB de espaço. Além disso, é totalmente independente, o que significa que não existem dependências externas que você tem que instalar no seu sistema para o SQLite funcionar.
- User-friendly: SQLite is sometimes described as a” zero-configuration ” database that’s ready for use out of the box. O SQLite não funciona como um processo de servidor, o que significa que ele nunca precisa ser parado, iniciado ou reiniciado e não vem com nenhum arquivo de configuração que precisa ser gerenciado. Estas funcionalidades ajudam a simplificar o caminho desde a instalação do SQLite até a sua integração com uma aplicação.portátil: Ao contrário de outros sistemas de gerenciamento de banco de dados, que normalmente armazenam dados como um grande lote de arquivos separados, um banco de dados SQLite inteiro é armazenado em um único arquivo. Este arquivo pode ser localizado em qualquer lugar em uma hierarquia de diretório, e pode ser compartilhado através de mídia removível ou protocolo de transferência de arquivos.
desvantagens do SQLite
- concorrência limitada: embora vários processos possam acessar e consultar uma base de dados SQLite ao mesmo tempo, apenas um processo pode fazer alterações à base de dados a qualquer momento. Isto significa que o SQLite suporta maior concorrência do que a maioria dos outros sistemas de gerenciamento de banco de dados embutidos, mas não tanto como o cliente/servidor RDBMSs como MySQL ou PostgreSQL.
- No user management: os sistemas de banco de Dados Muitas vezes vêm com suporte para os usuários, ou conexões gerenciadas com privilégios de acesso predefinidos para a base de dados e tabelas. Como o SQLite lê e escreve diretamente para um arquivo de disco comum, as únicas permissões de acesso aplicáveis são as permissões de acesso típicas do sistema operacional subjacente. Isso faz do SQLite uma má escolha para aplicações que requerem vários usuários com permissões de acesso especiais.
- segurança: um motor de banco de dados que usa um servidor pode, em alguns casos, fornecer melhor proteção contra bugs na aplicação cliente do que um banco de dados sem servidor como o SQLite. Por exemplo, os ponteiros perdidos em um cliente não podem corromper a memória no servidor. Além disso, como um servidor é um único processo persistente, um banco de dados cliente-servidor cancontrol acesso de dados com mais precisão do que um banco de dados serverless, permitindo um bloqueio mais fino e melhor concorrência.
quando usar o SQLite
- aplicações incorporadas: o SQLite é uma grande escolha de base de dados para aplicações que precisam de portabilidade e não requerem expansão futura. Exemplos incluem aplicações locais de um único utilizador e aplicações ou jogos móveis.
- substituto do acesso ao disco: nos casos em que uma aplicação precisa de ler e escrever ficheiros directamente no disco, pode ser benéfico usar o SQLite para a funcionalidade adicional e simplicidade que vem com o uso do SQL.ensaio: Para muitas aplicações pode ser exagero para testar sua funcionalidade com um DBMS que usa um processo de servidor adicional. O SQLite tem um modo em memória que pode ser usado para executar testes rapidamente sem a sobrecarga das operações reais do banco de dados, tornando-o uma escolha ideal para testes.
quando não usar o SQLite
- trabalhando com muitos dados: o SQLite pode tecnicamente suportar uma base de dados até 140 TB em tamanho, desde que a unidade de disco e o sistema de arquivos também suportem os requisitos de tamanho da base de dados. No entanto, o site SQLite recomenda que qualquer banco de dados próximo a 1TB seja alojado em um banco de dados cliente-servidor centralizado, como um banco de dados SQLite desse tamanho ou maior seria difícil de gerenciar.
- volumes de escrita elevados: SQLite permite que apenas uma operação de escrita ocorra em qualquer momento, o que limita significativamente o seu rendimento. Se a sua aplicação requer muitas operações de escrita ou vários escritores concorrentes, o SQLite pode não ser adequado para as suas necessidades.é necessário o acesso à rede: Como o SQLite é um banco de dados sem servidor, ele não fornece acesso direto à rede de seus dados. Este acesso é construído na aplicação, de modo que se os dados em SQLite está localizado em uma máquina separada da aplicação que irá exigir uma ligação motor-a-disco de alta largura de banda através da rede. Esta é uma solução cara e ineficiente, e em tais casos um cliente-servidor DBMS pode ser uma escolha melhor.
