Einführung
Das relationale Datenmodell, das Daten in Tabellen mit Zeilen und Spalten organisiert, überwiegt in Datenbankverwaltungstools. Heute gibt es andere Datenmodelle, einschließlich NoSQL und NewSQL, aber relationale Datenbankmanagementsysteme (RDBMS) dominieren nach wie vor für die Speicherung und Verwaltung von Daten weltweit.
Dieser Artikel vergleicht und kontrastiert drei der am weitesten verbreiteten Open-Source-RDBMS: SQLite, MySQL und PostgreSQL. Insbesondere werden die Datentypen untersucht, die jedes RDBMS verwendet, ihre Vor- und Nachteile und Situationen, in denen sie am besten optimiert werden.
Ein wenig über Datenbankmanagementsysteme
Datenbanken sind logisch modellierte Cluster von Informationen oder Daten. Ein Datenbankmanagementsystem (DBMS) hingegen ist ein Computerprogramm, das mit einer Datenbank interagiert. Mit einem DBMS können Sie den Zugriff auf eine Datenbank steuern, Daten schreiben, Abfragen ausführen und andere Aufgaben im Zusammenhang mit der Datenbankverwaltung ausführen. Obwohl Datenbankmanagementsysteme oft als „Datenbanken“ bezeichnet werden, sind die beiden Begriffe nicht austauschbar. Eine Datenbank kann eine beliebige Sammlung von Daten sein, nicht nur eine, die auf einem Computer gespeichert ist, während ein DBMS die Software ist, mit der Sie mit einer Datenbank interagieren können.
Allen Datenbankmanagementsystemen liegt ein Modell zugrunde, das strukturiert, wie Daten gespeichert und darauf zugegriffen wird. Ein relationales Datenbankmanagementsystem ist ein DBMS, das das relationale Datenmodell verwendet. In diesem Modell sind Daten in Tabellen organisiert, die im Kontext von RDBMS formeller als Beziehungen bezeichnet werden. Eine Beziehung ist ein Satz von Tupeln oder Zeilen in einer Tabelle, wobei jedes Tupel einen Satz von Attributen oder Spalten gemeinsam hat:
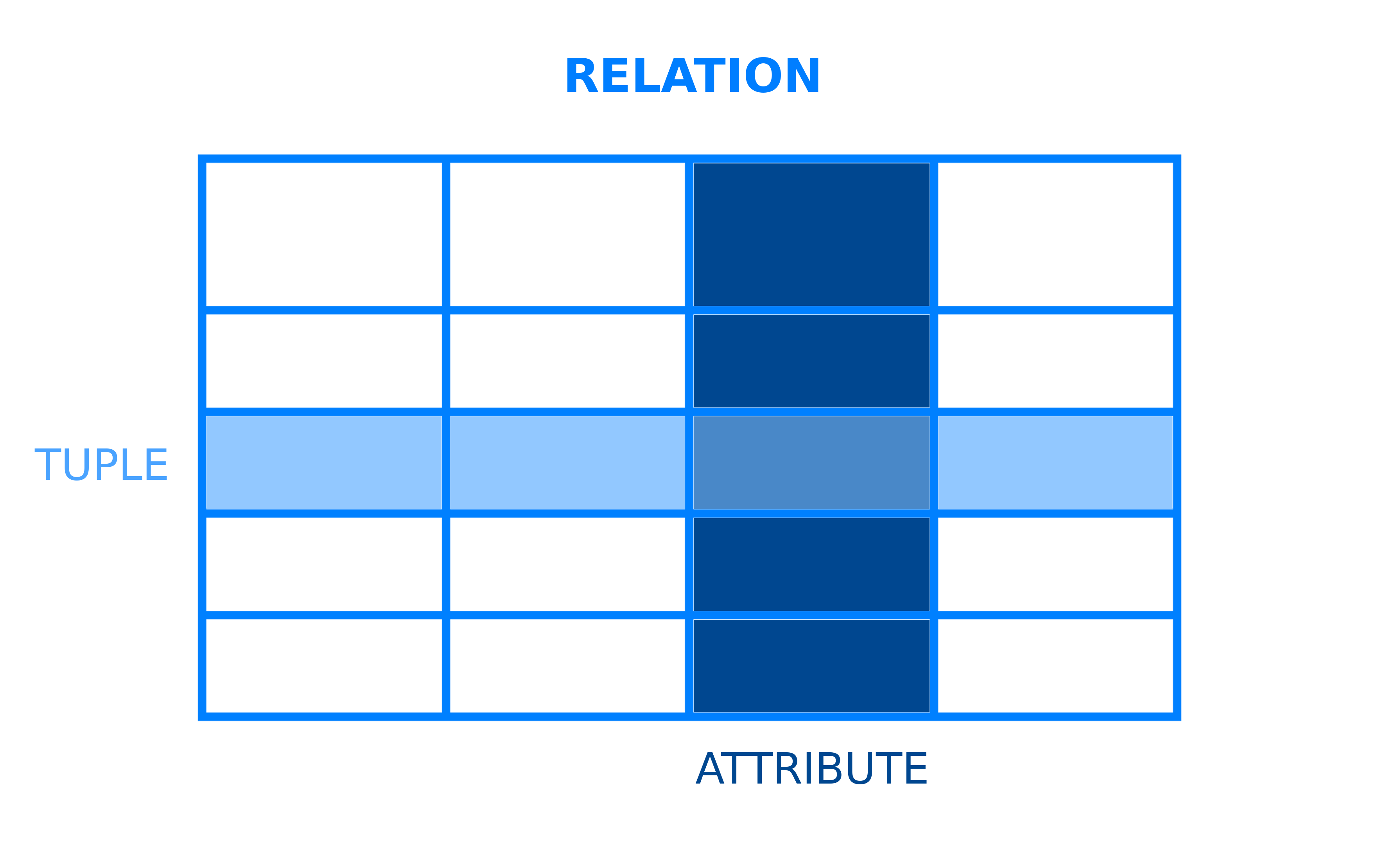
Die meisten relationalen Datenbanken verwenden SQL (Structured Query Language), um Daten zu verwalten und abzufragen. Viele RDBMS verwenden jedoch ihren eigenen SQL-Dialekt, der bestimmte Einschränkungen oder Erweiterungen aufweisen kann. Diese Erweiterungen enthalten in der Regel zusätzliche Funktionen, mit denen Benutzer komplexere Vorgänge ausführen können, als dies bei Standard-SQL der Fall wäre.
Hinweis: Der Begriff „Standard SQL“ kommt in diesem Handbuch mehrmals vor. SQL-Standards werden gemeinsam vom American National Standards Institute (ANSI), der International Organization for Standardization (ISO) und der International Electrotechnical Commission (IEC) gepflegt. Wenn in diesem Artikel „Standard-SQL“ oder „der SQL-Standard“ erwähnt wird, bezieht er sich auf die aktuelle Version des SQL-Standards, die von diesen Gremien veröffentlicht wurde.
Es ist zu beachten, dass der vollständige SQL-Standard groß und komplex ist: Die vollständige Core SQL:2011-Konformität erfordert 179 Funktionen. Aus diesem Grund unterstützen die meisten RDBMS nicht den gesamten Standard, obwohl einige der vollständigen Einhaltung näher kommen als andere.
Jeder Spalte wird ein Datentyp zugewiesen, der bestimmt, welche Art von Einträgen in dieser Spalte zulässig sind. Verschiedene RDBMS implementieren unterschiedliche Datentypen, die nicht immer direkt austauschbar sind. Einige gängige Datentypen sind Datumsangaben, Zeichenfolgen, Ganzzahlen und Boolesche Werte.
Numerische Datentypen können entweder signiert sein, was bedeutet, dass sie sowohl positive als auch negative Zahlen darstellen können, oder unsigned, was bedeutet, dass sie nur positive Zahlen darstellen können. Der Datentyp tinyint von MySQL kann beispielsweise 8 Datenbits enthalten, was 256 möglichen Werten entspricht. Der vorzeichenbehaftete Bereich dieses Datentyps liegt zwischen -128 und 127, während der vorzeichenlose Bereich zwischen 0 und 255 liegt.
Manchmal wird ein Datenbankadministrator einer Tabelle eine Einschränkung auferlegen, um zu begrenzen, welche Werte in sie eingegeben werden können. Eine Einschränkung gilt normalerweise für eine bestimmte Spalte, aber einige Einschränkungen können auch für eine ganze Tabelle gelten. Hier sind einige Einschränkungen, die häufig in SQL verwendet werden:
-
UNIQUE: Durch Anwenden dieser Einschränkung auf eine Spalte wird sichergestellt, dass keine zwei Einträge in dieser Spalte identisch sind. -
NOT NULL: Diese Einschränkung stellt sicher, dass eine Spalte keineNULLEinträge enthält. -
PRIMARY KEY: Eine Kombination ausUNIQUEundNOT NULL, diePRIMARY KEYEinschränkung stellt sicher, dass kein Eintrag in der SpalteNULLund dass jeder Eintrag anders ist. -
FOREIGN KEY: EineFOREIGN KEYist eine Spalte in einer Tabelle, die auf diePRIMARY KEYeiner anderen Tabelle verweist. Diese Einschränkung wird verwendet, um zwei Tabellen miteinander zu verknüpfen: Einträge in der SpalteFOREIGN KEYmüssen bereits in der übergeordneten SpaltePRIMARY KEYvorhanden sein, damit der Schreibvorgang erfolgreich ist. -
CHECK: Diese Einschränkung begrenzt den Wertebereich, der in eine Spalte eingegeben werden kann. Wenn Ihre Anwendung beispielsweise nur für Einwohner von Alaska bestimmt ist, können Sie eineCHECKEinschränkung für eine Postleitzahlenspalte hinzufügen, um nur Einträge zwischen 99501 und 99950 zuzulassen.