MySQL
de acordo com o ranking de DB-Engines, MySQL tem sido o mais popular RDBMS de código aberto desde que o site começou a rastrear a popularidade do banco de dados em 2012. É um produto rico em recursos que alimenta muitos dos maiores sites e aplicações do mundo, incluindo Twitter, Facebook, Netflix e Spotify. Começar com MySQL é relativamente simples, graças em grande parte à sua documentação exaustiva e grande comunidade de desenvolvedores, bem como a abundância de recursos relacionados ao MySQL online.
MySQL foi projetado para velocidade e confiabilidade, à custa da adesão total ao SQL padrão. Os desenvolvedores do MySQL trabalham continuamente para uma adesão mais próxima ao SQL padrão, mas ele ainda fica atrás de outras implementações do SQL. Ele vem, no entanto, com vários modos SQL e extensões que o aproximam da conformidade. Ao contrário das aplicações que usam o SQLite, as aplicações que usam um banco de dados MySQL acessam-no através de um processo de servidor separado. Como o processo servidor está entre o banco de dados e outras aplicações, ele permite um maior controle sobre quem tem acesso ao banco de dados.
MySQL inspirou uma riqueza de Aplicações, Ferramentas e bibliotecas integradas de terceiros que estendem a sua funcionalidade e ajudam a torná-la mais fácil de trabalhar. Algumas das ferramentas de terceiros mais utilizadas são phpMyAdmin, DBeaver e HeidiSQL.
os tipos de dados suportados por MySQL
os tipos de dados de MySQL podem ser organizados em três grandes categorias: tipos numéricos, tipos de data e hora, e tipos de cadeia de caracteres.
tipos Numéricos:
| Tipo de Dados | Explicação |
|---|---|
tinyint |
muito pequeno inteiro. O intervalo assinado para este tipo de dados numéricos é -128 a 127, enquanto o intervalo sem sinal é 0 a 255. |
smallint |
um pequeno número inteiro. O intervalo assinado para este tipo numérico é-32768 a 32767, enquanto o intervalo não assinado é de 0 a 65535. |
mediumint |
um número inteiro de tamanho médio. O intervalo assinado para este tipo de dados numéricos é de -8388608 a 8388607, enquanto o intervalo não assinado é de 0 a 16777215. |
int ou integer |
normal-tamanho inteiro. O intervalo assinado para este tipo de dados numéricos é -2147483648 a 2147483647, enquanto o intervalo não assinado é de 0 a 4294967295. |
bigint |
Um grande número inteiro. O intervalo assinado para este tipo de dados numéricos é -9223372036854775808 a 9223372036854775807, enquanto o intervalo não assinado é de 0 a 18446744073709551615. |
float |
um pequeno número de vírgula flutuante (de precisão única). |
doubledouble precision, ou real |
Uma de tamanho normal (dupla precisão) número de ponto flutuante. |
decdecimalfixed, ou numeric |
Um pacote de número de ponto fixo. O comprimento de exibição de entradas para este tipo de dados é definido quando a coluna é criada, e cada entrada adere a esse comprimento. |
bool ou boolean |
Um Booleano é um tipo de dados que tem apenas dois valores possíveis, geralmente de true ou false. |
bit |
um tipo de valor de bits para o qual pode especificar o número de bits por valor, de 1 a 64. |
tipos de Data e hora:
| Data Type | Explanation |
|---|---|
date |
A date, represented as YYYY-MM-DD. |
datetime |
A timestamp showing the date and time, displayed as YYYY-MM-DD HH:MM:SS. |
timestamp |
A timestamp indicating the amount of time since the Unix epoch (00:00:00 on January 1, 1970). |
time |
A time of day, displayed as HH:MM:SS. |
year |
A year expressed in either a 2 or 4 digit format, with 4 digits being the default. |
String types:
| Data Type | Explanation |
|---|---|
char |
A fixed-length string; as entradas deste tipo são acolchoadas à direita com espaços para cumprir o comprimento especificado quando armazenado. |
varchar |
uma cadeia de comprimento variável. |
binary |
semelhante aochar tipo, mas uma cadeia binária de bytes de um comprimento especificado em vez de uma cadeia de caracteres não culinária. |
varbinary |
Semelhante ao varchar tipo, mas de um byte binário de seqüência de caracteres de comprimento variável, em vez de um não binários cadeia de caracteres. |
blob |
A binary string with a maximum length of 65535 (2^16 – 1) bytes of data. |
tinyblob |
A blob column with a maximum length of 255 (2^8 – 1) bytes of data. |
mediumblob |
A blob column with a maximum length of 16777215 (2^24 – 1) bytes of data. |
longblob |
A blob column with a maximum length of 4294967295 (2^32 – 1) bytes of data. |