Wenn Sie mehr über Datenbankmanagementsysteme erfahren möchten, lesen Sie unseren Artikel zum Verständnis von SQL- und NoSQL-Datenbanken und verschiedenen Datenbankmodellen.
Nun, da wir relationale Datenbankmanagementsysteme im Allgemeinen behandelt haben, wollen wir uns der ersten der drei relationalen Open-Source-Datenbanken zuwenden, die in diesem Artikel behandelt werden: SQLite.
SQLite
SQLite ist ein in sich geschlossenes, dateibasiertes und vollständig Open-Source-RDBMS, das für seine Portabilität, Zuverlässigkeit und starke Leistung auch in Umgebungen mit wenig Speicher bekannt ist. Seine Transaktionen sind ACID-konform, auch in Fällen, in denen das System abstürzt oder einen Stromausfall erleidet.
Die Website des SQLite-Projekts beschreibt sie als „serverlose“ Datenbank. Die meisten relationalen Datenbankmodule sind als Serverprozess implementiert, bei dem Programme über eine Interprozesskommunikation, die Anforderungen weiterleitet, mit dem Hostserver kommunizieren. Mit SQLite liest jedoch jeder Prozess, der auf die Datenbank zugreift, direkt aus der Datenbankdatenträgerdatei und schreibt in diese. Dies vereinfacht den Setup-Prozess von SQLite, da kein Serverprozess konfiguriert werden muss. Ebenso ist keine Konfiguration für Programme erforderlich, die die SQLite-Datenbank verwenden: Sie benötigen lediglich Zugriff auf die Festplatte.
SQLite ist eine kostenlose Open-Source-Software, für deren Verwendung keine spezielle Lizenz erforderlich ist. Das Projekt bietet jedoch mehrere Erweiterungen – jeweils gegen eine einmalige Gebühr -, die bei der Komprimierung und Verschlüsselung helfen. Darüber hinaus bietet das Projekt verschiedene kommerzielle Support-Pakete, die jeweils für eine jährliche Gebühr.
Unterstützte Datentypen von SQLite
SQLite ermöglicht eine Vielzahl von Datentypen, die in die folgenden Speicherklassen unterteilt sind:
| Datentyp | Erklärung |
|---|---|
null |
Enthält alle NULL Werte. |
integer |
Ganzzahlen mit Vorzeichen, gespeichert in 1, 2, 3, 4, 6, oder 8 Bytes abhängig von der Größe des Wertes. |
real |
Reelle Zahlen oder Gleitkommawerte, die als 8-Byte-Gleitkommazahlen gespeichert werden. |
text |
Textzeichenfolgen, die mit der Datenbankcodierung gespeichert werden, die entweder UTF-8, UTF-16BE oder UTF-16LE sein kann. |
blob |
Beliebiger Datenblob, wobei jeder Blob genau so gespeichert wird, wie er eingegeben wurde. |
Im Kontext von SQLite werden die Begriffe „Speicherklasse“ und „Datentyp“ als austauschbar betrachtet. Wenn Sie mehr über die Datentypen und die Affinität von SQLite erfahren möchten, lesen Sie die offizielle Dokumentation von SQLite zu diesem Thema.
Vorteile von SQLite
- Geringer Platzbedarf: Wie der Name schon sagt, ist die SQLite-Bibliothek sehr leicht. Obwohl der verwendete Speicherplatz je nach System, auf dem er installiert ist, variiert, kann er weniger als 600 KB Speicherplatz beanspruchen. Darüber hinaus ist es vollständig in sich geschlossen, was bedeutet, dass es keine externen Abhängigkeiten gibt, die Sie auf Ihrem System installieren müssen, damit SQLite funktioniert.
- Benutzerfreundlich: SQLite wird manchmal als „Null-Konfigurations“ -Datenbank beschrieben, die sofort einsatzbereit ist. SQLite wird nicht als Serverprozess ausgeführt, was bedeutet, dass es niemals gestoppt, gestartet oder neu gestartet werden muss und keine Konfigurationsdateien enthält, die verwaltet werden müssen. Diese Funktionen tragen dazu bei, den Weg von der Installation von SQLite zur Integration in eine Anwendung zu vereinfachen.
- Tragbar: Im Gegensatz zu anderen Datenbankverwaltungssystemen, bei denen Daten normalerweise als großer Stapel separater Dateien gespeichert werden, wird eine gesamte SQLite-Datenbank in einer einzigen Datei gespeichert. Diese Datei kann sich an einer beliebigen Stelle in einer Verzeichnishierarchie befinden und über Wechselmedien oder das Dateiübertragungsprotokoll freigegeben werden.
Nachteile von SQLite
- Eingeschränkte Parallelität: Obwohl mehrere Prozesse gleichzeitig auf eine SQLite-Datenbank zugreifen und diese abfragen können, kann immer nur ein Prozess Änderungen an der Datenbank vornehmen. Dies bedeutet, dass SQLite eine größere Parallelität als die meisten anderen eingebetteten Datenbankverwaltungssysteme unterstützt, jedoch nicht so sehr wie Client / Server-RDBMS wie MySQL oder PostgreSQL.
- Keine Benutzerverwaltung: Datenbanksysteme bieten häufig Unterstützung für Benutzer oder verwaltete Verbindungen mit vordefinierten Zugriffsrechten auf die Datenbank und Tabellen. Da SQLite direkt in eine normale Festplattendatei liest und schreibt, sind die einzigen anwendbaren Zugriffsberechtigungen die typischen Zugriffsberechtigungen des zugrunde liegenden Betriebssystems. Dies macht SQLite zu einer schlechten Wahl für Anwendungen, die mehrere Benutzer mit speziellen Zugriffsberechtigungen erfordern.
- Sicherheit: Ein Datenbankmodul, das einen Server verwendet, kann in einigen Fällen einen besseren Schutz vor Fehlern in der Clientanwendung bieten als eine serverlose Datenbank wie SQLite. Beispielsweise können verirrte Zeiger in einem Client den Speicher auf dem Server nicht beschädigen. Da es sich bei einem Server um einen einzelnen persistenten Prozess handelt, kann eine Client-Server-Datenbank den Datenzugriff präziser steuern als eine serverlose Datenbank, wodurch feinere Sperren und eine bessere Parallelität ermöglicht werden.
Verwendung von SQLite
- Eingebettete Anwendungen: SQLite ist eine großartige Datenbank für Anwendungen, die Portabilität benötigen und keine zukünftige Erweiterung erfordern. Beispiele hierfür sind lokale Single-User-Anwendungen und mobile Anwendungen oder Spiele.
- Datenträgerzugriffsersatz: In Fällen, in denen eine Anwendung Dateien direkt auf die Festplatte lesen und schreiben muss, kann es vorteilhaft sein, SQLite für die zusätzliche Funktionalität und Einfachheit zu verwenden, die mit der Verwendung von SQL einhergeht.
- Testen: Für viele Anwendungen kann es übertrieben sein, ihre Funktionalität mit einem DBMS zu testen, das einen zusätzlichen Serverprozess verwendet. SQLite verfügt über einen In-Memory-Modus, mit dem Tests schnell und ohne den Aufwand für tatsächliche Datenbankoperationen ausgeführt werden können.
Wenn SQLite nicht verwendet wird
- Arbeiten mit vielen Daten: SQLite kann technisch eine Datenbank mit einer Größe von bis zu 140 TB unterstützen, sofern das Laufwerk und das Dateisystem auch die Größenanforderungen der Datenbank unterstützen. Die SQLite-Website empfiehlt jedoch, dass jede Datenbank, die sich 1 TB nähert, in einer zentralen Client-Server-Datenbank gespeichert wird, da eine SQLite-Datenbank dieser Größe oder größer schwierig zu verwalten wäre.
- Hohe Schreibvolumina: SQLite erlaubt nur eine Schreiboperation zu einem bestimmten Zeitpunkt, was den Durchsatz erheblich einschränkt. Wenn Ihre Anwendung viele Schreibvorgänge oder mehrere gleichzeitige Writer erfordert, ist SQLite möglicherweise nicht für Ihre Anforderungen geeignet.
- Netzwerkzugriff erforderlich: Da SQLite eine serverlose Datenbank ist, bietet es keinen direkten Netzwerkzugriff auf seine Daten. Wenn sich die Daten in SQLite also auf einem von der Anwendung separaten Computer befinden, ist eine Engine-to-Disk-Verbindung mit hoher Bandbreite über das Netzwerk erforderlich. Dies ist eine teure, ineffiziente Lösung, und in solchen Fällen kann ein Client-Server-DBMS die bessere Wahl sein.
MySQL
Laut dem DB-Engines-Ranking ist MySQL das beliebteste Open-Source-RDBMS, seit die Site 2012 begonnen hat, die Popularität von Datenbanken zu verfolgen. Es ist ein funktionsreiches Produkt, das viele der weltweit größten Websites und Anwendungen unterstützt, darunter Twitter, Facebook, Netflix und Spotify. Der Einstieg in MySQL ist relativ einfach, was zum großen Teil der umfassenden Dokumentation und der großen Entwicklergemeinschaft sowie der Fülle an MySQL-bezogenen Online-Ressourcen zu verdanken ist.
MySQL wurde für Geschwindigkeit und Zuverlässigkeit auf Kosten der vollständigen Einhaltung von Standard-SQL entwickelt. Die MySQL-Entwickler arbeiten kontinuierlich an einer engeren Einhaltung von Standard-SQL, aber es bleibt immer noch hinter anderen SQL-Implementierungen zurück. Es verfügt jedoch über verschiedene SQL-Modi und -Erweiterungen, die es der Compliance näher bringen. Im Gegensatz zu Anwendungen, die SQLite verwenden, greifen Anwendungen, die eine MySQL-Datenbank verwenden, über einen separaten Daemon-Prozess darauf zu. Da der Serverprozess zwischen der Datenbank und anderen Anwendungen steht, ermöglicht er eine bessere Kontrolle darüber, wer Zugriff auf die Datenbank hat.