text |
A string with a maximum length of 65535 (2^16 – 1) characters. |
tinytext |
A text column with a maximum length of 255 (2^8 – 1) characters. |
mediumtext |
A text column with a maximum length of 16777215 (2^24 – 1) characters. |
longtext |
A text column with a maximum length of 4294967295 (2^32 – 1) characters. |
enum |
Uma enumeração, que é um objeto de cadeia de caracteres que usa um único valor a partir de uma lista de valores que são declarados quando a tabela é criada. |
set |
Semelhante a uma enumeração, um objeto string que pode ter zero ou mais valores, cada um deve ser escolhido a partir de uma lista de valores permitidos que são especificados quando a tabela é criada. |
Vantagens do MySQL
- Popularidade e facilidade de uso: Como um dos sistemas de banco de dados mais populares do mundo, não há falta de administradores de banco de dados que tenham experiência trabalhando com MySQL. Da mesma forma, há uma abundância de documentação impressa e on-line sobre como instalar e gerenciar um banco de dados MySQL, bem como uma série de ferramentas de terceiros — como phpMyAdmin — que visam simplificar o processo de começar com o banco de dados.segurança: MySQL vem instalado com um script que ajuda você a melhorar a segurança de seu banco de dados, definindo o nível de segurança da senha da instalação, definindo uma senha para o usuário root, removendo contas anônimas e removendo bancos de dados de teste que são, por padrão, acessíveis a todos os usuários. Além disso, ao contrário do SQLite, o MySQL suporta a gestão de utilizadores e permite-lhe conceder privilégios de acesso numa base utilizador-a-Utilizador.
- velocidade: ao escolher não implementar certas características do SQL, os desenvolvedores do MySQL foram capazes de priorizar a velocidade. Enquanto testes de benchmark mais recentes mostram que outros RDBMSs como PostgreSQL podem corresponder ou pelo menos chegar perto de MySQL em termos de velocidade, MySQL ainda mantém uma reputação como uma solução de banco de dados extremamente rápida.replicação: MySQL suporta uma série de diferentes tipos de replicação, que é a prática de compartilhar informações entre dois ou mais hosts para ajudar a melhorar a confiabilidade, disponibilidade e tolerância a falhas. Isto é útil para configurar uma solução de backup de banco de dados ou dimensionar horizontalmente a base de dados.
Desvantagens do MySQL
- limitações Conhecidas: Porque MySQL foi projetado para velocidade e facilidade de uso, em vez de completa conformidade SQL, ele vem com certas limitações funcionais. Por exemplo, ele não tem suporte para cláusulas
FULL JOIN. - Licenciamento e características proprietárias: MySQL é software dual-licensed, com uma edição comunitária livre e de código aberto licenciado sob GPLv2 e várias edições comerciais pagas lançadas sob licenças proprietárias. Por causa disso, alguns recursos e plugins estão disponíveis apenas para as edições proprietárias. desenvolvimento lento: Desde o projeto MySQL foi adquirida pela Sun Microsystems, em 2008, e mais tarde pela Oracle Corporation, em 2009, houve reclamações de usuários que o processo de desenvolvimento para o SGBD abrandou significativamente, assim como a comunidade não tem o arbítrio para reagir rapidamente aos problemas e implementar mudanças.
quando usar o MySQL
- operações distribuídas: o Suporte de replicação do MySQL faz com que seja uma grande escolha para Configurações distribuídas de bases de dados como arquiteturas primária-secundária ou primária-primária. sítios web e aplicações web: O MySQL potencia muitos sites e aplicações através da internet. Isto é, em grande parte, graças ao quão fácil é instalar e configurar um banco de dados MySQL, bem como a sua velocidade global e escalabilidade a longo prazo.o Suporte de replicação do MySQL pode ajudar a facilitar a escala horizontal. Além disso, é um processo relativamente simples para atualizar para um produto MySQL comercial, como o MySQL Cluster, que suporta sharding automático, outro processo de escala horizontal.
quando não se deve utilizar MySQL
- SQL, é necessária a conformidade: Uma vez que o MySQL não tenta implementar o padrão SQL completo, esta ferramenta não é completamente compatível com o SQL. Se a conformidade SQL completa ou quase completa é uma obrigação para o seu caso de uso, você pode querer usar um DBMS mais totalmente compatível.