MySQL hat eine Fülle von Anwendungen, Tools und integrierten Bibliotheken von Drittanbietern inspiriert, die seine Funktionalität erweitern und die Arbeit erleichtern. Einige der am weitesten verbreiteten Tools dieser Drittanbieter sind phpMyAdmin, DBeaver und HeidiSQL.
MySQL’s Supported Data Types
MySQL’s data types can be organized into three broad categories: numeric types, date and time types, and string types.
Numerische Typen:
| Datentyp | Erklärung |
|---|---|
tinyint |
Eine sehr kleine ganze Zahl. Der vorzeichenbehaftete Bereich für diesen numerischen Datentyp beträgt -128 bis 127, während der vorzeichenlose Bereich 0 bis 255 beträgt. |
smallint |
Eine kleine ganze Zahl. Der vorzeichenbehaftete Bereich für diesen numerischen Typ beträgt -32768 bis 32767, während der vorzeichenlose Bereich 0 bis 65535 beträgt. |
mediumint |
Eine mittlere Ganzzahl. Der vorzeichenbehaftete Bereich für diesen numerischen Datentyp beträgt -8388608 bis 8388607, während der vorzeichenlose Bereich 0 bis 16777215 beträgt. |
int oder integer |
Eine Ganzzahl normaler Größe. Der vorzeichenbehaftete Bereich für diesen numerischen Datentyp beträgt -2147483648 bis 2147483647, während der vorzeichenlose Bereich 0 bis 4294967295 beträgt. |
bigint |
Eine große ganze Zahl. Der vorzeichenbehaftete Bereich für diesen numerischen Datentyp beträgt -9223372036854775808 bis 9223372036854775807, während der vorzeichenlose Bereich 0 bis 18446744073709551615 beträgt. |
float |
Eine kleine Gleitkommazahl mit einfacher Genauigkeit. |
doubledouble precision oder real |
Eine Gleitkommazahl normaler Größe (mit doppelter Genauigkeit). |
decdecimalfixed oder numeric |
Eine gepackte Festkommazahl. Die Anzeigelänge von Einträgen für diesen Datentyp wird beim Erstellen der Spalte definiert, und jeder Eintrag hält sich an diese Länge. |
bool oder boolean |
Ein Boolescher Wert ist ein Datentyp, der nur zwei mögliche Werte hat, normalerweise entweder true oder false. |
bit |
Ein Bitwerttyp, für den Sie die Anzahl der Bits pro Wert von 1 bis 64 angeben können. |
Datums- und Uhrzeittypen:
| Data Type | Explanation |
|---|---|
date |
A date, represented as YYYY-MM-DD. |
datetime |
A timestamp showing the date and time, displayed as YYYY-MM-DD HH:MM:SS. |
timestamp |
A timestamp indicating the amount of time since the Unix epoch (00:00:00 on January 1, 1970). |
time |
A time of day, displayed as HH:MM:SS. |
year |
A year expressed in either a 2 or 4 digit format, with 4 digits being the default. |
String types:
| Data Type | Explanation |
|---|---|
char |
A fixed-length string; Einträge dieses Typs werden rechts mit Leerzeichen aufgefüllt, um die angegebene Länge beim Speichern zu erfüllen. |
varchar |
Ein String variabler Länge. |
binary |
Ähnlich dem Typ char, jedoch eine binäre Bytezeichenfolge einer bestimmten Länge anstelle einer nicht binären Zeichenfolge. |
varbinary |
Ähnlich dem Typ varchar, jedoch eine binäre Bytezeichenfolge variabler Länge anstelle einer nicht binären Zeichenfolge. |
blob |
A binary string with a maximum length of 65535 (2^16 – 1) bytes of data. |
tinyblob |
A blob column with a maximum length of 255 (2^8 – 1) bytes of data. |
mediumblob |
A blob column with a maximum length of 16777215 (2^24 – 1) bytes of data. |
longblob |
A blob column with a maximum length of 4294967295 (2^32 – 1) bytes of data. |
text |
A string with a maximum length of 65535 (2^16 – 1) characters. |
tinytext |
A text column with a maximum length of 255 (2^8 – 1) characters. |
mediumtext |
A text column with a maximum length of 16777215 (2^24 – 1) characters. |
longtext |
A text column with a maximum length of 4294967295 (2^32 – 1) characters. |
enum |
Eine Enumeration, bei der es sich um ein String-Objekt handelt, das einen einzelnen Wert aus einer Liste von Werten übernimmt, die beim Erstellen der Tabelle deklariert werden. |
set |
Ähnlich einer Enumeration ein String-Objekt, das null oder mehr Werte haben kann, von denen jeder aus einer Liste zulässiger Werte ausgewählt werden muss, die beim Erstellen der Tabelle angegeben werden. |
Vorteile von MySQL
- Beliebtheit und Benutzerfreundlichkeit: Als eines der beliebtesten Datenbanksysteme der Welt mangelt es nicht an Datenbankadministratoren, die Erfahrung mit MySQL haben. Ebenso gibt es eine Fülle von Dokumentationen in gedruckter Form und online zur Installation und Verwaltung einer MySQL-Datenbank sowie eine Reihe von Tools von Drittanbietern — wie phpMyAdmin —, die den Einstieg in die Datenbank vereinfachen sollen.
- Sicherheit: MySQL wird mit einem Skript geliefert, mit dem Sie die Sicherheit Ihrer Datenbank verbessern können, indem Sie die Kennwortsicherheitsstufe der Installation festlegen, ein Kennwort für den Root-Benutzer definieren, anonyme Konten entfernen und Testdatenbanken entfernen, auf die standardmäßig alle Benutzer zugreifen können. Im Gegensatz zu SQLite unterstützt MySQL auch die Benutzerverwaltung und ermöglicht es Ihnen, Zugriffsrechte von Benutzer zu Benutzer zu erteilen.
- Geschwindigkeit: Durch die Entscheidung, bestimmte Funktionen von SQL nicht zu implementieren, konnten die MySQL-Entwickler die Geschwindigkeit priorisieren. Während neuere Benchmark-Tests zeigen, dass andere RDBMS wie PostgreSQL MySQL in Bezug auf die Geschwindigkeit entsprechen oder zumindest nahe kommen können, hat MySQL immer noch den Ruf einer äußerst schnellen Datenbanklösung.
- Replikation: MySQL unterstützt eine Reihe verschiedener Arten der Replikation, d. h. den Austausch von Informationen über zwei oder mehr Hosts, um die Zuverlässigkeit, Verfügbarkeit und Fehlertoleranz zu verbessern. Dies ist hilfreich, wenn Sie eine Datenbanksicherungslösung einrichten oder die Datenbank horizontal skalieren möchten.
Nachteile von MySQL
- Bekannte Einschränkungen: Da MySQL eher auf Geschwindigkeit und Benutzerfreundlichkeit als auf vollständige SQL-Konformität ausgelegt ist, weist es bestimmte funktionale Einschränkungen auf. Zum Beispiel fehlt die Unterstützung für
FULL JOINKlauseln. - Lizenzierung und proprietäre Funktionen: MySQL ist eine doppelt lizenzierte Software mit einer kostenlosen und Open-Source-Community-Edition, die unter der GPLv2 lizenziert ist, und mehreren kostenpflichtigen kommerziellen Editionen, die unter proprietären Lizenzen veröffentlicht werden. Aus diesem Grund sind einige Funktionen und Plugins nur für die proprietären Editionen verfügbar.
- Verlangsamte Entwicklung: Seit der Übernahme des MySQL-Projekts durch Sun Microsystems im Jahr 2008 und später durch die Oracle Corporation im Jahr 2009 gab es Beschwerden von Benutzern, dass sich der Entwicklungsprozess für das DBMS erheblich verlangsamt hat, da die Community nicht mehr über die Agentur verfügt, um schnell auf Probleme zu reagieren und Änderungen umzusetzen.
Wann MySQL zu verwenden ist
- Verteilte Operationen: Die Replikationsunterstützung von MySQL macht es zu einer guten Wahl für verteilte Datenbank-Setups wie Primär-Sekundär- oder Primär-Primär-Architekturen.
- Websites und Webanwendungen: MySQL unterstützt viele Websites und Anwendungen im Internet. Dies liegt zum großen Teil daran, wie einfach es ist, eine MySQL-Datenbank zu installieren und einzurichten, sowie an der Gesamtgeschwindigkeit und Skalierbarkeit auf lange Sicht.
- Erwartetes zukünftiges Wachstum: Die Replikationsunterstützung von MySQL kann die horizontale Skalierung erleichtern. Darüber hinaus ist es ein relativ einfacher Prozess, ein Upgrade auf ein kommerzielles MySQL-Produkt wie MySQL Cluster durchzuführen, das automatisches Sharding unterstützt, einen weiteren horizontalen Skalierungsprozess.
Wenn MySQL nicht verwendet werden soll
- SQL-Konformität ist erforderlich: Da MySQL nicht versucht, den vollständigen SQL-Standard zu implementieren, ist dieses Tool nicht vollständig SQL-kompatibel. Wenn eine vollständige oder sogar nahezu vollständige SQL-Compliance für Ihren Anwendungsfall ein Muss ist, möchten Sie möglicherweise ein vollständig kompatibles DBMS verwenden.
- Parallelität und große Datenmengen: Obwohl MySQL im Allgemeinen gut mit leseintensiven Operationen abschneidet, können gleichzeitige Lese- und Schreibvorgänge problematisch sein. Wenn in Ihrer Anwendung viele Benutzer gleichzeitig Daten schreiben, ist ein anderes RDBMS wie PostgreSQL möglicherweise die bessere Datenbankwahl.