- concurrencia e grandes volumes de dados: embora MySQL geralmente tenha um bom desempenho com operações pesadas de leitura, as leituras simultâneas podem ser problemáticas. Se a sua aplicação vai ter muitos usuários escrevendo dados para ele de uma vez, outro RDBMS como PostgreSQL pode ser uma melhor escolha de banco de dados.
PostgreSQL
PostgreSQL, também conhecido como Postgres, bills itself as “the most advanced open-source relational database in the world.”Foi criado com o objetivo de ser altamente extensível e compatível com os padrões. PostgreSQL é um banco de dados objeto-relacional, o que significa que, embora seja principalmente um banco de dados relacional, ele também inclui recursos — como herança de tabela e sobrecarga de funções — que são mais frequentemente associados com bancos de dados de objetos.
Postgres é capaz de lidar eficientemente com múltiplas tarefas ao mesmo tempo, uma característica conhecida como concorrência. Ela consegue isso sem fechaduras de leitura graças à sua implementação do controle de concorrência Multiversion (MVCC), que garante a atomicidade, consistência, isolamento e durabilidade de suas transações, também conhecido como ACID compliance.
PostgreSQL não é tão amplamente utilizado como MySQL, mas ainda há uma série de ferramentas de terceiros e bibliotecas projetadas para simplificar o trabalho com PostgreSQL, incluindo pgAdmin e Postbird.
os tipos de dados suportados por PostgreSQL
PostgreSQL suportam tipos de dados numéricos, string, data e hora como MySQL. Além disso, ele suporta tipos de dados para formas geométricas, endereços de rede, strings de bits, pesquisas de texto, e entradas JSON, bem como vários tipos de dados idiossincráticos.
tipos Numéricos:
| Tipo de Dados | Explicação |
|---|---|
bigint |
Uma assinado 8 byte inteiro. |
bigserial |
An autoincrementing 8 byte integer. |
double precision |
An 8 byte double precision floating-point number. |
integer |
A signed 4 byte integer. |
numeric or decimal |
An number of selectable precision, recommended for use in cases where exactness is crucial, such as monetary amounts. |
real |
A 4 byte single precision floating-point number. |
smallint |
A signed 2 byte integer. |
smallserial |
An autoincrementing 2 byte integer. |
serial |
An autoincrementing 4 byte integer. |
Character types:
| Data Type | Explanation |
|---|---|
character |
A character string with a specified fixed length. |
character varying or varchar |
A character string with a variable but limited length. |
text |
A character string of a variable, unlimited length. |
Date and time types:
| Data Type | Explanation |
|---|---|
date |
A calendar date consisting of the day, month, and year. |
interval |
A time span. |
time or time without time zone |
A time of day, not including the time zone. |
time with time zone |
A time of day, including the time zone. |
timestamp or timestamp without time zone |
A date and time, not including the time zone. |
timestamp with time zone |
A date and time, including the time zone. |
Geometric types:
| Data Type | Explanation |
|---|---|
box |
A rectangular box on a plane. |
circle |
A circle on a plane. |
line |
An infinite line on a plane. |
lseg |
A line segment on a plane. |
path |
A geometric path on a plane. |
point |
A geometric point on a plane. |
polygon |
A closed geometric path on a plane. |
Network address types:
| Data Type | Explanation |
|---|---|
cidr |
An IPv4 or IPv6 network address. |
inet |
An IPv4 or IPv6 host address. |
macaddr |
A Media Access Control (MAC) address. |
Bit string types:
| Data Type | Explanation |
|---|---|
bit |
A fixed-length bit string. |
bit varying |
A variable-length bit string. |
Text search types:
| Data Type | Explanation |
|---|---|
tsquery |
A text search query. |
tsvector |
A text search document. |
JSON types:
| Data Type | Explanation |
|---|---|
json |
Textual JSON data. |
jsonb |
Decomposed binary JSON data. |
Other data types:
| Data Type | Explanation |
|---|---|
boolean |
A logical Boolean, representing either true or false. |
bytea |
Short for “byte array”, this type is used for binary data. |
money |
An amount of currency. |
pg_lsn |
A PostgreSQL Log Sequence Number. |
txid_snapshot |
A user-level transaction ID snapshot. |
uuid |
A universally unique identifier. |
xml |
XML data. |
Advantages of PostgreSQL
- SQL compliance: More so than SQLite or MySQL, PostgreSQL aims to closely adhere to SQL standards. According to the official PostgreSQL documentation, PostgreSQL supports 160 out of the 179 features required for full core SQL:Conformidade 2011, além de uma longa lista de características opcionais.