PostgreSQL
PostgreSQL, auch bekannt als Postgres, bezeichnet sich selbst als „die fortschrittlichste relationale Open-Source-Datenbank der Welt.“ Es wurde mit dem Ziel entwickelt, hochgradig erweiterbar und standardkonform zu sein. PostgreSQL ist eine objektrelationale Datenbank, was bedeutet, dass es sich zwar in erster Linie um eine relationale Datenbank handelt, aber auch Funktionen wie Tabellenvererbung und Funktionsüberladung enthält, die häufiger mit Objektdatenbanken verknüpft sind.
Postgres ist in der Lage, mehrere Aufgaben gleichzeitig effizient zu bearbeiten, ein Merkmal, das als Parallelität bezeichnet wird. Es erreicht dies ohne Lesesperren dank seiner Implementierung von Multiversion Concurrency Control (MVCC), die die Atomizität, Konsistenz, Isolation und Haltbarkeit seiner Transaktionen, auch bekannt als ACID-Compliance, gewährleistet.
PostgreSQL ist nicht so weit verbreitet wie MySQL, aber es gibt immer noch eine Reihe von Tools und Bibliotheken von Drittanbietern, die die Arbeit mit PostgreSQL vereinfachen sollen, darunter pgAdmin und Postbird.
Unterstützte Datentypen von PostgreSQL
PostgreSQL unterstützt numerische, String- sowie Datums- und Uhrzeitdatentypen wie MySQL. Darüber hinaus unterstützt es Datentypen für geometrische Formen, Netzwerkadressen, Bitstrings, Textsuchen und JSON-Einträge sowie mehrere idiosynkratische Datentypen.
Numerische Typen:
| Datentyp | Erklärung |
|---|---|
bigint |
Eine vorzeichenbehaftete 8-Byte-Ganzzahl. |
bigserial |
An autoincrementing 8 byte integer. |
double precision |
An 8 byte double precision floating-point number. |
integer |
A signed 4 byte integer. |
numeric or decimal |
An number of selectable precision, recommended for use in cases where exactness is crucial, such as monetary amounts. |
real |
A 4 byte single precision floating-point number. |
smallint |
A signed 2 byte integer. |
smallserial |
An autoincrementing 2 byte integer. |
serial |
An autoincrementing 4 byte integer. |
Character types:
| Data Type | Explanation |
|---|---|
character |
A character string with a specified fixed length. |
character varying or varchar |
A character string with a variable but limited length. |
text |
A character string of a variable, unlimited length. |
Date and time types:
| Data Type | Explanation |
|---|---|
date |
A calendar date consisting of the day, month, and year. |
interval |
A time span. |
time or time without time zone |
A time of day, not including the time zone. |
time with time zone |
A time of day, including the time zone. |
timestamp or timestamp without time zone |
A date and time, not including the time zone. |
timestamp with time zone |
A date and time, including the time zone. |
Geometric types:
| Data Type | Explanation |
|---|---|
box |
A rectangular box on a plane. |
circle |
A circle on a plane. |
line |
An infinite line on a plane. |
lseg |
A line segment on a plane. |
path |
A geometric path on a plane. |
point |
A geometric point on a plane. |
polygon |
A closed geometric path on a plane. |
Network address types:
| Data Type | Explanation |
|---|---|
cidr |
An IPv4 or IPv6 network address. |
inet |
An IPv4 or IPv6 host address. |
macaddr |
A Media Access Control (MAC) address. |
Bit string types:
| Data Type | Explanation |
|---|---|
bit |
A fixed-length bit string. |
bit varying |
A variable-length bit string. |
Text search types:
| Data Type | Explanation |
|---|---|
tsquery |
A text search query. |
tsvector |
A text search document. |
JSON types:
| Data Type | Explanation |
|---|---|
json |
Textual JSON data. |
jsonb |
Decomposed binary JSON data. |
Other data types:
| Data Type | Explanation |
|---|---|
boolean |
A logical Boolean, representing either true or false. |
bytea |
Short for „byte array”, this type is used for binary data. |
money |
An amount of currency. |
pg_lsn |
A PostgreSQL Log Sequence Number. |
txid_snapshot |
A user-level transaction ID snapshot. |
uuid |
A universally unique identifier. |
xml |
XML data. |
Advantages of PostgreSQL
- SQL compliance: More so than SQLite or MySQL, PostgreSQL aims to closely adhere to SQL standards. According to the official PostgreSQL documentation, PostgreSQL supports 160 out of the 179 features required for full core SQL:2011 Compliance, zusätzlich zu einer langen Liste von optionalen Funktionen.