- Open-source and community-driven: a fully open-source project, Postgresql’s source code is developed by a large and devoted community. Da mesma forma, a comunidade Postgres mantém e contribui para inúmeros recursos online que descrevem como trabalhar com o SGBD, incluindo a documentação oficial, o wiki PostgreSQL e vários fóruns online.Extensible: Users can extend PostgreSQL programmatically and on the fly through its catalog-driven operation and its use of dynamic loading. Pode-se designar um arquivo de código objeto, como uma biblioteca compartilhada, e PostgreSQL irá carregá-lo conforme necessário.
desvantagens do PostgreSQL
- desempenho da memória: para cada nova ligação ao cliente, o PostgreSQL procura um novo processo. Cada novo processo é alocado cerca de 10MB de memória, que pode adicionar-se rapidamente para Bancos de dados com muitas conexões. Assim, para operações simples de leitura pesada, PostgreSQL é tipicamente menos performante do que outros RDBMSs, como MySQL.Popularidade: Embora mais usado nos últimos anos, o PostgreSQL historicamente ficou atrás do MySQL em termos de popularidade. Uma consequência disso é que ainda há menos ferramentas de terceiros que podem ajudar a gerenciar um banco de dados PostgreSQL. Da mesma forma, não há tantos administradores de banco de dados com experiência gerindo um banco de dados Postgres em comparação com aqueles com experiência MySQL.
quando utilizar PostgreSQL
- a integridade dos dados é importante: O PostgreSQL tem sido totalmente compatível com a acidez desde 2001 e implementa o controle de moeda Multi-Version para garantir que os dados permanecem consistentes, tornando-se uma escolha forte de RDBMS quando a integridade dos dados é crítica.
- integração com outras ferramentas: PostgreSQL é compatível com uma grande variedade de linguagens de programação e plataformas. Isso significa que se você precisar migrar seu banco de dados para outro sistema operacional ou integrá-lo com uma ferramenta específica, provavelmente será mais fácil com um banco de dados PostgreSQL do que com outro DBMS.operações complexas: Postgres suporta planos de consulta que podem alavancar vários CPUs, a fim de responder a consultas com maior velocidade. Isto, juntamente com o seu forte apoio para múltiplos escritores concorrentes, torna-o uma grande escolha para operações complexas como armazenamento de dados e processamento de transações on-line.
quando não usar PostgreSQL
- velocidade é imperativo: à custa da velocidade, PostgreSQL foi projetado com extensibilidade e compatibilidade em mente. Se seu projeto requer as operações de leitura mais rápidas possíveis, PostgreSQL pode não ser a melhor escolha de DBMS.configurações simples: Devido ao seu grande conjunto de recursos e forte adesão ao SQL padrão, Postgres pode ser exagero para configurações de banco de dados simples. Para operações de leitura pesada onde a velocidade é necessária, MySQL é tipicamente uma escolha mais prática.replicação complexa: embora o PostgreSQL forneça um forte suporte para a replicação, ainda é uma característica relativamente nova e algumas configurações — como uma arquitetura primária-são apenas possíveis com extensões. A replicação é uma característica mais madura no MySQL e muitos usuários vêem a replicação do MySQL ser mais fácil de implementar, particularmente para aqueles que não possuem a experiência necessária de administração de banco de dados e sistema.
Conclusion
Today, SQLite, MySQL, and PostgreSQL are the three most popular open-source relational database management systems in the world. Cada um tem suas próprias características e limitações únicas, e se destaca em cenários particulares. Há algumas variáveis em jogo quando se decide sobre um RDBMS, e a escolha raramente é tão simples quanto escolher o mais rápido ou o que tem mais recursos. Da próxima vez que precisar de uma solução de banco de dados relacional, não se esqueça de pesquisar estas e outras ferramentas em profundidade para encontrar a que melhor se adapta às suas necessidades.
Se você gostaria de saber mais sobre SQL e como usá-lo para gerenciar um banco de dados relacional, nós encorajamos você a se referir a nossa forma de gerenciar uma folha de batota do banco de Dados SQL. Por outro lado, se você gostaria de aprender sobre bases de dados não-relacionais (ou NoSQL), confira nossa comparação de Sistemas de gerenciamento de banco de dados NoSQL.