- Open-Source und Community-driven: Als vollständig Open-Source-Projekt wird der Quellcode von PostgreSQL von einer großen und engagierten Community entwickelt. In ähnlicher Weise unterhält und unterstützt die Postgres-Community zahlreiche Online-Ressourcen, die die Arbeit mit dem DBMS beschreiben, einschließlich der offiziellen Dokumentation, des PostgreSQL-Wikis und verschiedener Online-Foren.Erweiterbar: Benutzer können PostgreSQL programmgesteuert und im laufenden Betrieb durch seinen kataloggesteuerten Betrieb und die Verwendung von dynamischem Laden erweitern. Man kann eine Objektcodedatei wie eine gemeinsam genutzte Bibliothek festlegen, und PostgreSQL lädt sie nach Bedarf.
Nachteile von PostgreSQL
- Speicherperformance: Für jede neue Clientverbindung forkt PostgreSQL einen neuen Prozess. Jedem neuen Prozess werden etwa 10 MB Arbeitsspeicher zugewiesen, was sich bei Datenbanken mit vielen Verbindungen schnell summieren kann. Dementsprechend ist PostgreSQL für einfache Lesevorgänge normalerweise weniger performant als andere RDBMS wie MySQL.
- Beliebtheit: Obwohl PostgreSQL in den letzten Jahren häufiger verwendet wurde, blieb es in Bezug auf die Popularität historisch hinter MySQL zurück. Eine Folge davon ist, dass es immer noch weniger Tools von Drittanbietern gibt, die bei der Verwaltung einer PostgreSQL-Datenbank helfen können. Ebenso gibt es nicht so viele Datenbankadministratoren mit Erfahrung in der Verwaltung einer Postgres-Datenbank wie solche mit MySQL-Erfahrung.
Verwendung von PostgreSQL
- Datenintegrität ist wichtig: PostgreSQL ist seit 2001 vollständig ACID-konform und implementiert Multiversion Currency Control, um sicherzustellen, dass die Daten konsistent bleiben.
- Integration mit anderen Tools: PostgreSQL ist mit einer Vielzahl von Programmiersprachen und Plattformen kompatibel. Das heißt, wenn Sie Ihre Datenbank jemals auf ein anderes Betriebssystem migrieren oder in ein bestimmtes Tool integrieren müssen, ist dies mit einer PostgreSQL-Datenbank wahrscheinlich einfacher als mit einem anderen DBMS.
- Komplexe Operationen: Postgres unterstützt Abfragepläne, die mehrere CPUs nutzen können, um Abfragen schneller zu beantworten. Dies, gepaart mit seiner starken Unterstützung für mehrere gleichzeitige Autoren, macht es zu einer guten Wahl für komplexe Vorgänge wie Data Warehousing und Online-Transaktionsverarbeitung.
Wenn Sie PostgreSQL nicht verwenden
- Geschwindigkeit ist unerlässlich: Auf Kosten der Geschwindigkeit wurde PostgreSQL mit Blick auf Erweiterbarkeit und Kompatibilität entwickelt. Wenn Ihr Projekt die schnellstmöglichen Lesevorgänge erfordert, ist PostgreSQL möglicherweise nicht die beste Wahl für DBMS.
- Einfache Einstellungen: Aufgrund seines großen Funktionsumfangs und der starken Einhaltung von Standard-SQL kann Postgres für einfache Datenbank-Setups übertrieben sein. Für leseintensive Operationen, bei denen Geschwindigkeit erforderlich ist, ist MySQL normalerweise eine praktischere Wahl.Komplexe Replikation: Obwohl PostgreSQL eine starke Unterstützung für die Replikation bietet, ist es immer noch ein relativ neues Feature und einige Konfigurationen — wie eine Primär-Primär—Architektur – sind nur mit Erweiterungen möglich. Die Replikation ist eine ausgereiftere Funktion von MySQL, und viele Benutzer sehen die Replikation von MySQL als einfacher zu implementieren an, insbesondere für diejenigen, denen die erforderliche Datenbank- und Systemadministrationserfahrung fehlt.
Fazit
Heute sind SQLite, MySQL und PostgreSQL die drei beliebtesten relationalen Open-Source-Datenbankmanagementsysteme der Welt. Jedes hat seine eigenen einzigartigen Funktionen und Einschränkungen und zeichnet sich in bestimmten Szenarien aus. Bei der Entscheidung für ein RDBMS spielen einige Variablen eine Rolle, und die Auswahl ist selten so einfach wie die Auswahl des schnellsten oder des mit den meisten Funktionen. Wenn Sie das nächste Mal eine relationale Datenbanklösung benötigen, sollten Sie diese und andere Tools eingehend untersuchen, um das zu finden, das Ihren Anforderungen am besten entspricht.
Wenn Sie mehr über SQL und seine Verwendung zum Verwalten einer relationalen Datenbank erfahren möchten, empfehlen wir Ihnen, sich auf unser Spickzettel zum Verwalten einer SQL-Datenbank zu beziehen. Wenn Sie andererseits mehr über nicht relationale (oder NoSQL-) Datenbanken erfahren möchten, lesen Sie unseren Vergleich von NoSQL-Datenbankverwaltungssystemen.